题目:
Result文件数据说明:
Ip:106.39.41.166,(城市)
Date:10/Nov/2016:00:01:02 +0800,(日期)
Day:10,(天数)
Traffic: 54 ,(流量)
Type: video,(类型:视频video或文章article)
Id: 8701(视频或者文章的id)
测试要求:
1、 数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中。
两阶段数据清洗:
(1)第一阶段:把需要的信息从原始日志中提取出来
ip: 199.30.25.88
time: 10/Nov/2016:00:01:03 +0800
traffic: 62
文章: article/11325
视频: video/3235
1 2 4 5 6
(2)第二阶段:根据提取出来的信息做精细化操作
ip--->城市 city(IP)
date--> time:2016-11-10 00:01:03
day: 10
traffic:62
type:article/video
id:11325
(3)hive数据库表结构:
create table data( ip string, time string , day string, traffic bigint,
type string, id string )
2、数据处理:
·统计最受欢迎的视频/文章的Top10访问次数 (video/article)
·按照地市统计最受欢迎的Top10课程 (ip)
·按照流量统计最受欢迎的Top10课程 (traffic)
3、数据可视化:将统计结果倒入MySql数据库中,通过图形化展示的方式展现出来。
完成情况:
目前完成了第一步
数据清洗代码:
1 import java.io.IOException; 2 import java.text.SimpleDateFormat; 3 import java.util.Date; 4 import java.util.Locale; 5 6 import org.apache.hadoop.conf.Configuration; 7 import org.apache.hadoop.fs.Path; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Job; 10 import org.apache.hadoop.mapreduce.Mapper; 11 import org.apache.hadoop.mapreduce.Reducer; 12 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 13 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 14 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; 16 import text.te.Map.Reduce; 17 18 19 public class te { 20 21 public static class Map extends Mapper<Object,Text,Text,Text>{ 22 public static final SimpleDateFormat FORMAT = new SimpleDateFormat("d/MMM/yyyy:HH:mm:ss", Locale.ENGLISH); //原时间格式 23 public static final SimpleDateFormat dateformat1 = new SimpleDateFormat("yyyy-MM-dd-HH:mm:ss");//现时间格式 24 private static Date parseDateFormat(String string) { //转换时间格式 25 Date parse = null; 26 try { 27 parse = FORMAT.parse(string); 28 } catch (Exception e) { 29 e.printStackTrace(); 30 } 31 return parse; 32 } 33 private static Text newKey = new Text(); 34 private static Text newvalue = new Text(); 35 public void map(Object key,Text value,Context context) throws IOException, InterruptedException{ 36 String line = value.toString(); 37 System.out.println(line); 38 String arr[] = line.split(","); 39 newKey.set(arr[0]); 40 final int first = arr[1].indexOf(""); 41 final int last = arr[1].indexOf(" +0800"); 42 String time = arr[1].substring(first + 1, last).trim(); 43 Date date = parseDateFormat(time); 44 arr[1] = dateformat1.format(date); 45 newvalue.set(arr[1]+" "+arr[2]+" "+arr[3]+" "+arr[4]+" "+arr[5]); 46 context.write(newKey,newvalue); 47 } 48 49 public static class Reduce extends Reducer<Text, Text, Text, Text> { 50 protected void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException { 51 for(Text text : values){ 52 context.write(key,text); 53 } 54 } 55 } 56 } 57 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 58 Configuration conf = new Configuration(); 59 System.out.println("start"); 60 Job job=Job.getInstance(conf); 61 job.setJobName("filter"); 62 job.setJarByClass(te.class); 63 job.setMapperClass(Map.class); 64 job.setReducerClass(Reduce.class); 65 job.setOutputKeyClass(Text.class); 66 job.setOutputValueClass(Text.class); 67 job.setInputFormatClass(TextInputFormat.class); 68 job.setOutputFormatClass(TextOutputFormat.class); 69 Path in=new Path("hdfs://localhost:9000/text/in/result"); 70 Path out=new Path("hdfs://localhost:9000/text/out"); 71 FileInputFormat.addInputPath(job, in); 72 FileOutputFormat.setOutputPath(job, out); 73 boolean flag = job.waitForCompletion(true); 74 System.out.println(flag); 75 System.exit(flag? 0 : 1); 76 } 77 }
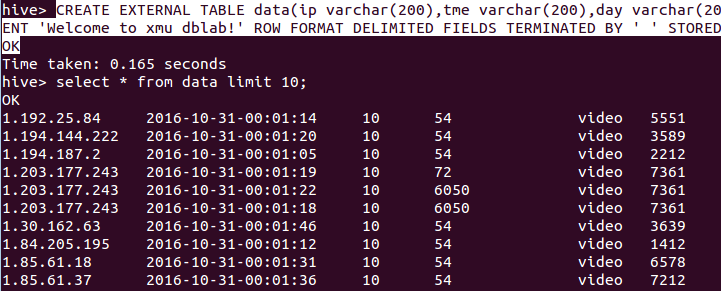
导入hive语句:
CREATE EXTERNAL TABLE data(ip varchar(200),tme varchar(200),day varchar(200),traffic varchar(200),type varchar(200),id varchar(200)) COMMENT 'Welcome to xmu dblab!' ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/bigdatacase/dataset'; OK
结果截图: