第一章:
知识点归纳以及自己最有收获的内容:
LInux与Unix的区别:
UNIX 系统大多是与硬件配套的,也就是说,大多数 UNIX 系统如 AIX、HP-UX 等是无法安装在 x86 服务器和个人计算机上的,而 Linux 则可以运行在多种硬件平台上;
UNIX 是商业软件,而 Linux 是开源软件,是免费、公开源代码的。
Linux 受至旷大计算机爱好者的喜爱,主要原因也有两个:
它属于开源软件,用户不用支付可费用就可以获得它和它的源代码,并且可以根据自己的需要对它进行必要的修改,无偿使用,无约束地继续传播;
它具有 UNIX 的全部功能,任何使用 UNIX 操作系统或想要学习 UNIX 操作系统的人都可以从 Linux 中获益。
开源软件是不同于商业软件的一种模式,从字面上理解,就是开放源代码,大家不用担心里面会搞什么猫腻,这会带来软件的革新和安全。
另外,开源其实并不等同于免费,而是一种新的软件盈利模式。目前很多软件都是开源软件,对计算机行业与互联网影响深远。
近年来,Linux 已经青出于蓝而胜于蓝,以超常的速度发展,从一个丑小鸭变成了一个拥有庞大用户群的真正优秀的、值得信赖的操作系统。历史的车轮让 Linux 成为 UNIX 最优秀的传承者。
Lnux内核与Unix内核的显著差异:
- LInux支持动态加载内核模块
- Linux支持对称多处理(SMP)机制
- Linux内核可抢占
- Linux对线程的实现有些小特别——内核并不区分线程和其他的一般进程
- Linux提供具有设备类的面向对象的设备模型,热插拔事件,以及用户空间的设备文件系统
- Linux忽略了一些被认为是设计的很拙劣的Unix特性
- Linux体现了自由
UNIX/Linux系统结构
UNIX/Linux 系统可以粗糙地抽象为 3 个层次(所谓粗糙,就是不够细致、精准,但是便于初学者抓住重点理解)。
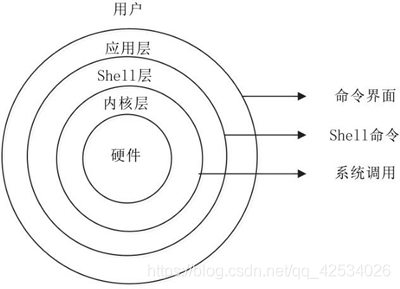
底层是 UNIX/Linux 操作系统,即系统内核(Kernel);中间层是 Shell 层,即命令解释层;高层则是应用层。
- 内核层
内核层是 UNIX/Linux 系统的核心和基础,它直接附着在硬件平台之上,控制和管理系统内各种资源(硬件资源和软件资源),有效地组织进程的运行,从而扩展硬件的功能,提高资源的利用效率,为用户提供方便、高效、安全、可靠的应用环境。 - Shell层
Shell 层是与用户直接交互的界面。用户可以在提示符下输入命令行,由 Shell 解释执行并输出相应结果或者有关信息,所以我们也把 Shell 称作命令解释器,利用系统提供的丰富命令可以快捷而简便地完成许多工作。 - 应用层
应用层提供基于 X Window 协议的图形环境。X Window 协议定义了一个系统所必须具备的功能(就如同 TCP/IP 是一个协议,定义软件所应具备的功能),可系统能满足此协议及符合 X 协会其他的规范,便可称为 X Window。
Linux手册页:
Linux将在线手册页保存在标准目录下,在Ubuntu Linux中,手册页保存在usr/share/man目录下,手册页用man1,man2表示
- man1:常用命令
- man2:系统调用
- man3:库函数
只要掌握如何利用这些手册页,即可了解绝大多数的Linux命令
问题与解决思路
将Ubuntu安装到VMware虚拟机上:
课本中给出的步骤里有一步将Ubuntu映像刻录成DVD光盘,显然较难实现且不是最优选择,通过上网查阅安装教程了解到,映像文件可直接在官网下载,在设置CD/DVD(STAT)中,在右边选择使用ISO映像文件,将路径选择到已下载映像的路径即可

修改Ubuntu密码:
在开启Ubuntu时发现之前的密码忘记了,书中提到出于安全原因,用户都为普通用户,无法直接更改密码,必须获得根权限
修改密码方法:

第二章:
重难点知识思维导图
链表创建为什么需要使用内存分配?为什么要使用动态内存分配?
查阅资料知道:直接在全局定义的结构体,存储在静态存储区;在函数内定义的结构体,存储在栈区;
而使用malloc来申请空间的结构体,存储在堆空间中。链表一般都放在堆空间中。
并且指向结构体的指针由于结构体里面的基本类型的种类和数量不确定才动态分配的,内存越多,地址越长,指针占用的字节就越多。
而且,想要在全局使用链表,就必须动态分配内存,静态分配的话,是无法再拓展的
练习代码链接:
https://gitee.com/zhang_yu_peng/practice-code/blob/master/new 2