数据类型(数字、字符串)
Python的数据类型分为:数字、字符串、列表、元组、字典、集合
1、数字
定义:a=1
特性:
1.只能存放一个值
2.一经定义,不可更改
3.直接访问
分类:整型,长整型,布尔,浮点,复数
1.1整形
Python的整型相当于C中的long型,Python中的整数可以用十进制,八进制,十六进制表示。

>>> 10 10 --------->默认十进制 >>> oct(10) '012' --------->八进制表示整数时,数值前面要加上一个前缀“0” >>> hex(10) '0xa' --------->十六进制表示整数时,数字前面要加上前缀0X或0x
python2.*与python3.*关于整型的区别
python2.*
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
python3.*整形长度无限制
1.2长整形long:
python2.*:
跟C语言不同,Python的长整型没有指定位宽,也就是说Python没有限制长整型数值的大小,但是实际上由于机器内存有限,所以我们使用的长整型数值不可能无限大。
在使用过程中,我们如何区分长整型和整型数值呢?
通常的做法是在数字尾部加上一个大写字母L或小写字母l以表示该整数是长整型的,例如:
a = 9223372036854775808L
注意,自从Python2起,如果发生溢出,Python会自动将整型数据转换为长整型,
所以如今在长整型数据后面不加字母L也不会导致严重后果了。
python3.*
长整型,整型统一归为整型
1.3布尔bool:
True 和 False
1 和 0
1.4浮点数float:
Python的浮点数就是数学中的小数,类似C语言中的double。
在运算中,整数与浮点数运算的结果是浮点数
浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,
一个浮点数的小数点位置是可变的,比如,1.23*109和12.3*108是相等的。
浮点数可以用数学写法,如1.23,3.14,-9.01,等等。但是对于很大或很小的浮点数,
就必须用科学计数法表示,把10用e替代,1.23*109就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。
整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的而浮点数运算则可能会有四舍五入的误差。
1.5复数complex:
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
注意,虚数部分的字母j大小写都可以。
>>> 1.3 + 2.5j == 1.3 + 2.5J True
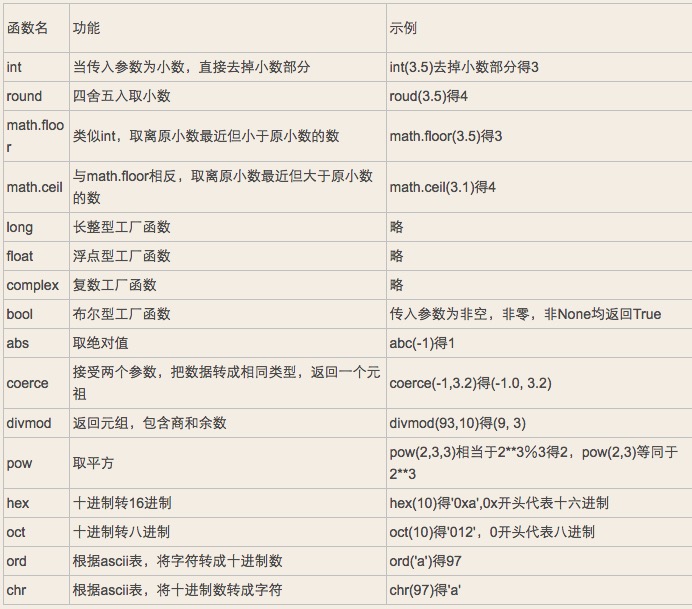
1.6数字相关内建函数
2、字符串
定义:它是一个有序的字符的集合,用于存储和表示基本的文本信息,‘’或“”或‘’‘ ’‘’中间包含的内容称之为字符串
特性:
1.只能存放一个值
2.不可变
3.按照从左到右的顺序定义字符集合,下标从0开始顺序访问,有序
补充:
1.字符串的单引号和双引号都无法取消特殊字符的含义,如果想让引号内所有字符均取消特殊意义,在引号前面加r,如name=r'l hf'
2.unicode字符串与r连用必需在r前面,如name=ur'l hf'
2.1字符串创建
'hello world'
2.2字符串的常用操作
res='hello world '
移除空白
res='hello world ' print(res.strip()) hello world #移除字符串后面的空白
分割
print(res.split()) ['hello', 'world']
长度
res='hello world ' print(len(res)) 17
索引
res='hello world ' print(res[4]) o
切片
res='hello world ' print(res[1:4]) ell
2.3有关自建函数
字符串中的搜索和替换:
S.find(substr, [start, [end]]) #返回S中出现substr的第一个字母的标号,如果S中没有substr则返回-1。start和end作用就相当于在S[start:end]中搜索
S.index(substr, [start, [end]]) #与find()相同,只是在S中没有substr时,会返回一个运行时错误
S.rfind(substr, [start, [end]]) #返回S中最后出现的substr的第一个字母的标号,如果S中没有substr则返回-1,也就是说从右边算起的第一次出现的substr的首字母标号
S.rindex(substr, [start, [end]])
S.count(substr, [start, [end]]) #计算substr在S中出现的次数
S.replace(oldstr, newstr, [count]) #把S中的oldstr替换为newstr,count为替换次数。这是替换的通用形式,还有一些函数进行特殊字符的替换
S.strip([chars]) #把S中前后chars中有的字符全部去掉,可以理解为把S前后chars替换为None
注:可用于判断字符串是否为空,字符串为空返回False,不为空时返回Ture。
S.lstrip([chars]) #把S中前chars中有的字符去掉
S.rstrip([chars]) #把S中后chars中有的字符全部去掉
S.expandtabs([tabsize]) #把S中的tab字符替换没空格,每个tab替换为tabsize个空格,默认是8个
字符串的分割和组合:
S.split([sep, [maxsplit]]) #以sep为分隔符,把S分成一个list。maxsplit表示分割的次数。默认的分割符为空白字符
S.rsplit([sep, [maxsplit]])
S.splitlines([keepends]) #把S按照行分割符分为一个list,keepends是一个bool值,如果为真每行后而会保留行分割符。
S.join(seq) #把seq代表的序列──字符串序列,用S连接起来
字符串的mapping,这一功能包含两个函数:
String.maketrans(from, to) #返回一个256个字符组成的翻译表,其中from中的字符被一一对应地转换成to,所以from和to必须是等长的。
S.translate(table[,deletechars]) # 使用上面的函数产后的翻译表,把S进行翻译,并把deletechars中有的字符删掉。需要注意的是,如果S为unicode字符串,那么就不支持 deletechars参数,可以使用把某个字符翻译为None的方式实现相同的功能。此外还可以使用codecs模块的功能来创建更加功能强大的翻译 表。
字符串中字符大小写的变换:
S.lower() #小写
S.upper() #大写
S.swapcase() #大小写互换
S.capitalize() #首字母大写
String.capwords(S) #这是模块中的方法。它把S用split()函数分开,然后用capitalize()把首字母变成大写,最后用join()合并到一起
S.title() #只有首字母大写,其余为小写,模块中没有这个方法
字符串的测试函数
这些函数返回的都是bool值
S.startwith(prefix[,start[,end]]) #是否以prefix开头
S.endwith(suffix[,start[,end]]) #以suffix结尾
S.isalnum() #是否全是字母和数字,并至少有一个字符
S.isalpha() #是否全是字母,并至少有一个字符
S.isdigit() #是否全是数字,并至少有一个字符
S.isspace() #是否全是空白字符,并至少有一个字符
S.islower() #S中的字母是否全是小写
S.isupper() #S中的字母是否便是大写
S.istitle() #S是否是首字母大写的
字符串在输出时的对齐:
S.ljust(width,[fillchar]) #输出width个字符,S左对齐,不足部分用fillchar填充,默认的为空格。
S.rjust(width,[fillchar]) #右对齐
S.center(width, [fillchar]) #中间对齐
S.zfill(width) #把S变成width长,并在右对齐,不足部分用0补足
格式化字符串:
s='name:{},age:{},sex:{}'
print(s.format('ogen',18,'male','asdasda'))#多余的参数不会影响结果,少参数会报错。