作业①
1)UniversitiesRanking
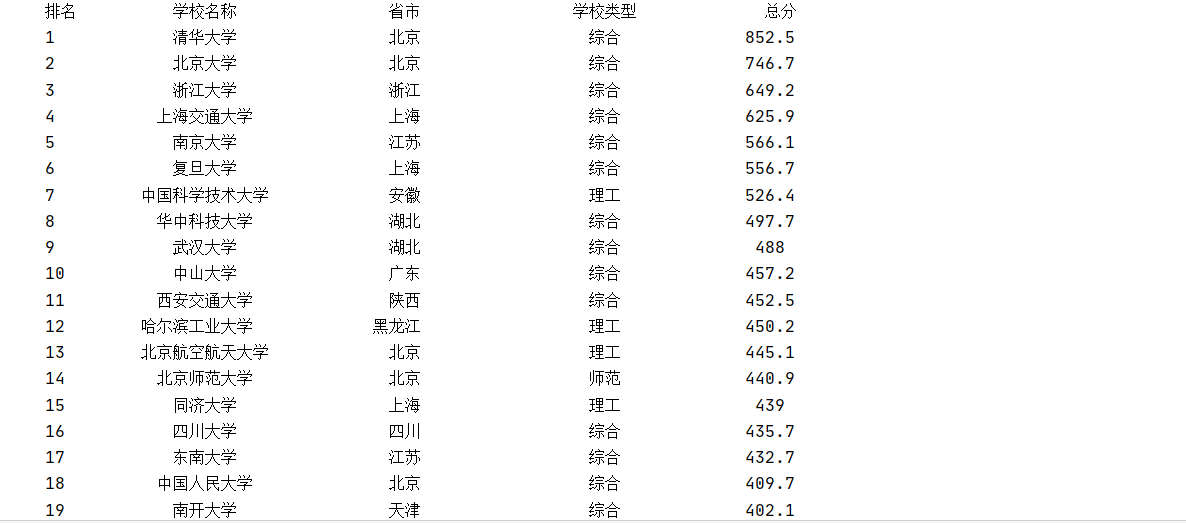
要求:用requests和BeautifulSoup库方法定向爬取给定网址http://www.shanghairanking.cn/rankings/bcur/2020的数据,屏幕打印爬取的大学排名信息。
思路:通过网页源代码可以发现大学的排名信息都在<tbody>...</tbody>标签对里,每一个大学的排名信息又在<tr>...</tr>里,具体的排名,名称等在<td>...</td>中

代码:
import requests
from bs4 import BeautifulSoup
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
resp = requests.get(url)
soup = BeautifulSoup(resp.content.decode("utf-8"), "lxml")
tplt = "{0:^10} {1:{5}^10} {2:{5}^10} {3:{5}^10} {4:^10}"
print(tplt.format("排名", "学校名称", "省市", "学校类型", "总分", chr(12288)))
trs = soup.select("tbody tr") #获取tbody标签下的tr子标签
for tr in trs:
lis = [tr.select('td')[i].text.strip() for i in range(5)] #获取每一个tr标签下的前五个td子标签的文本内容
print(tplt.format(lis[0], lis[1], lis[2], lis[3], lis[4], chr(12288)))
运行结果部分截图:
2)心得体会
对F12和Beautifulsoup的使用有了初步了解
作业②
2)GoodsPrices
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
思路:查看网页源代码可以发现商品的信息在<ul>...</ul>标签中,每件商品的信息对应<li>...</li>标签,具体的属性在<div>...</div>中

代码:
import re
import requests
url = "https://search.jd.com/Search?keyword="+"书包"
i = 0
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36"
}
html = requests.get(url=url, headers=headers).text
tplt = "{0:^10} {1:^10} {2:{3}^10}"
print(tplt.format("序号", "价格", "商品名", chr(12288)))
m = re.search("<ul class="gl-warp clearfix"", html)
html = html[m.end():] #html文档内容直接从正文开始,去掉前面的冗余信息
prices = re.findall("<em>¥</em><i>d+.d+</i>", html) #筛选出价格所在的字符串
names = re.findall("<em>[^¥][sS]*?</em>", html) #筛选出商品名所在的字符串
for i in range(len(prices)):
price = re.findall("d+.d+", prices[i])[0] #获取价格
name = re.sub("<span.*?</span>||<.*?>||s", '', names[i]) #获取商品名
print(tplt.format(i + 1, price, name, chr(12288)))
运行结果部分截图

2)心得体会
尝试给网页请求加入headers,也动手实现了正则表达式(勉强算是吧)
作业③
1)JpgFileDownload
要求:爬取一个给定网页http://xcb.fzu.edu.cn/html/2019ztjy或者自选网页http://xcb.fzu.edu.cn/的所有JPG格式文件
思路:图片的地址各异,分别对应一种表达式,甚至连注释里都出现了(需要去掉注释否则会爬取到相同的图片)


代码:
import re
import requests
import urllib.request
import os
r = requests.get("http://xcb.fzu.edu.cn/")
path = "D:/new file/images1/"
html = re.sub("<!--(.|
)*?-->", "", r.text)
if (not os.path.exists(path)): #判断文件路径是否存在,不存在就创建
os.mkdir(path)
for jpg in re.compile("src=".*.jpg| ".*.jpg", re.I).findall(html): # 图片地址筛选
if (jpg[:3] == "src"): # 判断是否src开头
if (jpg[5:9] == "http"): # 判断是否绝对路径
url = jpg[5:]
else:
url = "http://xcb.fzu.edu.cn" + jpg[5:]
else:
url = "http://xcb.fzu.edu.cn" + jpg[2:]
name = url.split("/")[-1]
f = urllib.request.urlopen(url) # 图片写入文件夹
with open(path + name, "wb") as code:
code.write(f.read())
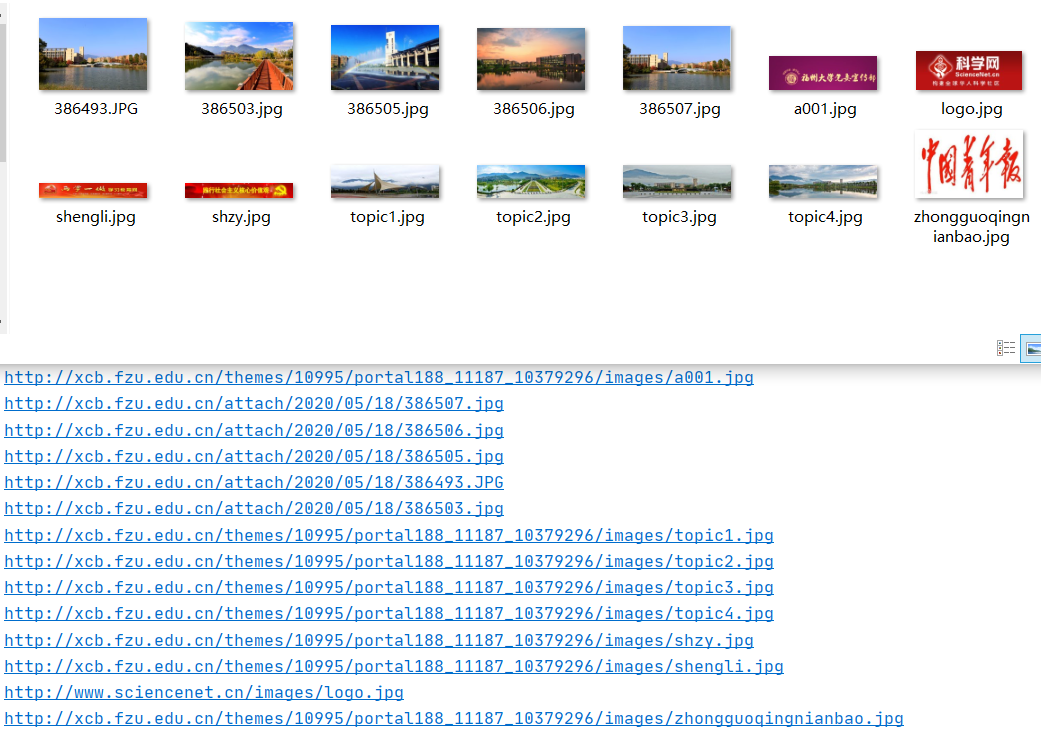
print(url) #输出图片路径
运行结果部分截图
2)心得体会
再次使用到正则表达式,加强了掌握程度,也了解了图片的写入