一、前言
linux 有很多工具可以做文本处理,例如:sort, cut, split, join, paste, comm, uniq, column, rev, tac, tr, nl, pr, head, tail.....,学习 linux 文本处理的懒惰方式(不是最好的方法)可能是:只学习grep,sed和awk。 使用这三个工具,你可以解决近 99% linux 系统的文本处理问题,而不需要记住上面不同的命令和参数。:)
而且,如果你已经学会并使用了三者,你就会知道其中的差异。实际上,这里的差异意味着哪个工具擅长解决什么样的问题。
一种更懒惰的方式可能是学习脚本语言(python,perl或ruby)并使用它进行每个文本处理。
二、概述
awk、grep、sed 是 linux 操作文本的三大利器,也是必须掌握的 linux 命令之一。三者的功能都是处理文本,但侧重点各不相同,其中属 awk 功能最强大,但也最复杂。grep 更适合单纯地查找或匹配文本,sed 更适合编辑匹配到的文本,awk 更适合格式化文本,对文本进行较复杂格式处理。
简单概括:
- grep:数据查找定位
- awk:数据切片
- sed:数据修改
三、grep = global regular expression print
用最简单术语来说,grep(全局正则表达式打印)--命令用于查找文件里符合条件的字符串。 从文件的第一行开始,grep 将一行复制到 buffer 中,将其与搜索字符串进行比较,如果比较通过,则将该行打印到屏幕上。grep将重复这个过程,直到文件搜索所有行。
注意这里没有进程执行 grep 存储行、更改行或仅搜索部分行。
1、示例数据文件
请将以下数据剪切粘贴到一个名为 “sampler.log” 的文件中:
boot
book
booze
machine
boots
bungie
bark
aardvark
broken$tuff
robots2、一个简单例子
grep 最简单的例子是:
grep "boo" sampler.log 在本例中,grep 将遍历文件 “sampler.log” 的每一行,并打印出其中的每一行 包含单词“boo”:
boot
book
booze
boots但是如果你操作的是大型文件,就会出现这种情况:如果这些行标识了文件中的哪一行,它们是什么,可能对你更有用,如果需要在编辑器中打开文件,那么可以更容易地跟踪特定字符串做一些改变。 这时候可以通过添加 -n 参数来实现:
grep -n "boo" sampler.log这产生了一个更有用的结果,解释了哪些行与搜索字符串匹配:
1:boot
2:book
3:booze
5:boots另一个有趣的参数是 -v,它会打印出相反的结果。换句话说,grep 将打印所有与搜索字符串不匹配的行,而不是打印与之匹配的行。
在下列情况下,grep 将打印不包含字符串 “boo” 的每一行,并显示行号,如上一个例子所示
grep -vn "boo" sampler.log
4:machine
6:bungie
7:bark
8:aardvark
9:broken$tuff
10:robotsc 选项告诉 grep 抑制匹配行的打印,只显示匹配行的数量,匹配查询的行。
例如,下面将打印数字4,因为有4个在 sampler.log 中出现 “boo”。
grep -c "boo" sampler.log
4
l 选项只打印查询中具有与搜索匹配行的文件的文件名字符串。 如果你想在多个文件中搜索相同的字符串,这将非常有用。像这样:
grep -l "boo" *对于搜索非代码文件,一个更有用的选项是 -i,忽略大小写。这个选项将处理在匹配搜索字符串时,大小写相等。 在下面的例子中,即使搜索字符串是大写的,包含“boo”的行也会被打印出来。
grep -i "BOO" sampler.log
boot
book
booze
bootsx 选项只精确匹配。换句话说,以下命令搜索没有结果,因为没有一行只包含"boo"
grep -x "boo" sampler.log 最后,-A 允许你指定额外的上下文件行,这样就得到了搜索字符串额外行,例如
grep -A2 "mach" sampler.log
machine
boots
bungie3、正则表达式
正则表达式是描述文本中复杂模式的一种紧凑方式。有了 grep 你可以使用搜索模式( pattern ) 。其他工具使用正则表达式 (regexp) 以复杂的方式。
而 grep 使用的普通字符串,实际上非常简单正则表达式。如果您使用通配符,如 ' * ' 或 ' ? ',比如列出文件名等,你可以使用 grep 使用基本的正则表达式进行搜索 例如搜索文件以字母 e 结尾的行:
grep "e$" sampler.log
booze
machine
bungie如果需要更广泛的正则表达式命令,则必须使用grep -E。 例如,正则表达式命令 ? 将匹配1或0次出现 之前的字符:
grep -E "boots?" sampler.log
boot
boots你还可以使用 pipe(|) 结合多个搜索,它的意思是 “或者”,所以你可以这样做:
grep -E "boot|boots" sampler.log
boot
boots4、特殊字符
如果你想搜索的是一个特殊字符,该怎么办?如果你想找到所有的直线,如果包含美元字符“$”,则不能执行 grep “ $ ” a_file,因为 '$' 将被解释为正则表达式,相反,你将得到所有的行,其中有任何作为行结束,即所有行。 解决方案是 “转义” 符号,所以您将使用
grep '$' sampler.log
broken$tuff你还可以使用 “-F” 选项,它代表“固定字符串”或“快速”,因为它只搜索字符串,而不是正则表达式。
5、更多的 regexp 的例子
参考:
四、AWK
由 Aho,Weinberger 和 Kernighan 创建的文本模式扫描和处理语言。 AWK非常复杂,所以这不是一个完整的指南,但应该给你一个知道什么 awk 可以做。它使用起来比较简单,强烈建议使用。
1、AWK 基础知识
awk 程序对输入文件的每一行进行操作。它可以有一个可选的 BEGIN{ } 部分 在处理文件的任何内容之前执行的命令,然后主{ }部分运行在文件的每一行中,最后还有一个可选的END{ }部分操作将在后面执行文件读取完成:
BEGIN { …. initialization awk commands …}
{ …. awk commands for each line of the file…}
END { …. finalization awk commands …}
对于输入文件的每一行,它会查看是否有任何模式匹配指令,在这种情况下它仅在与该模式匹配的行上运行,否则它在所有行上运行。 这些 'pattern-matching' 命令可以包含与 grep 一样的正则表达式。 a
wk 命令可以做一些非常复杂的数学和字符串操作,awk也支持关联阵列。 AWK 将每条线视为由多个字段组成,每个字段由“间隔符”分隔。 默认情况下,这是一个或多个空格字符,因此行:
this is a line of text包含6个字段。在 awk 中,第一个字段称为 2,等等,全部行称为 $0。 字段分隔符由 awk 内部变量 FS 设置,因此如果您设置 FS= ": "则它将根据 ':' 的位置划分一行,这对于/etc/passwd 之类的文件很有用,其他有用的内部变量是 NR,即当前记录号(即行号) NF是当前行中字段的数量。
AWK 可以对任何文件进行操作,包括 std-in,在这种情况下,它通常与 '|' 命令一起使用,例如,结合 grep 或其他命令。 例如,如果我列出当前目录中的所有文件
ls -l
总用量 140
-rw-r--r-- 1 root root 55121 1月 3 17:03 combined_log_format.log
-rw-r--r-- 1 root root 80644 1月 3 17:03 combined_log_format_w_resp_time.log
-rw-r--r-- 1 root root 71 1月 3 17:55 sampler.log
我可以看到文件大小报告为3 列数据。如果我想知道它们的总大小,这个目录中的文件我可以做:
ls -l | awk 'BEGIN {sum=0} {sum=sum+$5} END {print sum}'
135836
请注意,'print sum' 打印变量 sum 的值,因此如果 sum = 2 则 'print sum' 给出输出 '2' 而 'print $ sum' 将打印 '1' ,因为第二个字段包含值 '1' 。
因此,会很简单编写一个可以计算平均值的和一列数字的标准偏差的 awk 命令 - 在主要内部积累 'sum_x' 和 'sum_x2' 部分,然后使用标准公式计算 END 部分的平均值和标准偏差。 AWK 支持('for' 和 'while')循环和分支(使用 'if ')。
所以,如果你想修剪一个文件并且只在每个第 3 行操作,你可以这样做:
ls -l | awk '{for (i=1;i<3;i++) {getline}; print NR,$0}'
3 -rw-r--r-- 1 root root 80644 1月 3 17:03 combined_log_format_w_resp_time.log
4 -rw-r--r-- 1 root root 71 1月 3 17:55 sampler.log
for 循环使用 “getline” 命令遍历文件,并且每隔3次才打印一行。注意,由于文件的行数是4,不能被3整除,所以最后一个命令提前完成,所以最后的 “print $0” 命令打印第4行,你可以看到我们也打印了行,使用 NR 变量输出行号。
2、AWK 模式匹配
AWK 是一种面向行的语言。首先是模式,然后是动作。 操作语句用{ and }括起来。模式可能缺失,或者动作可能缺失,但是,当然不是都。 如果缺少模式,则对每个输入记录执行操作。一个丢失的动作将打印整个记录。
AWK 模式包括正则表达式(使用与“grep -E”相同的语法)和使用的组合特殊符号 “&&” 表示“逻辑AND ”,“||”表示“逻辑或”,“!” 的意思是“逻辑不”。 你也可以做关系模式、模式组、范围等。
3、AWK 控制语句
if (condition) statement [ else statement ]
while (condition) statement
do statement while (condition)
for (expr1; expr2; expr3) statement
for (var in array) statement
break
continue
exit [ expression ]
4、AWK 输入/输出语句
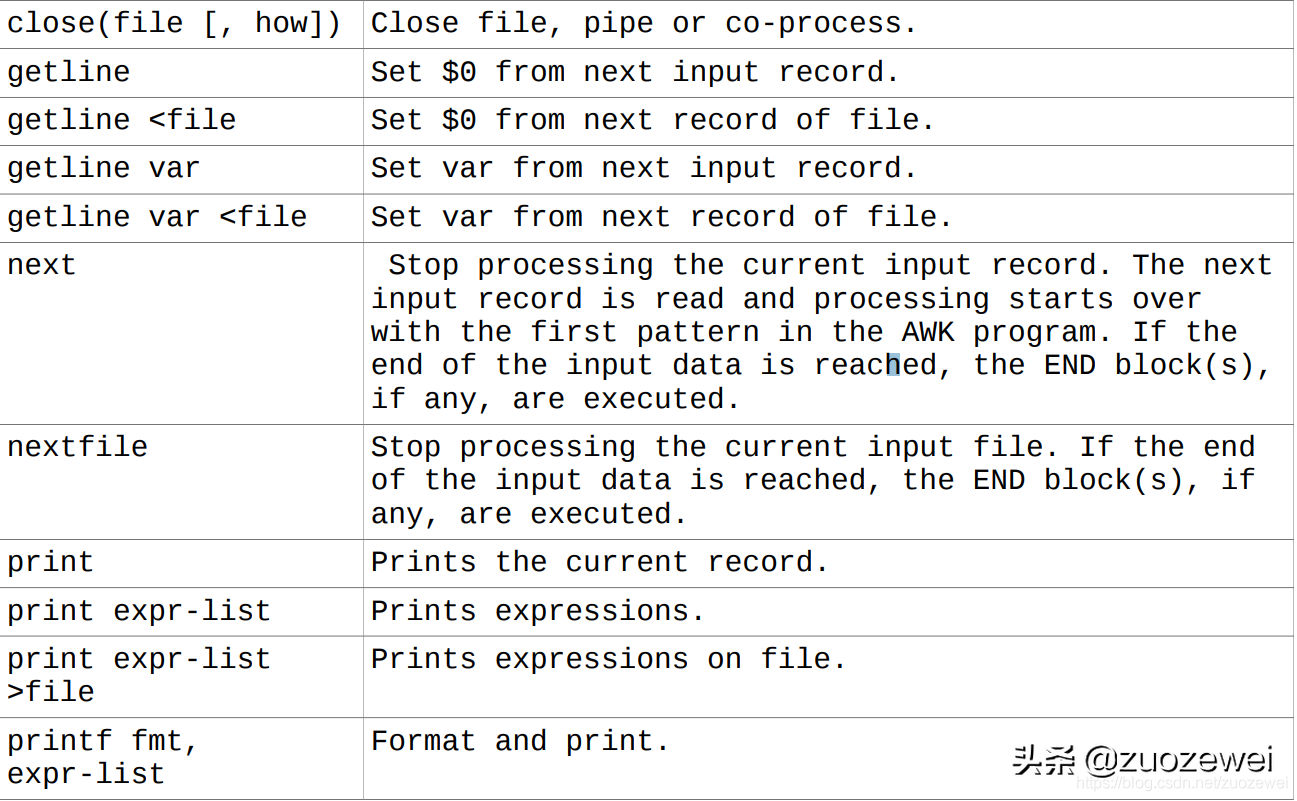
注意:printf 命令允许你使用类似 C 的语法更密切地指定输出格式 例如,你可以指定给定宽度的整数,浮点数或字符串等。
5、AWK 数学函数

6、AWK 字符串函数

7、AWK 命令行和用法
你可以根据需要多次使用 ' -v ' 标志将变量传递给 awk 程序,例如
awk -v skip=3 '{for (i=1;i<skip;i++) {getline}; print $0}' sampler.log
booze
bungie
broken$tuff你还可以使用编辑器编写 awk 程序,然后将其另存为脚本文件,例如:
$ cat awk_strip
#!/usr/bin/awk -f
#only print out every 3rd line of input file
BEGIN {skip=3}
{for (i=1;i<skip;i++)
{getline};
print $0}然后可以将其用作新的附加命令
chmod u+x awk_strip
./awk_strip sampler.dat五、sed = stream editor
sed 对输入流(文件或来自管道的输入)执行基本文本转换单通过流,所以效率很高。 但是, sed 能够管道过滤文本,特别区别于其他类型的编辑器。
1、sed 基础
sed 可以在命令行或 shel l脚本中使用,以非交互方式编辑文件。 也许最有用的功能是对一个字符串进行 “搜索和替换” 到另一个字符串。
您可以将 sed 命令嵌入到使用 '-e' 选项调用 sed 的命令行中,或者将它们放在一个单独的文件中 'sed.in' 并使用 '-f sed.in' 选项调用 sed。 后一种选择是如果 sed 命令很复杂并涉及大量regexp,则最常用! 例如:
sed -e 's/input/output/' sampler.log
boot
book
booze
machine
boots
bungie
bark
aardvark
broken$tuff
robots
将从 sampler.log 回显到标准输出的每一行,改变每一行的 'input' 排成 'output'。 注意 sed 是面向行的,所以如果你想改变每一行的每一个事件,那么你需要让它成为一个 '贪婪' 的搜索和替换,如下所示:
sed -e 's/input/output/g' sampler.log
boot
book
booze
machine
boots
bungie
bark
aardvark
broken$tuff
robots
/.../ 中的表达式可以是文字字符串或正则表达式。 注意默认情况下,输出将写入 stdout。 你可以将其重定向到新文件,或者如果你愿意 编辑现有文件,你应该使用 '-i' 标志:
sed -e 's/input/output/' sampler.log > new_file
sed -i -e 's/input/output/' sampler.log
2、sed 和正则表达式
如果你希望在搜索命令中使用的某个字符是特殊符号,例如 '/',该怎么办?(例如在文件名中)或 '*' 等? 然后你必须像 grep(和awk)那样转义符号。 跟你说想要编辑shell脚本以引用 /usr/local/bin而不是 /bin,那么你可以这样做
sed -e 's//bin//usr/local/bin/' my_script > new_script
如果你想在搜索中使用通配符怎么办 - 如何编写输出字符串? 你需要使用与找到的模式对应的特殊符号“&”。 所以说你想要每行以你的文件中的数字开头,并用括号括起该数字:
sed -e 's/[0-9]*/(&)/'
其中 [0-9] 是所有个位数的 regexp 范围,而 '*' 是重复计数,表示任何数字的位数。 你还可以在 regexp 中使用位置指令,甚至可以将部分匹配结果保存在模式缓冲区,以便在其他地方重用。
六、其它 SED 命令
一般形式是
sed -e '/pattern/ command' sampler.log
其中 'pattern' 是正则表达式,'command' 可以是 's'= search&replace,或 'p'= print,或 'd'= delete,或 'i'=insert,或 'a'=append 等。
请注意,默认操作是打印所有不是无论如何匹配,所以如果你想抑制它,你需要使用 '-n' 标志调用 sed,然后你可以使用 'p' 命令来控制打印的内容。
所以,如果你想做一个所有的列表 你可以使用的子目录
ls -l | sed -n -e '/^d/ p'
因为长列表开始每行都带有 'd' 符号,如果它是一个目录,所以这只会打印出来那些以 'd' 符号开头的行。 同样,如果你想删除所有以评论符号 '#' 开头的行,你可以使用
sed -e '/^#/ d' sampler.log
也可以使用范围表单
sed -e '1,100 command' sampler.log
在第1-100 行执行“命令”。你也可以用特殊的行号 $ 来表示“结束”文件。 因此,如果你想删除文件的前10行以外的所有行,您可以使用
sed -e '11,$ d' sampler.log
你还可以使用模式范围表单,其中第一个正则表达式定义范围的开始,以及第二次停止。 所以,例如,如果你想打印从 'boot' 到 'machine' 的所有行 你可以这样做:
sed -n -e '/boot$/,/mach/p' sampler.log
boot
book
booze
machine
然后只打印出(-n)regexp 给定的给定范围内的那些行。
1、延伸阅读
使用 sed 可以做的事情还有很多 ,具体参考:http://www.grymoire.com/Unix/Sed.html
七、总结
Linux 三剑客 awk,sed和grep 在性能领域广泛用于性能建模、性能监控及性能分析等方面,也是各大互联网公司测试岗高频面试题,中高端测试人员必备技能之一。