对book3.csv数据集,实现如下功能:
(1)创建训练集、测试集
(2)用rpart包创建关于类别的cart算法的决策树
(3)用测试集进行测试,并评估模型
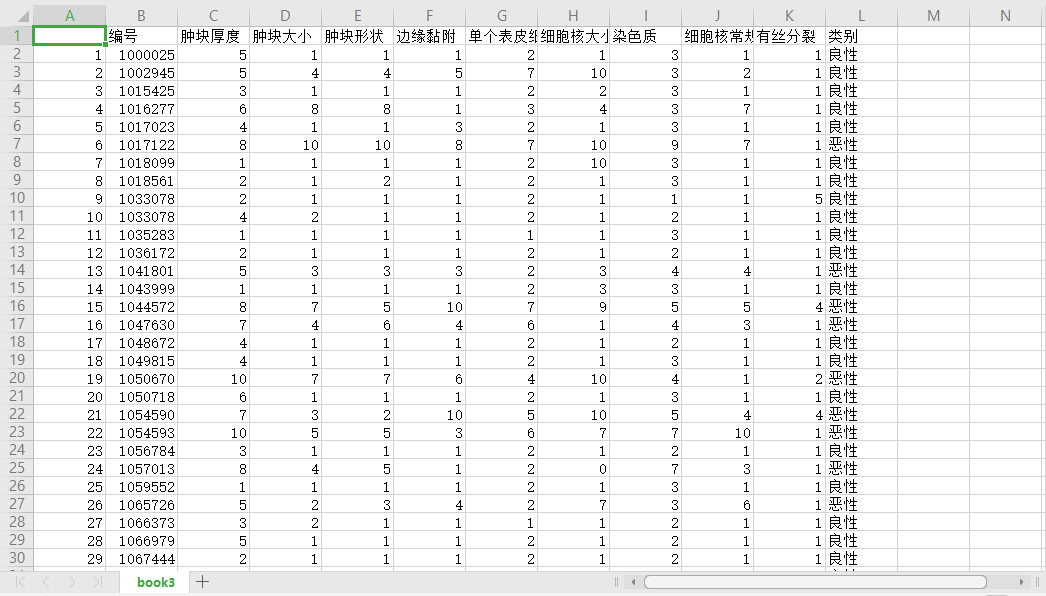
book3.csv数据集


setwd('D:\data') list.files() dat=read.csv(file="book3.csv",header=TRUE) #变量重命名,并通过x1~x11对class属性进行预测 colnames(dat)<-c("x1","x2","x3","x4","x5","x6","x7","x8","x9","x10","x11","class") n=nrow(dat) split<-sample(n,n*(3/4)) traindata=dat[split,] testdata=dat[-split,] set.seed(1) library(rpart) #用测试集进行测试 Gary1<-rpart(class~.,data=testdata,method="class", control=rpart.control(minsplit=1),parms=list(split="gini")) printcp(Gary1) #交叉矩阵评估模型 pre1<-predict(Gary1,newdata=testdata,type='class') tab<-table(pre1,testdata$class) tab #评估模型(预测)的正确率 sum(diag(tab))/sum(tab)
实现过程
数据预处理并创建训练(测试)集
setwd('D:\data') list.files() dat=read.csv(file="book3.csv",header=TRUE) #变量重命名,并通过x1~x11对class属性进行预测 colnames(dat)<-c("x1","x2","x3","x4","x5","x6","x7","x8","x9","x10","x11","class") n=nrow(dat) split<-sample(n,n*(3/4)) traindata=dat[split,] testdata=dat[-split,]
设定生成随机数的种子,种子是为了让结果具有重复性
set.seed(1)
加载rpart包创建关于类别的cart算法的决策树
library(rpart)
用测试集进行测试
> Gary1<-rpart(class~.,data=testdata,method="class", control=rpart.control(minsplit=1),parms=list(split="gini")) > printcp(Gary1) Classification tree: #分类树: rpart(formula = class ~ ., data = testdata, method = "class", parms = list(split = "gini"), control = rpart.control(minsplit = 1)) Variables actually used in tree construction: #树构建中实际使用的变量: [1] x1 x10 x2 x4 x5 x8 #〔1〕X1 x10 x2 x4 x5 x8 Root node error: 57/175 = 0.32571 #根节点错误:57/175=0.32571 n= 175 CP nsplit rel error xerror xstd 1 0.754386 0 1.000000 1.00000 0.108764 2 0.052632 1 0.245614 0.31579 0.070501 3 0.035088 3 0.140351 0.31579 0.070501 4 0.017544 6 0.035088 0.35088 0.073839 5 0.010000 7 0.017544 0.31579 0.070501
交叉矩阵评估模型
pre1<-predict(Gary1,newdata=testdata,type='class') > tab<-table(pre1,testdata$class) > tab pre1 恶性 良性 恶性 57 1 良性 0 117
评估模型(预测)的正确率
对角线上的数据实际值和预测值相同,非对角线上的值为预测错误的值
> sum(diag(tab))/sum(tab)
[1] 0.9942857