Hadoop学习笔记—16.Pig框架学习
一、关于Pig:别以为猪不能干活
1.1 Pig的简介


Pig是一个基于Hadoop的大规模数据分析平台,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。Pig为复杂的海量数据并行计算提供了一个简单的操作和编程接口。
Compare:相比Java的MapReduce API,Pig为大型数据集的处理提供了更高层次的抽象,与MapReduce相比,Pig提供了更丰富的数据结构,一般都是多值和嵌套的数据结构。Pig还提供了一套更强大的数据变换操作,包括在MapReduce中被忽视的连接Join操作。
Pig包括两部分:
- 用于描述数据流的语言,称为Pig Latin。
- 用于执行Pig Latin程序的执行环境,当前有两个环境:单JVM中的本地执行环境和Hadoop集群上的分布式执行环境。
Pig内部,每个操作或变换是对输入进行数据处理,然后产生输出结果,这些变换操作被转换成一系列MapReduce作业,Pig让程序员不需要知道这些转换具体是如何进行的,这样工程师可以将精力集中在数据上,而非执行的细节上。
1.2 Pig的特点
(1)专注于于大量数据集分析;
(2)运行在集群的计算架构上,Yahoo Pig 提供了多层抽象,简化并行计算让普通用户使用;这些抽象完成自动把用户请求queries翻译成有效的并行评估计划,然后在物理集群上执行这些计划;
(3)提供类似 SQL 的操作语法;
(4)开放源代码;
1.3 Pig与Hive的区别
对于开发人员,直接使用Java APIs可能是乏味或容易出错的,同时也限制了Java程序员在Hadoop上编程的运用灵活性。于是Hadoop提供了两个解决方案,使得Hadoop编程变得更加容易。
•Pig是一种编程语言,它简化了Hadoop常见的工作任务。Pig可加载数据、表达转换数据以及存储最终结果。Pig内置的操作使得半结构化数据变得有意义(如日志文件)。同时Pig可扩展使用Java中添加的自定义数据类型并支持数据转换。
•Hive在Hadoop中扮演数据仓库的角色。Hive添加数据的结构在HDFS,并允许使用类似于SQL语法进行数据查询。与Pig一样,Hive的核心功能是可扩展的。
Pig和Hive总是令人困惑的。Hive更适合于数据仓库的任务,Hive主要用于静态的结构以及需要经常分析的工作。Hive与SQL相似 促使 其成为Hadoop与其他BI工具结合的理想交集。Pig赋予开发人员在大数据集领域更多的灵活性,并允许开发简洁的脚本用于转换数据流以便嵌入到较大的 应用程序。Pig相比Hive相对轻量,它主要的优势是相比于直接使用Hadoop Java APIs可大幅削减代码量。正因为如此,Pig仍然是吸引大量的软件开发人员。
二、Pig的安装配置
2.1 准备工作
下载pig的压缩包,这里使用的是pig-0.11.1版本,已经上传至了百度网盘中(URL:http://pan.baidu.com/s/1o6IDfhK)
(1)通过FTP工具上传到虚拟机中,可以选择XFtp、CuteFTP等工具
(2)解压缩
tar -zvxf pig-0.11.1.tar.gz
(3)重命名
mv pig-0.11.1 pig
(4)修改/etc/profile,增加内容如下,最后重新生效配置文件source /etc/profile
export PIG_HOME=/usr/local/pig
export PATH=.:$HADOOP_HOME/bin:$PIG_HOME/bin:$HBASE_HOME/bin:$ZOOKEEPER_HOME/bin:$JAVA_HOME/bin:$PATH
2.2 设置Pig与Hadoop关联
进入$PIG_HOME/conf中,编辑pig.properties文件,加入以下两行内容:
fs.default.name=hdfs://hadoop-master:9000
mapred.job.tracker=hadoop-master:9001
三、Pig的使用实例
3.1 文件背景
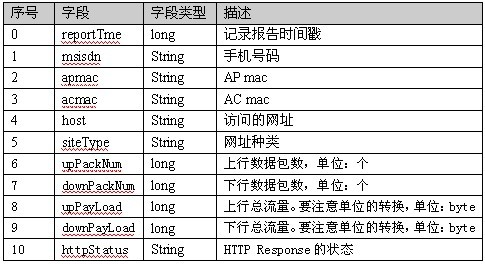
结合本笔记第五篇《自定义类型处理手机上网日志》的手机上网日志为背景,我们要做的就是通过Pig Latin对该日志进行流量的统计。该日志的数据结构定义如下图所示:(该文件的下载地址为:http://pan.baidu.com/s/1dDzqHWX)
PS:在使用Pig之前先将该文件上传至HDFS中,这里上传到了/testdir/input目录中
hadoop fs -put HTTP_20130313143750.dat /testdir/input

3.2 Load:把HDFS中的数据转换为Pig可以处理的模式
(1)首先通过输入Pig进入grunt,然后使用Load命令将原始文件转换为Pig可以处理的模式:
grunt>A = LOAD '/user/cristo/luxun123/HTTP_20130313143750.dat' AS (t0:long,
t1:chararray, t2:chararray, t3:chararray, t4:chararray, t5:chararray, t6:long, t7:long, t8:long, t9:long, t10:chararray);
(2)通过Pig对指令的解析,帮我们转换成为了MapReduce任务:
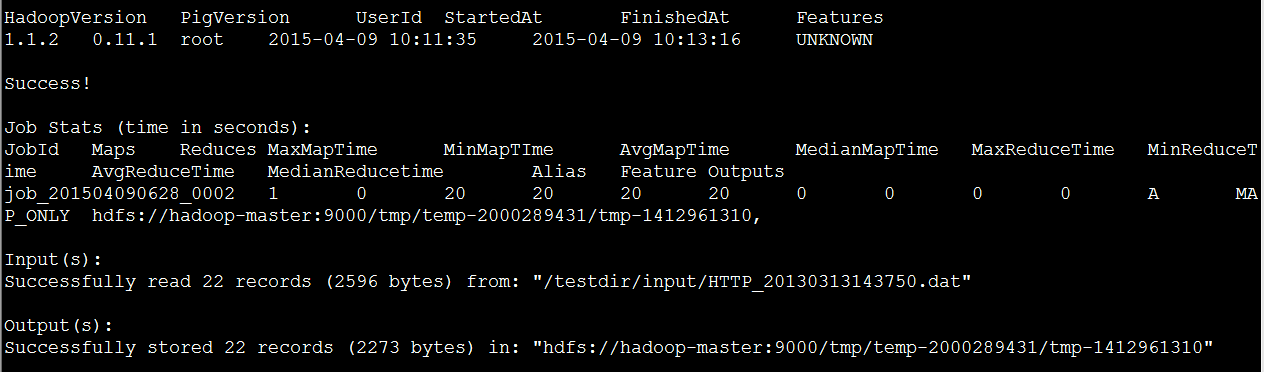
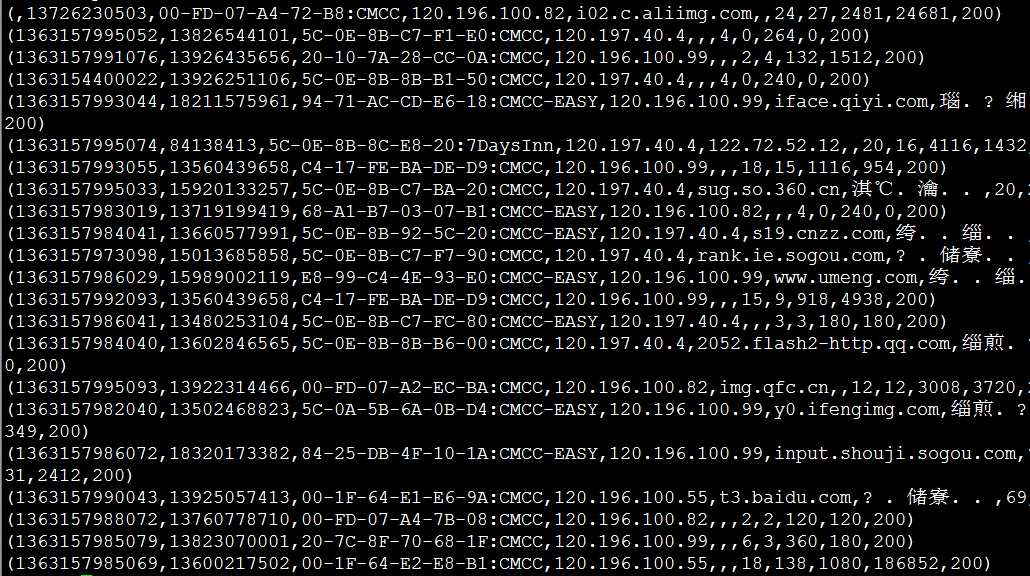
(3)通过以下命令可以查看结果:
grunt>DUMP A;
3.3 FOREACH:把A中有用的字段抽取出来
(1)这里我们需要统计的只是手机号以及四个流量数据,因此我们通过遍历将A中的部分字段抽取出来存入B中:
grunt> B = FOREACH A GENERATE msisdn, t6, t7, t8, t9;
(2)通过以下命令可以查看结果:
grunt>DUMP B;

3.4 GROUP:分组数据
(1)有用信息抽取出来后,看到结果中一个手机号可能有多条记录,因此这里通过手机号进行分组:
grunt> C = GROUP B BY msisdn;
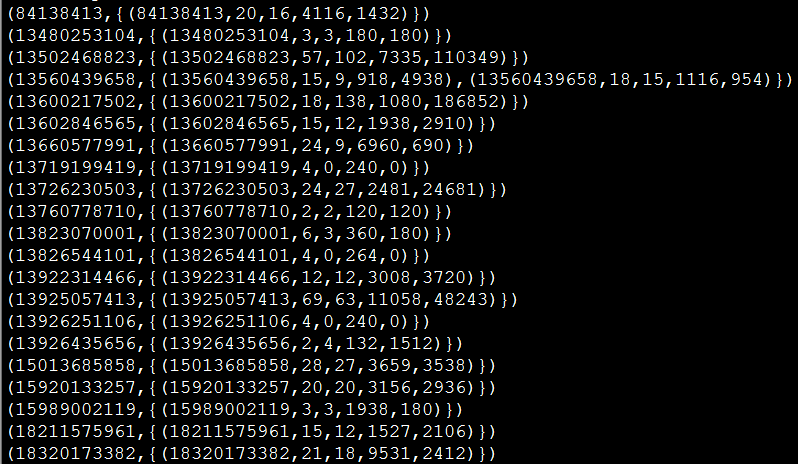
(2)通过以下命令可以查看结果:
grunt>DUMP C;
3.5 GENERATE:流量汇总
(1)在对手机号进行分组之后,我们可以看到某个手机号对应着多条流量记录数据,因此继续使用FOREACH遍历分组数据,然后对四个流量数据进行汇总,这里使用了聚合函数SUM():
grunt> D = FOREACH C GENERATE group, SUM(B.t6), SUM(B.t7), SUM(B.t8), SUM(B.t9);
(2)通过以下命令可以查看结果:
grunt>DUMP D;
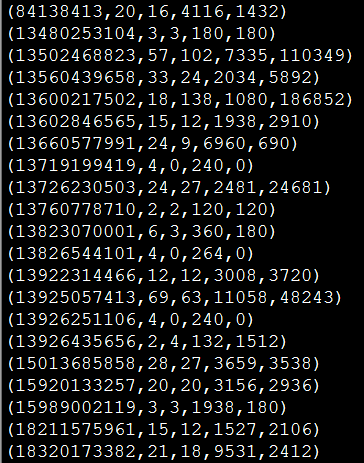
3.6 STORE:将统计结果存储到HDFS中进行持久化
(1)在对流量统计完毕之后,结果仍然是在Pig中,这里就需要对其进行持久化操作,即将结果存储到HDFS中:
grunt> STORE D INTO '/testdir/output/wlan_result';
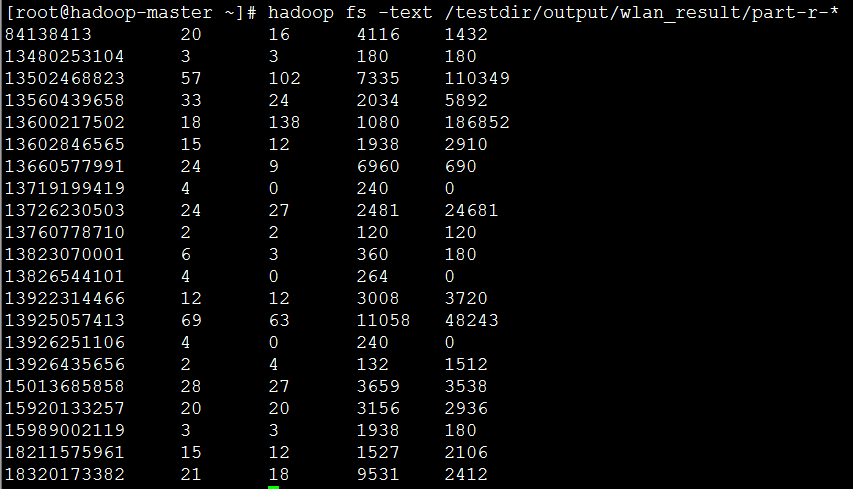
(2)通过HDFS Shell查看存储结果:
hadoop fs -text /testdir/output/wlan_result/part-r-*
参考资料
(1)yanghuahui,《Hadoop Pig简介、安装与使用》:http://www.cnblogs.com/yanghuahui/p/3768270.html
(2)cloudsky,《Hadoop使用(六)Pig》:http://www.cnblogs.com/skyme/archive/2012/06/04/2534876.html
(3)rzhzhz,《Pig与Hive的对比》:http://blog.csdn.net/rzhzhz/article/details/7557607