原文来源于博客园和CSDN
1.计算函数
abs()--取绝对值
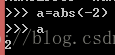
max()--取序列最大值,包括列表、元组
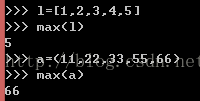
min()--取序列最小值
len()--取长度
divmod(a,b)---取a//b除数整数以及余数,成为一个元组

pow(x,y)--取x的Y次幂
pow(x,y,z)先x的Y次幂,再对Z取余
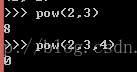
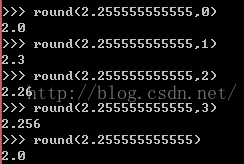
round()--修改精度,如果没有,默认取0位
range()快速生成一个列表
2.其他函数
callable()--返回是否可调用返回true或false
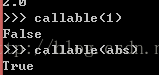
isinstance(a,type)---判断前面的是否是后面的这种类型,返回true或false
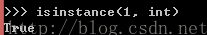
cmp(a,b)---判断ab是否相等,相等返回0,A<B返回-1,A>B返回1

range()--快速生成一个列表,类型为list
xrange()---快速生成一个列表,类型为xrange
3.类型转换函数
type()
int()
long()
float()
complex()--转换成负数
hex()--转换成十六进制
oct()--转换成八进制
chr()--参数0-252,返回当前的ASCII码
ord()--参数ASCII码,返回对应的十进制整数
4.string函数
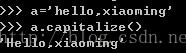
str.capitalize()--对字符串首字母大写
str.replace(a.b)---对字符串a改为b

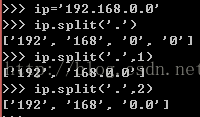
str.split()---对字符串进行分割,第一个参数是分隔符,后面参数是分割几次。
string函数导入使用

5.序列函数
filter()--筛选返回为true返回成序列
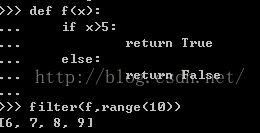
lambda--定义函数
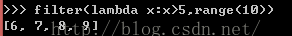
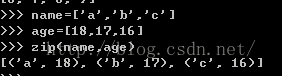
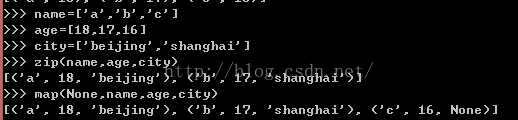
zip()---对多个列表进行压缩组合成一个新列表,但是如果多个列表的元素个数不同,组合的结果按最少元素的进行组合
map--对多个列表进行压缩组合成一个新列表,但是如果多个列表的元素个数不同,结果是将所有的元素取出来,缺少的以None代替。如果是None,直接组合,如果是函数,可以按函数进行组合
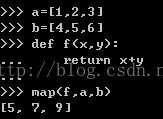
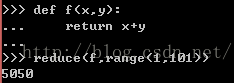
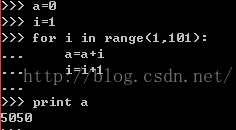
reduce()--对每个元素先前两个执行函数,然后结果和后一个元素进行函数操作,如阶乘,阶加
-----------------------------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------------------------
urlencode与urldecode
当url中包含中文或者参数包含中文,需要对中文或者特殊字符(/、&)做编码转换。
urlencode的本质:把字符串转为gbk编码,再把x替换成%。如果终端是utf8编码的,需要把结果再转成utf8输出,否则会乱码。
urlencode
urllib库里面的urlencode函数,可以把key-value健值对的key、value都进行urlencode并转换成a=1&b=2的字符串。
#key-value健值对
>>> from urllib import urlencode
>>> data={'a':'a1','b':'中文'}
>>> print urlencode(data)
a=a1&b=%E4%B8%AD%E6%96%87
>>> data={'a':'a1','b测试':'中文'}
>>> print urlencode(data)
a=a1&b%E6%B5%8B%E8%AF%95=%E4%B8%AD%E6%96%87urllib库里面的quote函数,可以针对单个字符串进行urlencode转换。
#string
>>> from urllib import quote
>>> data="测试"
>>> print quote(data)
%E6%B5%8B%E8%AF%95urldecode
urllib只提供了unquote()函数。
>>> from urllib import unquote
>>> unquote("%E6%B5%8B%E8%AF%95")
'xe6xb5x8bxe8xafx95'
>>> print unquote("%E6%B5%8B%E8%AF%95")
测试
>>>json处理
两个函数:
| 函数 | 描述 |
|---|---|
| json.dumps | 将python对象编码成JSON字符串(对象->字符串) |
| json.loads | 将已经编码的json字符串解码为Python对象(字符串->对象) |
json.dumps
语法:json.dumps(data, sort_keys=True, indent=4,separators=(self.item_separator, self.key_separator))
>>> import json
>>> data={"a":"a1","b":"b1"}
>>> jsonstr=json.dumps(data)
>>> print jsonstr
{"a": "a1", "b": "b1"}
#输出格式化
>>> print json.dumps(data, sort_keys=True, indent=4,separators=(",",":"))
{
"a":"a1",
"b":"b1"
}
>>>python原始类型向json类型的转换对照表:
| Python | JSON |
|---|---|
| dict | object |
| list,tuple | array |
| str,unicode | string |
| int,long,float | number |
| True | true |
| False | false |
| None | null |
json.loads
json.loads——返回Python字段的数据类型
>>> import json
>>> jsonstr='{"a":"a1","b":"b1"}'
>>> print json.loads(jsonstr)
{u'a': u'a1', u'b': u'b1'}
>>> jsonstr='{"a":"a1","b":null,"c":false,"d":{"aa":"aa1","bb":"bb1"}}'
>>> print json.loads(jsonstr)
{u'a': u'a1', u'c': False, u'b': None, u'd': {u'aa': u'aa1', u'bb': u'bb1'}}
>>> jsonstr='[{"a":"a1"},{"b":"b2"}]'
>>> print json.loads(jsonstr)
[{u'a': u'a1'}, {u'b': u'b2'}]json类型转换为python类型的对照表
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | unicode |
| number(int) | int,long |
| number(real) | float |
| true | True |
| false | False |
| null | None |
结论:print只能输出python认识的数据类型,python.dumps才可以格式化输出。
计算字符串md5
方法一:使用md5包
import md5 def calMd5(signdata,signkey,joiner=""): signdata=signdata+joiner+""+signkey m=md5.new(signdata) sign = m.hexdigest() return sign
方法二:使用hashlib包
import hashlib def calHashMd5(signdata,signkey,joiner=""): signdata=signdata+joiner+""+signkey m=hashlib.md5(signdata) sign = m.hexdigest() return sign
计算hmacsha1
hmac:密钥相关的哈希运算消息认证码,hmac运算利用哈希算法(可以是MD5或者SHA-1),以一个密钥和一个消息为输入,生成一个消息摘要作为输出。
作用:
(1)验证接受的授权数据和认证数据;
(2)确认接受到的命令请求是已经授权的请求且传送过程没有被篡改
import hmac import base64 def hmacSha1WithBase64(signdata,signkey): sign = hmac.new(signkey, signdata,sha1).digest() sign = base64.b64encode(sign) return sign
字符串拼接
from collections import OrderedDict def composeStr(data,joiner,withkey=True,key_value_joiner="="): data = OrderedDict(sorted(data.items(), key=lambda t:t[0])) if withkey : signdata = joiner.join([key_value_joiner.join((str(key), str(elem))) for key, elem in data.iteritems()]) else : signdata= joiner.join([elem for key, elem in data.items()]) return signdata
-----------------------------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------------------------
python常见函数
abs函数
abs函数用来求一个数的绝对值
abs(-1.24)max函数
max函数用来求多个参数的最大值
max(2,3,1,-5)类型转换函数
常见的类型转换函数,包括int(),float(),bool(),str()等
str(100)hex函数
hex函数可以将一个整数转换为十六进制表示的字符串
hex(255)可以改变函数名字
#将a指向abs函数
a = abs
a(-1)空函数
定义一个什么都不做的函数:
def nop():
pass空函数的作用:pass作为占位符,能够先让代码运行起来,还可以用作其他语句中:
if age >= 18:
pass这里pass不能缺少,不然语法错误。
参数检查
数据类型检查可以用内置函数isinstance()来实现:
def my_abs(x): if not isinstance(x, (int,float)): raise TypeError('bad operand type') if x >= 0: return x else : return -x
添加完之后如果输入错误的参数类型就会抛出你指定的错误
函数多返回值
导入包使用import语句
import math def move(x, y, step, angle=0): nx = x + step * math.cos(angle) ny = y - step * math.sin(angle) return nx,ny x,y = move(100, 100, 60, math.pi / 6) print(x,y)
其实他的返回值依然是一个值来的,不过因为这个返回值是tuple类型而已。
# 求一元二次方程解 def quadratic(a, b, c): if not isinstance(a, (int,float)) and isinstance(b, (int, float)) and isinstance(c, (int, float)): raise TypeError('bad operand type') if a == 0: return 'a不能为0' n = float(b * b - 4 * a *c) if n < 0: return '方程无解' elif n == 0: x = int(-b / (2 * a)) return '方程的解为:x = %lf' % x else: x1 = (-b + math.sqrt(n)) / (2 * a) x2 = (-b - math.sqrt(n)) / (2 * a) return '方程的解为:x1 = %.1f,x2 = %.1f'%(x1,x2) a = float(input('请输入a:')) b = float(input('请输入b:')) c = float(input('请输入c:')) print(quadratic(a, b, c))
-----------------------------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------------------------
#字母的数字的相互转换
- #ord:字母转数字
- ord('A')
- #chr:数字转字母
- chr(65)
#python 的三元表达式的用法
- #给定数字1或0 转为是与否
- k = '1'
- d = '是' if int(k) else '否'
#python lambda表达式
lambda表达式可以很方便的用来代替简单函数
- #float转str 去掉末尾的'.0'
- >>> func = lambda x:str(x) if int(str(x).split('.')[1]) else str(x).split('.')[0]
- >>> func(2.0)
相当于
- def func(x):
- if int(str(x).split('.')[1]):
- x = str(x)
- else:
- x = str(x).split('.')[0]
- return x
- print (func(2.0))
#python 列表推导式- #二维元组转列表
- a = (
- ('魏登武', 18912347226.0, '农商行',0.0, 4.0, 0.0, 11820.0, 0.0, 0.0, 11560.0, 0.0, '0', '0.08', '70', '0', '张明锋'),
- ('魏德华', 18712345620.0, None,0.0, 3.0, 10000.0, 5000.0, 4000.0, 0.0, 0.0, 0.0, None, '0.05', '70', '1', '贺世海')
- )
- b = [list(i) for i in a]
- print (b)
#列表推导式嵌套
- #二维元组转列表
- #win32com操作excel--->sheet.Range().value得到 a 这样的元组
- #sheet.Range(sheet.Cells(row1, col1), sheet.Cells(row2, col2)).Value
- a = (
- ('魏登武', 18912347226.0, '农商行',0.0, 4.0, 0.0, 11820.0, 0.0, 0.0, 11560.0, 0.0, '0', '0.08', '70', '0', '张世锋'),
- ('魏德华', 18712345620.0, None,0.0, 3.0, 10000.0, 5000.0, 4000.0, 0.0, 0.0, 0.0, None, '0.05', '70', '1', '贺明海')
- )
- b = [list(i) for i in a]#元组转列表
- def func(i):
- if i == None:
- i = ''
- elif type(i) == float:
- i = str(i).split('.')[0] if str(i).split('.')[1] == '0' else str(i)
- return i
- #列表推导式嵌套
- c = [[func(j) for j in i] for i in b]#替换二维列表里的None和float转str并去掉小数为0 的 ‘.0’
- print (c)
#ord:字母转数字
ord('A')
#chr:数字转字母
chr(65)
#json与列表的相互转换
dumps#
json.dumps(k)->json
k = '123'
json.loads(k)->列表
#正确获取当前的路径:
print (os.path.dirname(os.path.realpath(__file__)))
-----------------------------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------------------------
内置函数,一般都是因为使用比较频繁或是元操作,所以通过内置函数的形式提供出来。在Python中,python给我们提供了很多已经定义好的函数,这里列出常用的内置函数,分享出来供大家参考学习,下面话不多说,来一起看看详细的介绍吧。
一、数学函数
abs()求数值的绝对值min()列表的最下值max()列表的最大值divmod()取膜pow()乘方round()浮点数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#abs 绝对值函数 输出结果是1print abs(-1)#min 求列表最小值#随机一个1-20的步长为2的列表lists=range(1,20,2)#求出列表的最小值为1print min(lists)#max 求列表的最大值 结果为19print max(lists)#divmod(x,y) 参数:2个 返回值:元祖#函数计算公式为 ((x-x%y)/y, x%y)print divmod(2,4)#pow(x,y,z)#参数:2个或者3个 z可以为空# 计算规则 (x**y) % zprint pow(2,3,2)#round(x)#将传入的整数变称浮点print round(2) |
二、功能函数
- 函数是否可调用:
callable(funcname) - 类型判断:
isinstance(x,list/int) - 比较:
cmp(‘hello','hello') - 快速生成序列:
(x)range([start,] stop[, step]) - 类型判断
type()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
#callable()判断函数是否可用 返回True ,这里的函数必须是定义过的def getname(): print "name"print callable(getname)#isinstance(object, classinfo)# 判断实例是否是这个类或者object是变量a=[1,3,4]print isinstance(a,int)#range([start,] stop[, step])快速生成列表# 参数一和参数三可选 分别代表开始数字和布长#返回一个2-10 布长为2的列表print range(2,10,2)#type(object) 类型判断print type(lists) |
三、类型转换函数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
#int(x)转换为int类型print int(2.0)#返回结果<type 'int'>print type(int(2.0))#long(x) 转换称长整形print long(10.0)#float(x) 转称浮点型print float(2)#str(x)转换称字符串print str()#list(x)转称listprint list("123")#tuple(x)转成元祖print tuple("123")#hex(x) print hex(10)#oct(x)print oct(10)#chr(x)print chr(65)#ord(x)print ord('A') |
四、字符串处理
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
name="zhang,wang"#capitalize首字母大写 #Zhang,wangprint name.capitalize()#replace 字符串替换#li,wangprint name.replace("zhang","li")#split 字符串分割 参数:分割规则,返回结果:列表#['zhang', 'wang']print name.split(",") |
五、序列处理函数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
strvalue="123456"a=[1,2,3]b=[4,5,6]#len 返回序列的元素的长度6print len(strvalue)#min 返回序列的元素的最小值1print min(strvalue)#max 返回序列元素的最大值6print max(strvalue)#filter 根据特定规则,对序列进行过滤#参数一:函数 参数二:序列#[2]def filternum(x): if x%2==0: return Trueprint filter(filternum,a)#map 根据特定规则,对序列每个元素进行操作并返回列表#[3, 4, 5]def maps(x): return x+2print map(maps,a)#reduce 根据特定规则,对列表进行特定操作,并返回一个数值#6def reduces(x,y): return x+yprint reduce(reduces,a)#zip 并行遍历#注意这里是根据最序列长度最小的生成#[('zhang', 12), ('wang', 33)]name=["zhang","wang"]age=[12,33,45]print zip(name,age)#序列排序sorted 注意:返回新的数列并不修改之前的序列print sorted(a,reverse=True) |
-----------------------------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------------------------
一、数学相关
1、绝对值:abs(-1)
2、最大最小值:max([1,2,3])、min([1,2,3])
3、序列长度:len('abc')、len([1,2,3])、len((1,2,3))
4、取模:divmod(5,2)//(2,1)
5、乘方:pow(2,3,4)//2**3/4
6、浮点数:round(1)//1.0
二、功能相关
1、函数是否可调用:callable(funcname),注意,funcname变量要定义过
2、类型判断:isinstance(x,list/int)
3、比较:cmp('hello','hello')
4、快速生成序列:(x)range([start,] stop[, step])
三、类型转换
1、int(x)
2、long(x)
3、float(x)
4、complex(x) //复数
5、str(x)
6、list(x)
7、tuple(x) //元组
8、hex(x)
9、oct(x)
10、chr(x)//返回x对应的字符,如chr(65)返回‘A'
11、ord(x)//返回字符对应的ASC码数字编号,如ord('A')返回65
四、字符串处理
1、首字母大写:str.capitalize
>>> 'hello'.capitalize()
'Hello'
2、字符串替换:str.replace
>>> 'hello'.replace('l','2')
'he22o'
可以传三个参数,第三个参数为替换次数
3、字符串切割:str.split
>>> 'hello'.split('l')
['he', '', 'o']
可以传二个参数,第二个参数为切割次数
以上三个方法都可以引入String模块,然后用string.xxx的方式进行调用。
五、序列处理函数
1、len:序列长度
2、max:序列中最大值
3、min:最小值
4、filter:过滤序列
>>> filter(lambda x:x%2==0, [1,2,3,4,5,6])
[2, 4, 6]
5、zip:并行遍历
>>> name=['jim','tom','lili']
>>> age=[20,30,40]
>>> tel=['133','156','189']
>>> zip(name,age,tel)
[('jim', 20, '133'), ('tom', 30, '156'), ('lili', 40, '189')]
注意,如果序列长度不同时,会是下面这样的结果:
>>> name=['jim','tom','lili']
>>> age=[20,30,40]
>>> tel=['133','170']
>>> zip(name,age,tel)
[('jim', 20, '133'), ('tom', 30, '170')]
6、map:并行遍历,可接受一个function类型的参数
>>> a=[1,3,5]
>>> b=[2,4,6]
>>> map(None,a,b)
[(1, 2), (3, 4), (5, 6)]
>>> map(lambda x,y:x*y,a,b)
[2, 12, 30]
7、reduce:归并
>>> l=range(1,101)
>>> l
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100]
>>> reduce(lambda x,y:x+y,l)
5050
-----------------------------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------------------------
列表
list1.append(x) 将x添加到列表末尾
list1.sort() 对列表元素排序
list1.reverse() 将列表元素逆序
list1.index(x) 返回第一次出现元素x的索引值
list1.insert(i,x) 在位置i处插入新元素x
list1.count(x) 返回元素x在列表中的数量
list1.remove(x) 删除列表中第一次出现的元素x
list1.pop(i) 取出列表中i位置上的元素,并将其删除
元组
- 元组(tuple)是特殊的序列类型
- 一旦被创建就不能修改,使得代码更安全
- 使用逗号和圆括号来表示,如(‘red’,‘blue’,‘green’),(2,4 , 6)
- 访问方式和列表相同
- 一般用于表达固定数据项,函数多返回值等情况
特点:
- 元组中的元素可以是不同类型
- 元组中各元素存在先后关系,可通过索引访问元组中的数据
math库
math.pi 圆周率
math.ceil(x) 对x向上取整
math.floor(x) 对x向下取整
math.pow(x,y) x的y次方
math.sqrt(x) x的平方根
math.fsum(list1) 对集合内的元素求和
更多math库函数请参考:https://docs.python.org/3/library/math.html
datetime库
- 处理时间的标准函数库datetime
- datetime.now()获取当前日期和时间

- 字符串->datetime
datetime.strptime(),解析时间字符串


注释:Y表示四位数年份,y表示两位数年份。
- datetime->字符串
datetime.strftime(),格式化datetime为字符串显示
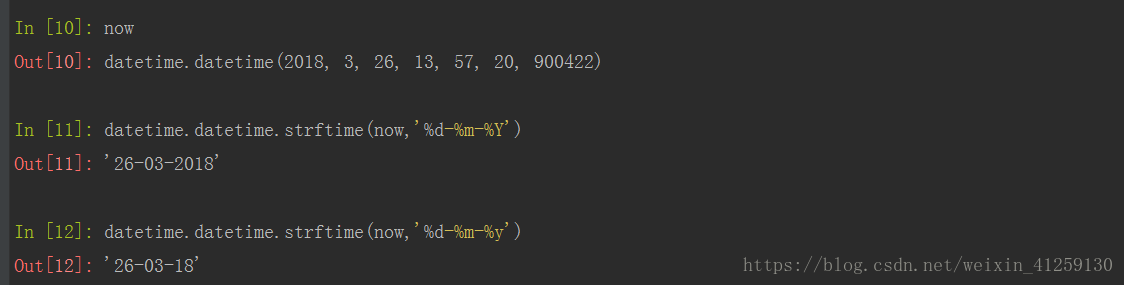
- 日期时间格式参考:
https://docs.python.org/3/library/datetime.html#strftime-strptime-behavior
- isocalendar(),返回年,周数,及周几
- 更多操作参考:
https://docs.python.org/3/library/datetime.html#module-datetime
集合
- python中的集合(set)类型同数学中的集合概念一致,即包含0或多个数据项的无序组合
- 集合中的元素不可重复
- 集合是无序组合,没有索引和位置的概念
- set()函数用于集合的生成,返回结果是一个无重复且排序任意的集合
- 集合通常用于表示成员间的关系、元素去重等。
集合的操作:
- s-t 或 s.difference(t) 返回在集合s中但不在t中的元素
- s&t 或 s.intersection(t) 返回同时在集合s和t中的元素
- s|t 或 s.union(t) 返回结合s和t中的所有元素
- s^t 或 s.symmetric_difference(t) 返回集合s和t中的元素,但不包括同时在其中的元素。
字典
- 字典类型(dict)是‘’键--值‘’数据项的组合,每个元素是一个键值对。
例如:身份证号(键)--个人信息(值)
- 字典类型数据通过映射查找数据项
- 映射:通过任意键查找集合中的值得过程
- 字典类型以键为索引,一个键对应一个值
- 字典类型的数据是无序的
基本操作:
- 定义空字典: d = dict()
- 增加一项: d[key] = value

- 访问: d[key]
- 删除某项: del d[key]
- key是否在字典中: key in d
- 字典的遍历:
遍历所有的key: for key in d.keys():
print(key)
遍历所有的value: for value in d.values():
print(value)
遍历所有的数据项: for item in d.items():
print(items)
random模块
- random() 生成一个【0,1.0)之间的随机浮点数
- uniform(a,b) 生成一个a到b之间的随机浮点数
- randint(a,b) 生成一个a到b之间的随机整数
- choice(<list>) 从列表中随机返回一个元素
- shuffle(<list>) 将列表中元素随机打乱
- sample(<list>,k) 从指定列表中随机获取K个元素
更多random模块的方法请参考:https://docs.python.org/3/library/random.html
matplotlib模块
- matplotlib是一个数据可视化函数库
- matplotlib的子模块pyplot提供了2D图表制作的基本函数
- 例子:https://matplotlib.org/gallery.html
- 散点图绘制:
import matplotlib.pyplot as plt
#x,y分别是X坐标和Y坐标的列表
plt.scatter(x,y)
plt.show()
Numpy
- 包括:
强大的N维数组对象array
成熟的科学函数库
使用的线性代数,随机数生成函数等
- Numpy的操作对象是多维数组ndarray
ndarray.shape 数组的维度
- 创建数组:np.array(<list>),np.arange()...
- 改变数组形状 reshape()
- Numpy创建随机数组:
np.random.randint(a,b,size) #创建【a,b)之间,形状为size的数组