18.11.15更新,因为代码用set的话集群跑不了,所以更改为一直用dataframe进行操作,发现Pandas和spark中对dataframe的操作不同,所以增加了pandas的group操作
最近进行关联规则算法的学习,使用的是tpch里的数据,取了customer和part两行数据如图
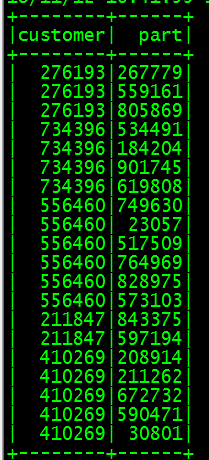
而关联规则算法要求的数据格式为{customer|part1,part2,part3……},因此要根据customer号进行合并,由于使用的是spark读取tpch的数据,所以读取出来是rdd或者dataframe的形式,所以要使用rdd自带的方法groupByKey。
首先读取数据得到rdd1
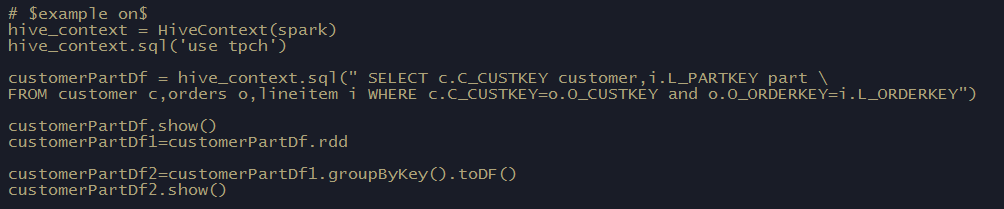
hive_context = HiveContext(spark) hive_context.sql('use tpch') customerPartDf = hive_context.sql(" SELECT c.C_CUSTKEY customer,i.L_PARTKEY part FROM customer c,orders o,lineitem i WHERE c.C_CUSTKEY=o.O_CUSTKEY and o.O_ORDERKEY=i.L_ORDERKEY") customerPartDf.show() customerPartDf1=customerPartDf.rd
然后直接使用groupByKey方法得到rdd2
customerPartDf2 = customerPartDf1.groupByKey()
这时候其实已经完成了group操作,但是使用时发现显示有错误
customerPartDf2.show()

这是因为并没有直接对rdd进行group操作,而是做了一个操作标记,所以并未直接显示操作结果,但在后面的操作中可以发现group成功
customerPartDf3 = customerPartDf2.mapValues(list) print(customerPartDf3.collect())
![]()
可以看到group操作成功
转换成dataframe的效果是
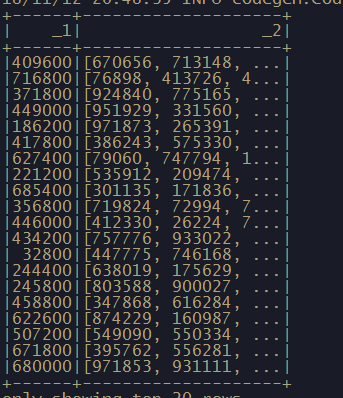
标题栏又消失了,不过下面的算法暂时用不到,所以先放,遇到的时候再研究
另外一开始用的是reduceByKey,后来发现好像是计数功能
Pandasgroup操作:https://blog.csdn.net/youngbit007/article/details/54288603