1.本周学习总结(0--2分)
1.1思维导图
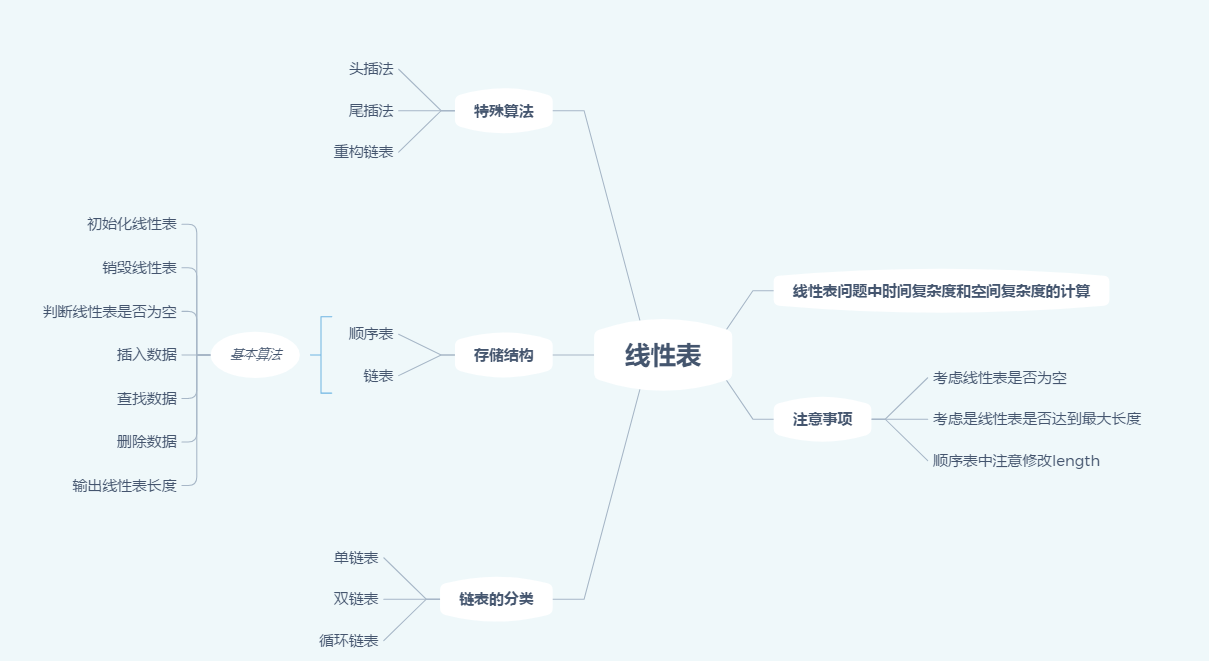
1.2.谈谈你对线性表的认识及学习体会。
1.线性表的内容上了三星期的课,相对来说内容比较丰富,尤其是链表方面,包含单链表,双链表和循环链表。作为第一部分的编程内容,线性表的内容比较简单同时比较基础,需要重点掌握。尤其是头插法和尾插法,后面学习的栈和队列都需要大量运用。
2.本次的pta作业相对比较简单,同时大部分题目书本上都有,可以查阅书籍。编程方面,算法的时间复杂度有待提升,上课中讲解了很多新的算法,比如链表的重构,使用哈希数组把算法的时间复杂度降为O(n)。
3.在时间分配需要提升,第四周因为要写实验报告什么的占用了很长时间竟然一行代码都没有打,一节网课都没看,需要重新分配时间,加大投入。
2.PTA实验作业(6分)
2.1.题目1:6-3 jmu-ds- 顺序表删除重复元素
2.1.1设计思路(伪代码)
void CreateSqList(List &L,int a[],int n)//用于创建顺序表,并对顺序表赋值
{
新建L
int i用于赋值L中的元素
for i=0 to i=n-1
{
把a[i]赋值给L->data[i]
}
L->length=n;
}
void DelSameNode(List &L) //删除重复的元素
{
int i用于获取顺序表中L->data[i]的元素,k=0用于获取重构顺序表中的长度
定义一个hash静态数组
for i=0 to i=L-length-1
{
把 hash数组中的hash[L->data[i]] 加一用于表示该数据出现过的次数
if出现过一次就在新的重构数组中加上该元素,同时k++用于统计长度便于赋值
}
L->length=k;
}
void DispSqList(List L)//输出顺序表
{
int i;
if顺序表为空则结束
for i=0 to L->length
{
输出L->data[i]
当元素不是最后一个的时候输出空格
}
}
2.1.2代码截图(注意,截图,截图,截图。不要粘贴博客上。)

2.1.3本题PTA提交列表说明。


- Q1:本道题一开始没有对空表进行判断
- A1:
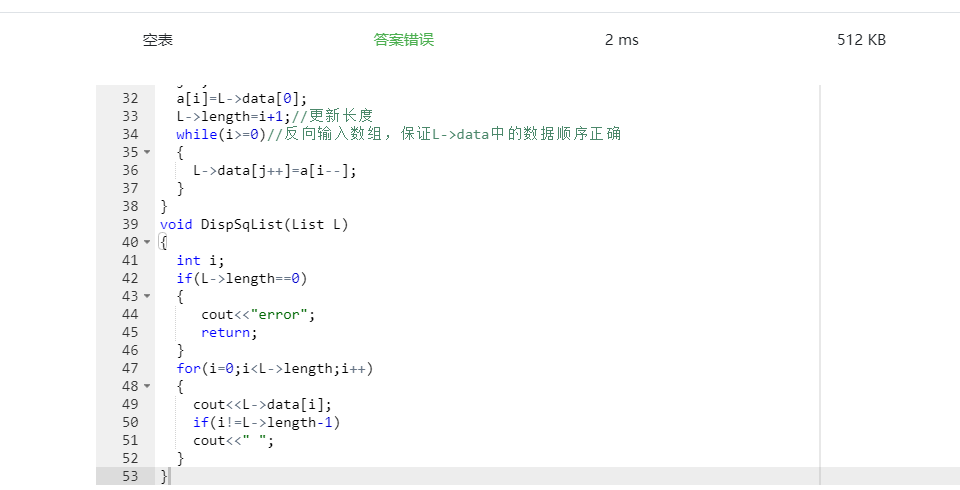 代码中没有对空表进行判断导致结果出错,修改后仍然出错
代码中没有对空表进行判断导致结果出错,修改后仍然出错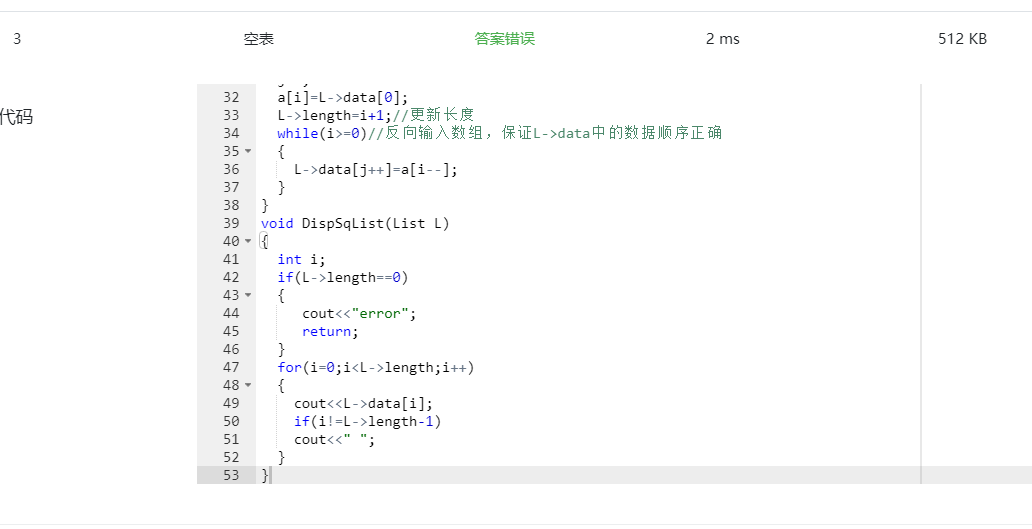 ,重新审题,发觉题目没有对空表有要求,当空表时直接return;结束程序。
,重新审题,发觉题目没有对空表有要求,当空表时直接return;结束程序。 - Q2:算法效率不高
- A2:原代码中的删除操作为
 可以看出代码执行效率不高,用一个新的数组储存空间,空间利用率不高,同时算法的时间复杂度为O(n的平法),时间复杂度大。根据老师上课所讲的内容设计hash数组解决问题。
可以看出代码执行效率不高,用一个新的数组储存空间,空间利用率不高,同时算法的时间复杂度为O(n的平法),时间复杂度大。根据老师上课所讲的内容设计hash数组解决问题。 - Q3:运用hash数组的做法,运行结果中出现多种错误
- A3:经过代码检查,发现自己在一个小细节上出现错误
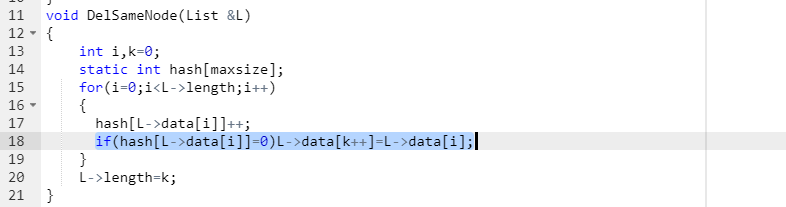 图中蓝色部分正是错误,打代码的时候要多加细心,对所用条件要有清晰的认识。
图中蓝色部分正是错误,打代码的时候要多加细心,对所用条件要有清晰的认识。
反思:本道题的代码并不复杂,但是我却出现了很多小错误,同时算法设计上也有很多冗余,一开始对这道题的要求把握得不好,一开始设计代码的时候有想到用hash数组的做法,但是却没有在一开始运用,原因是hash数组运用得少,同时担心顺序表输出的时候会出现逆序输出的情况,总体而言,思维比较混乱。
2.2.题目2:6-8 jmu-ds-链表倒数第m个数
2.2.1设计思路(伪代码)
int Find(LinkList L, int m )//查找元素
{
如果链表为空
return -1
定义 i用于统计先行指针前进的次数
定义先行指针first为链表L的表头和后行指针second为链表L的第一个节点
for i=0 to i=m-1//用于获得倒数的位置
{
first前进
如果first为空说明链表长度小于所求长度
返回-1
}
while(first没有走到表尾)
{
first向后移动
second向后移动
}
return second->data;
}
2.2.2代码截图

2.2.3本题PTA提交列表说明
- Q1:出现段错误
- A1:原因开始设计算法时没有对指针进行赋值导致段错误。
- Q2:在位置无效的时候出现错误
- A2:
 从图中我们可以看到,最后返回的数据是L->data,原本的思路是通过h求得总长度,获取i的数值,然后计算出倒数第几个数的位置,然而这样会出现一个问题,当L为空表时,就会出现段错误。同时m可能大于链表的长度,出现无效的数据。
从图中我们可以看到,最后返回的数据是L->data,原本的思路是通过h求得总长度,获取i的数值,然后计算出倒数第几个数的位置,然而这样会出现一个问题,当L为空表时,就会出现段错误。同时m可能大于链表的长度,出现无效的数据。 - Q3:解决了Q2中的问题代码基本正确,但是运行效率不高,必须遍历两遍链表。
- A3:根据老师上课所讲的内容,重新设计代码,大致思路是分为两个指针,前一个指针前先前进m次,后面的指针再前进,当前面的指针达到文件尾时,后面指针的数据就是所要求得倒数的数据。
- Q4:代码设计完之后再正常数据的时候出现错误
- A4:
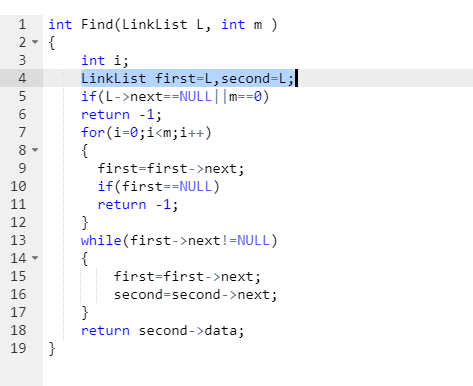 ,如图蓝色部分所示,second是从L开始行走的,L不是链表的第一个节点,导致最后first到达链表尾部的时候second没有达到既定位置,出现错误。
,如图蓝色部分所示,second是从L开始行走的,L不是链表的第一个节点,导致最后first到达链表尾部的时候second没有达到既定位置,出现错误。
反思:本题思路灵活,在设计算法的时候对不合法数据考虑不周全导致出现很多错误,在使用双指针的时候没有画图,出现混乱,打代码的时候最好先画图,以免发生错误。
2.3.题目3:6-9 jmu-ds-有序链表合并
2.2.1设计思路(伪代码)
void MergeList(LinkList &L1,LinkList L2)
{
用指针r1,r2分别表示L1和L2中的第一个节点。
用h表示L1的头节点用于重构数组。
while(r1!=NULL&&r2!==NULL)
{
if(r1->data<r2->data)
{
用尾插法把r1插入链表h中
r1=r1->next;
}
else
{
用尾插法把r2插入链表h中
r2=r2->next
}
while(r1不为空且r1中的数据和h中的数据重复)
{
r1=r1->next;
}
while(r2不为空且r2中的数据和h中的数据重复)
{
r2=r2->next;
}
}
if(r2==NULL)
{
h->next=r1;
}
else
{
h->next=r2;
}
}
2.3.2代码截图

2.3.3本题PTA提交列表说明
- Q1:数据中出现重复数据时无法删除重复数据。
- A1:审题时没有认真,没有考虑到重复数据出现的情况,添加了while循环用于除去重复数据。


- Q2:很明显,上面的代码虽然通过了测试,但是却有很大的冗余,while循环太多次,算法的执行效率低。
- A2:分析代码,发现代码重复的部分可以省略,比如if(r1NULL||r2NULL){break;}和while(r1!=NULL&&r2!NULL)重复了,while语句也可以通过修改条件把循环外的的循环给消除掉。删除if(r1NULL||r2NULL){break;} 使用while(r1!=NULL&&r1->datah->data)代替while(r1->data==L_->data)可以在r1为空时不会直接跳出循环,而直接进行原循环外的重复数据删除操作。
反思:老师在课堂上讲过这一题,认为这是有序表,本题中单个有序表中不会存在重复数据。我的算法就是用来处理单个链表中出现重复数据的情况。本算法中一开始设计的时候变量名不规范,冗余度高需要改进的地方很多。打代码应该多思考,尽可能地简化算法。
3、阅读代码
3.1 题目
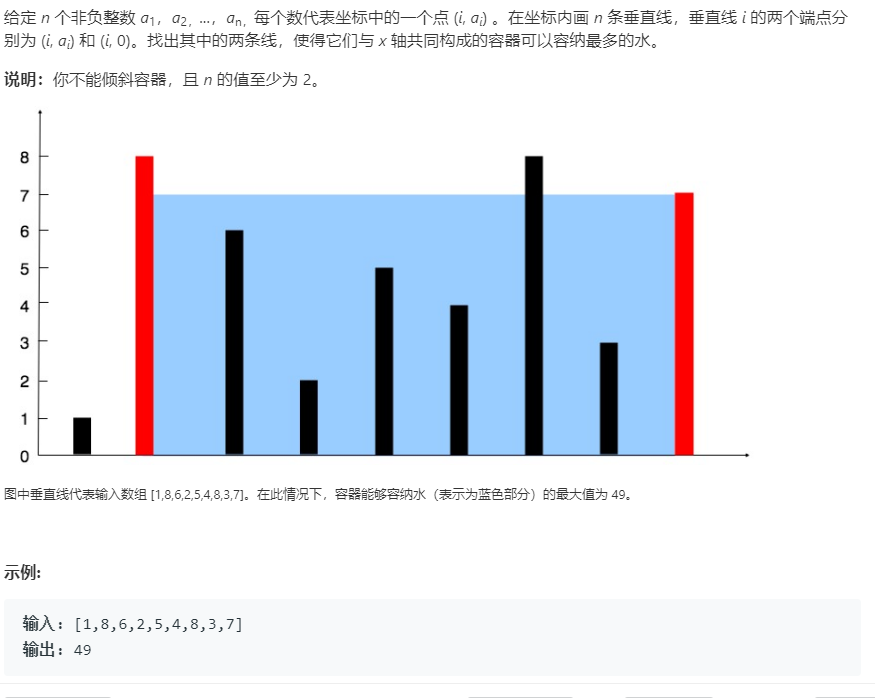
给定 n 个非负整数 a1,a2,...,an,每个数代表坐标中的一个点 (i, ai) 。在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0)。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
说明:你不能倾斜容器,且 n 的值至少为 2。
3.2 解题思路
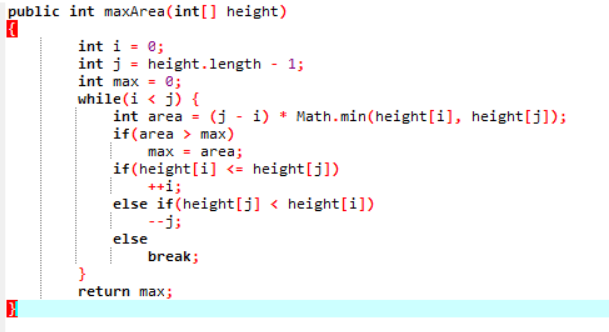
一般人看到上面的代码,会觉得这个题目很复杂,求水量既和长度有关又和最小高度有关,如果通过暴力解法一个一个去尝试,代码的执行效率不高。本题中,作者开阔思路,既然要求水量,那么有一点可以确定,容器的宽度越大,高度越高,那么容器的容积也就越大。不妨设变量i,j从两边出发,如果height[i] <= height[j]那么i++,如果height[j] < height[i],j--,当数据非法或者i>=j时退出程序,记录每一次容积的大小,在最后输出最大容积,这样数据只需要遍历一次,时间复杂度为O(n)
3.3 代码截图
3.4 学习体会
1.本题目来自力扣, 力扣链接。
2.算法需要不断简化,本题中很容易设计出暴力解法,用两个for循环设计出算法,把所有可能计算出来得出结果。因为题目对时间有要求,暴力解法不能通过。
3.上面的代码作者有一定疏忽,比如后面的else break;可以通过改变条件省略掉,算法可以设计成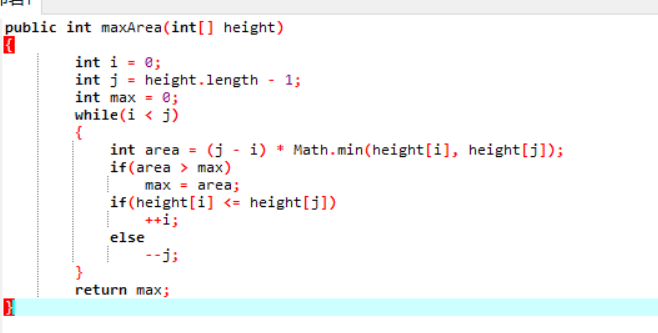
4.本题的解法丰富运用不同编程语言代码的复杂度不同,另我惊讶的是使用Javascript居然可以只用一个return设计算法。