List接口
介绍
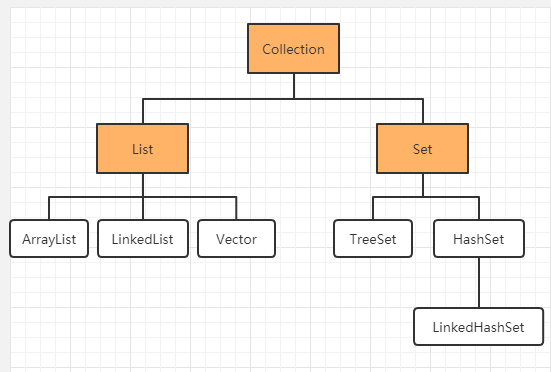
java.util.List 接口继承自 Collection 接口 ,是单列集合中的一个重要分支。
- 允许出现重复元素
- 线性存储,有索引
- 有序,存入和取出的顺序是一致的
特有方法
| 方法 | 描述 |
|---|---|
| void add(int index, E element) | 将指定的元素插入此列表中的指定位置(可选操作)。 |
| E get(int index) | 返回此列表中指定位置的元素。 |
| E remove(int index) | 删除该列表中指定位置的元素(可选操作)。 |
| E set(int index, E element) | 用指定的元素(可选操作)替换此列表中指定位置的元素。 |
测试代码
package collection;
import java.util.ArrayList;
import java.util.List;
/**
* 测试list接口的几个特有方法
* 有序,与index相关的常用方法
*/
public class TestList {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
System.out.println(list);
list.add("A");
list.add("B");
list.add("C");
System.out.println(list);
list.add(1, "a");
System.out.println(list);
System.out.println("删除元素"+list.remove(0));
System.out.println(list);
System.out.println("被替换的元素" + list.set(0, "A"));
System.out.println(list);
}
}
结果
[]
[A, B, C]
[A, a, B, C]
删除元素A
[a, B, C]
被替换的元素a
[A, B, C]
注意下标越界跟数组一样
List子类
ArrayList集合
java.util.ArrayList 是可调整大小的数组的实现List接口
元素增删慢,查找快,满足日常开发中实现查询数据、遍历数据等功能
但不意味着随意使用ArrayList完成任何需求,当频繁增删数据时,效率极低。
底层原理
数据存放在Object类型的数组中:
transient Object[] elementData; // non-private to simplify nested class access
既然是数组,那它是怎样实现自动扩容的呢?
以ArrayList 的add方法源码举例
// 在添加数据之前,确保容量充足
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
// 确定具体容量 -> 计算容量
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
// 如果列表为空,返回默认容量 DEFAULT_CAPACITY = 10,否则返回最小容量
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
// 如果最小容量小于数组长度,则给数组扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
// 扩容过程,旧容量 = 原数组长度,新容量 = 扩容1.5倍
// 如果新容量小于最小容量,新容量=最小容量
// 如果新容量 大于 最大数组大小 Integer.MAX_VALUE - 8
//总之用数组存储是不可能无限增长,超过21亿多就抛出内存溢出异常
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
// 最后调用工具类Arrays的复制方法,将原数组的数据复制到一个新的数组
Arrays.java
public static <T> T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,Math.min(original.length, newLength));
return copy;
}
// 底层还是调用了系统级的复制数组方法
// 本地方法
public static native void arraycopy(Object src, int srcPos,Object dest, int destPos,int length);
注意
ArrayList的实现不是同步的,存在线程安全问题。
LinkedList集合
特点
- 底层用链表结构:查询慢,增删快
- 包含大量操作首尾元素的方法
- 使用特有方法时不要用多态
底层
用双向链表存储数据
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
继承 AbstractSequentialList 类
实现了很多接口
- List 列表的相关操作
- Queue
- Deque 队列
- Cloneable 克隆
- Serializable 序列化,用于网络传输
public class LinkedList<E>extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable{}
public interface Deque<E> extends Queue<E> {}

Java LinkedList(链表) 类似于 ArrayList,是一种常用的数据容器。
与 ArrayList 相比,LinkedList 的增加和删除对操作效率更高,而查找和修改的操作效率较低。
以下情况使用 ArrayList :
- 频繁访问列表中的某一个元素。
- 只需要在列表末尾进行添加和删除元素操作。
以下情况使用 LinkedList :
- 你需要通过循环迭代来访问列表中的某些元素。
- 需要频繁的在列表开头、中间、末尾等位置进行添加和删除元素操作。
特有方法
| 方法 | 描述 |
|---|---|
| void addFirst(E e) | 在该列表开头插入指定的元素。 |
| void addLast(E e) | 将指定的元素追加到此列表的末尾。 |
| void push(E e) | 将元素推送到由此列表表示的堆栈上。 |
| E getFirst() | 返回此列表中的第一个元素。 |
| E getLast() | 返回此列表中的最后一个元素。 |
| E peek() | 检索但不删除此列表的头(第一个元素)。 |
| E peekFirst() | 检索但不删除此列表的第一个元素,如果此列表为空,则返回 null 。 |
| E peekLast() | 检索但不删除此列表的最后一个元素,如果此列表为空,则返回 null 。 |
| E poll() | 检索并删除此列表的头(第一个元素)。 |
| E pollFirst() | 检索并删除此列表的第一个元素,如果此列表为空,则返回 null 。 |
| E pollLast() | 检索并删除此列表的最后一个元素,如果此列表为空,则返回 null 。 |
| E removeFirst() | 从此列表中删除并返回第一个元素。 |
| E removeLast() | 从此列表中删除并返回最后一个元素。 |
| E pop() | 从此列表表示的堆栈中弹出一个元素。 |
Vector
所有单列集合的祖先,Java 1.0版本就已经发布!
Java1.2版本之后,ArrayList取代了Vector。
Vector 类实现了一个动态数组。和 ArrayList 很相似,但是两者是不同的:
- Vector 是同步访问的。
- Vector 包含了许多传统的方法,这些方法不属于集合框架。
Set接口
java.util.Set 接口继承自 Collection 接口 ,也是单列集合中的一个重要分支。
- 不允许存储重复的元素
- 没有索引!没有带索引的方法,方法和Collection一样
- 不能用普通for循环遍历,增强for可以
Set子类
HashSet集合
java.util.HashSet 集合实现 Set 接口
特点
- 不重复
- 无序
- 无索引
底层
HashTable 查询速度非常快
public class HashSet<E>extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}
}
测试代码
import java.util.HashSet;
import java.util.Iterator;
public class TestHashSet {
public static void main(String[] args) {
HashSet<String> set = new HashSet<>();
System.out.println(set.add("a"));
System.out.println(set.add("a"));
System.out.println(set.add("b"));
System.out.println(set.add("c"));
System.out.println("========迭代器=======");
Iterator<String> it = set.iterator();
while (it.hasNext()) {
System.out.print(it.next() + " ");
}
System.out.println("
========增强for=======");
for (String s : set) {
System.out.print(s + " ");
}
}
}
结果
true
false
true
true
========迭代器=======
a b c
========增强for=======
a b c
Hash值
一个十进制的整数,由系统随机给出。
可以视为模拟对象存储的逻辑地址,而不是数据实际存储的物理地址。
Object祖宗类中就提供获取hash值的方法hashCode() ,hashCode调用了
public native int hashCode();
对具体实现感兴趣的请转至传送门
哈希码的通用约定如下:
- 在java程序执行过程中,在一个对象没有被改变的前提下,无论这个对象被调用多少次,hashCode方法都会返回相同的整数值。对象的哈希码没有必要在不同的程序中保持相同的值。
- 如果2个对象使用equals方法进行比较并且相同的话,那么这2个对象的hashCode方法的值也必须相等。
- 如果根据equals方法,得到两个对象不相等,那么这2个对象的hashCode值不需要必须不相同。但是,不相等的对象的hashCode值不同的话可以提高哈希表的性能。
Hash表
查询快!
JDK 1.8 之前,哈希表 = 数组 + 链表
JDK 1.8 之后
- 哈希表 = 数组 + 链表
- 哈希表 = 数组 + 红黑树
- 红黑树在数量大时提高查询速度
Hash表的底层
数组结构:把元素分组,相同哈希值的放到一起,用链表或红黑树保存
当链表长度超过8位,将链表转为红黑树
初始容量为16
存储数据到集合的过程

HashSet的底层
就是HashMap !!
https://blog.csdn.net/HD243608836/article/details/80214413
HashMap明天再补