前言
数据文件是非常强大的方式使用不同的测试数据来测试我们的API,以检查它们是否在各种情况下都能正常运行。我们可以认为数据文件是“Collection Runner”中每个请求的参数。下面,通过一个例子来说明如何使用数据文件。
这篇文章需要结合下面两个文件进行说明,请分别下载:
在Postman中导入集合文件。导入成功后,有一个只有一个Post请求的集合。打开这个集合中的请求,我们会发现这个请求有两个变量,分别是请求URL中的path和请求体中的value,它们就像和环境变量一样被使用。这次,我们将通过使用数据文件,给这些变量赋值。再打开该请求的测试脚本,我们会发现在脚本中使用了data指定的数据。这个data在脚本中本身并没有定义。Postman沙箱从我们在设置集合运行的配置参数中选择的JSON/CSV文件初始化数据变量。
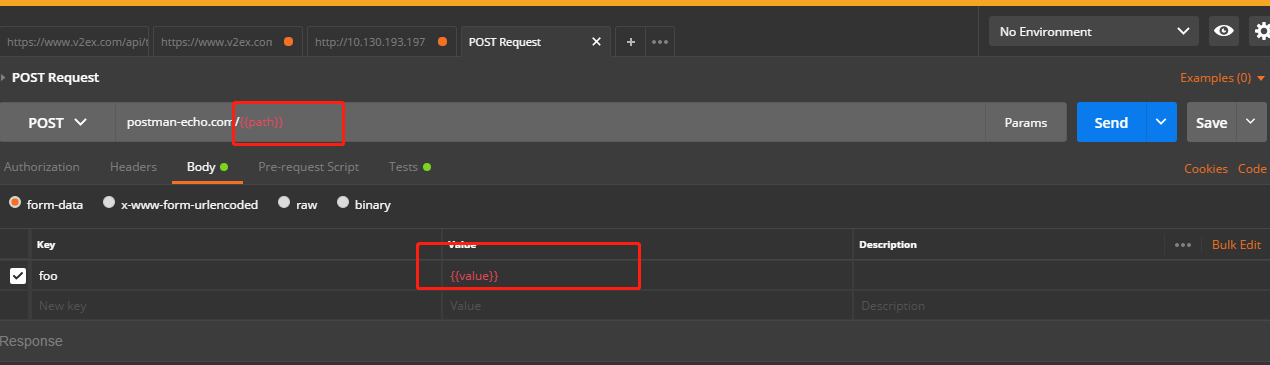
使用案例
下面演示在“Collection Runner”使用数据文件。我们先看看数据文件,Postman目前支持JSON和CSV两种格式的文件。在本文中对应的数据JSON文件像下面这样:
[{
"path": "post",
"value": "1"
}, {
"path": "post",
"value": "2"
}, {
"path": "post",
"value": "3"
}, {
"path": "post",
"value": "4"
}]这是一个对象数组。每个对象表示一次迭代的变量值。这个对象的每个成员都代表一个变量。这样,在第一次迭代中,路径的变量将被赋值为post,并且请求体中的value将被赋值为1。同样,在第二次迭代中,路径的变量将被赋值为post,并且请求体中的value将被赋值为2。
数据文件也可以是CSV。示例CSV看起来像这样:
path, value
post, 1
post, 2
post, 3
post, 4在典型的CSV方式中,第一行表示所有变量名称,后续行表示每次迭代时这些变量的值。对于第一次迭代,路径值为post,请求体值为1。对于第二次迭代,路径值仍然为post,但请求体值为2。
请注意,“Collection Runner”的每一次运行只能选择一个数据文件。
现在我们已经了解如何构建数据文件,接下来我们将该数据文件提供给“Collection Runner”。在运行器中单击选择文件,然后选择其中一个文件。我们还可以通过单击文件名旁边的预览来预览每个变量,以及每个变量的值。如下图所示:
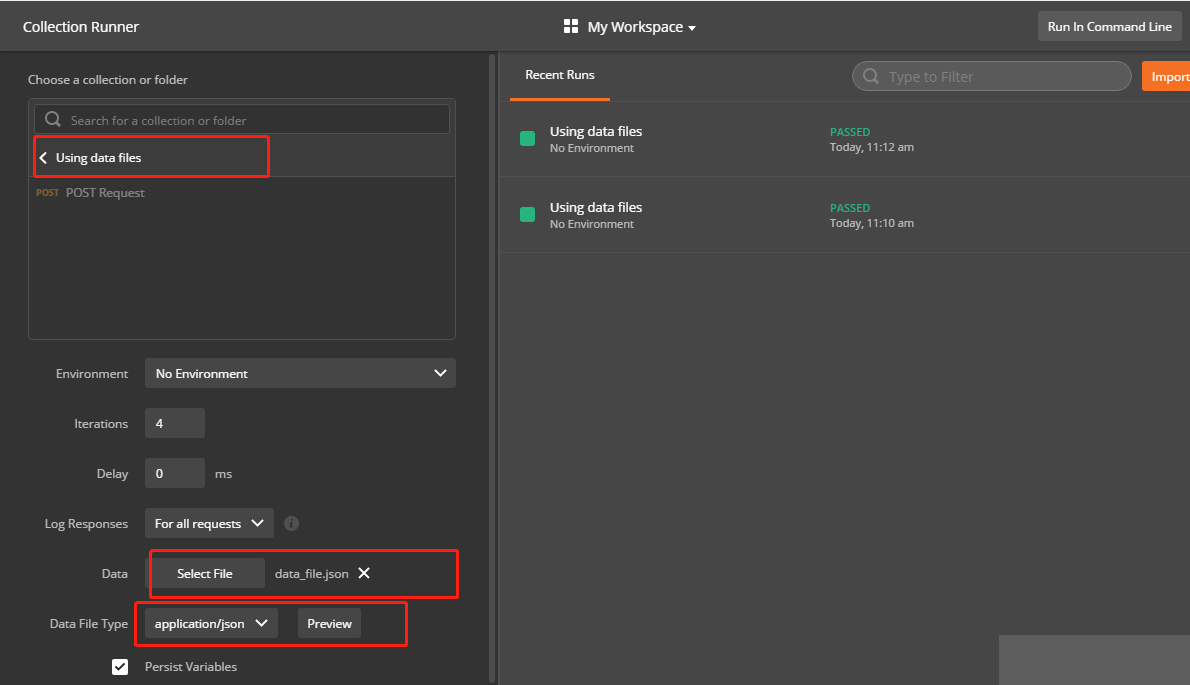
现在我们可以运行我们的集合。我们会看到所有的测试都通过了。如果打开请求调试工具并展开请求正文,则会看到变量{{value}}已被数据文件中对应的值所代替。实际上,对于不同的迭代,这个值是不同的。这样,我们已经向我们的API使用了不同的数据进行测试,并确保它可以针对每种情况都能够正确工作。

我们再来看看我们的测试脚本。变量数据是从数据文件中获取的。随着每次迭代,它的值都会从我们数据文件中获取对应的值。所以,我们可以通过API返回的值与我们在数据文件中设定的期望值进行比对,如果值一致,则认为测试通过;反之则测试不通过。
不仅仅在前置请求和测试脚本之中,数据变量可以在所有可以使用环境变量的地方使用,方式完全相同。
参考:https://www.jellythink.com/archives/187