MySQL 的数据管理
外键(了解即可)
创建外键
- 方式一 创建表时
CREATE TABLE IF NOT EXISTS `student`(
`gradeid` INT(10) NOT NULL COMMENT '学生年级',
KEY `FK_gradeid`(`gradeid`),
CONSTRAINT `FK_gradeid` FOREIGN KEY (`gradeid`) REFERENCES `grade`(`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
- 方式二 修改表时
ALTER TABLE `student`
ADD CONSTRAINT `FK_gradeid` FOREIGN KEY(`gradeid`) REFERENCES `grade`(`id`)
删除有外键关系的表,必须要先删除被引用的表 eg:删除student ,删除grade
以上操作都是物理主键,数据库级别的外键,所以不建议使用!
最佳实践
-
数据库就是单纯的表,只是用来存放行和列
-
如果想使用外键,程序实现
DML操作语言(☆)
添加
-- 插入单值
INSERT INTO `grade`(`name`) VALUES('大一')
-- 插入多值
INSERT INTO `grade`(`name`) VALUES('大二'),('大三')
修改
UPDATE `student` SET `name`='Jane' WHERE `id`= 1;
删除
delete from
DELETE FROM`student` WHERE `name` = 'Jane';
truncate
完全清空数据库表,表的结构和索引不会发生改变
TRUNCATE `student`
delete 和 truncate的区别
同:都可以删除数据
不同:
- truncate 重置自增列
- truncate不会影响事务
DQL查询数据(☆)
语法
注意:每一个条件的顺序不能变
SELECT [DISTINCTI]
{*|table.field...}
FROM table_name [as table_alias]
[left | right | inner join table_name2] -- 联合查询
[WHERE,.] -- 指定结果需满足的条件
[GROUP BY..] -- 指定结果按照哪几个字段来分组
[HAVING] -- 过滤分组的记录必须满足的次要条件
[ORDER BY table.feild asc|desc] -- 指定查询记录按一个或多个条件排序
[LIMIT Offset] --分页
单表查询
SELECT * FROM student;
SELECT StudentNO AS '学号',StudentName AS '姓名' FROM student AS s;
-- concat 拼接函数
SELECT CONCAT(StudentNO,' ',StudentName ) AS '拼接' FROM student;
SELECT DISTINCT StudentNo FROM result;
-- 查询版本号
SELECT VERSION()
-- 计算
SELECT 3*8+4
如果列的名字,不是那么见名知意,就需要as取别名。
where 条件子句
逻辑运算符
and or not
-- !=
SELECT * FROM student WHERE NOT StudentNo=1000;
模型查询
| 运算符 | 语法 |
|---|---|
| between | a between 15 and 20 |
| not null | a is not null |
| like | **a like b ** %任意个字符,_一个字符(一个中文字符也是一个字符) |
| in | a in (a1,a2,a3) 是具体的值,不能是%_ 比如'张%' |
SELECT studentname FROM student WHERE address IN ('上海徐家汇','北京');
联表查询
分析思路:
-
分析需求:用到哪些表
-
确定:join方式
-
连接点
-
判断条件
-- 交集
SELECT COUNT(*)
FROM student AS s
INNER JOIN result AS r
on s.`StudentNo`=r.`StudentNo`;
-- 等价于
SELECT COUNT(*)
FROM student AS s,result AS r
WHERE s.`StudentNo`=r.`StudentNo`;
-- 多表连接
SELECT student.`StudentName`,`subject`.`SubjectName`,result.`StudentResult`
FROM result
INNER JOIN student
ON student.`StudentNo` = result.`StudentNo`
INNER JOIN `subject`
ON `subject`.`SubjectNo`=result.`SubjectNo`
-- 右连接
SELECT COUNT(*)
FROM student AS s
RIGHT JOIN result AS r
ON s.`StudentNo`=r.`StudentNo`;
-- 左连接
SELECT COUNT(*)
FROM student AS s
LEFT JOIN result AS r
ON s.`StudentNo`=r.`StudentNo`;
--查询没有参加过考试的同学
SELECT COUNT(*)
FROM student AS s
LEFT JOIN result AS r
ON s.`StudentNo`=r.`StudentNo`
WHERE r.`StudentResult` IS NULL
自连接
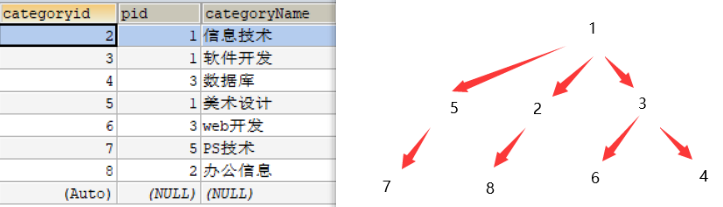
-- 查询父子关系
SELECT parent.`categoryName` AS '父栏目',child.`categoryName` AS '子栏目'
FROM `category` AS parent, `category` AS child
WHERE parent.`categoryid`=child.`pid`;
分页和排序
分页的好处
缓解数据库压力,给用户更加好的体验
--asc 升序(默认) desc 降序
ORDER BY result.`StudentResult` DESC
limit 0,5;
第n页 (n-1)*page_size,page_size
多表查询
查询大一有哪些学生
连接查询
SELECT studentname
FROM student
INNER JOIN grade
ON student.`GradeID`=grade.`GradeID`
WHERE gradename LIKE '大一'
子查询
SELECT studentname
FROM student
WHERE student.`GradeID`=
(
SELECT grade.`GradeID` FROM grade WHERE grade.`GradeName` LIKE '大一'
);
查询 名字中有“小”的同学几门的高等数学成绩
连接查询和子查询结合
SELECT sub.`SubjectName`,r.`StudentResult`
FROM `subject` sub
INNER JOIN result r
ON sub.`SubjectNo`=r.`SubjectNo`
WHERE r.`studentno` IN (
SELECT student.`StudentNo` FROM student WHERE student.`StudentName` LIKE '%小%'
) AND sub.`SubjectName` LIKE '%高等数学%'
聚合函数
count(字段)(会忽略null值)
count(*) (不会忽略null值) 本质:计算行数
-- 查询学生人数
SELECT COUNT(student.`StudentNo`) FROM student
SELECT SUM(result.`StudentResult`) AS '总和'
FROM result WHERE result.`SubjectNo`=1;
SELECT AVG(result.`StudentResult`) AS '平均分'
FROM result WHERE result.`SubjectNo`=1;
SELECT MAX(result.`StudentResult`) AS '最大值'
FROM result WHERE result.`SubjectNo`=1;
SELECT MIN(result.`StudentResult`) AS '最小值'
FROM result WHERE result.`SubjectNo`=1;
查询几分高等数学的平均分(且平均分大于75)
SELECT subject.`SubjectName`,result.`SubjectNo`,AVG(result.`StudentResult`)
FROM result
INNER JOIN `subject`
ON result.`SubjectNo`=`subject`.`SubjectNo`
WHERE subject.`SubjectName` LIKE '高等数学%'
GROUP BY result.`SubjectNo`
HAVING AVG(result.`StudentResult`)>75;
分组的条件只能写在having 中
md5加密
存在一个md5()函数
破解网站的原理:存了前和后去比较
pwd=md5(pwd)
事务
什么是事务
经典例子:银行转账
A给B转账200,A10000->200 B 0
B收到A, A800 B 0->200
将一组SQL放在一个批次中去执行
事务原则:ACID
原子性、一致性、隔离性、持久性(原子歌词)
- 原子性:要么都成功,要么都失败
- 一致性:操作前后的状态是一致(前后都是1000元)
- 持久性
- 事务如果提交成功,持久化到数据库
- 事务没有提交成功,恢复到原状
- 事务一旦提交就不可逆了
- 隔离性:
多个用户不会互相影响
事务隔离的级别
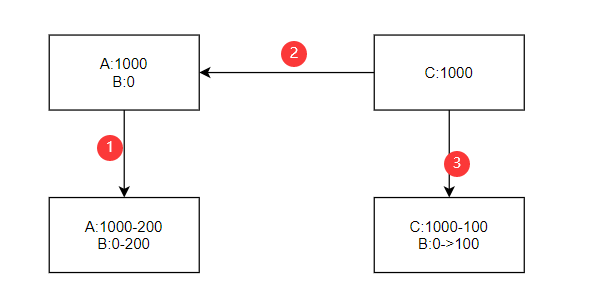
脏读:一个事务读取了另外一个事务未提交的数据
C读取了B未提交的数据
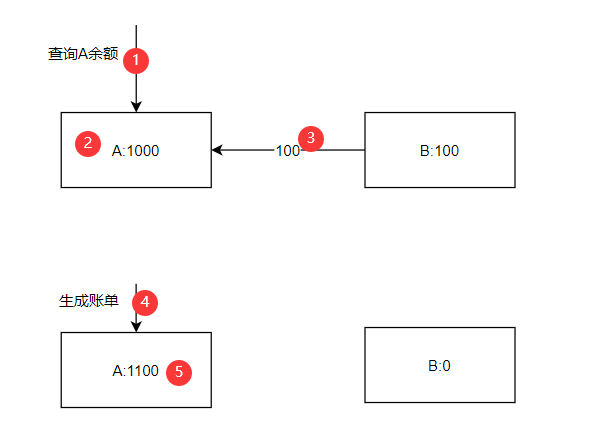
不可重复读:在一个事务读取表的一行数据,多次读取结果不同
(eg:事务中有两条都是查询A)
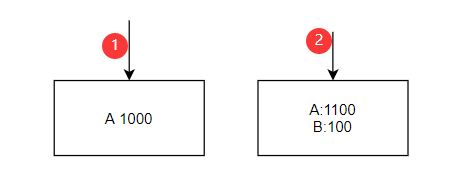
幻读
在一个事务内读取到别的事务插入的数据,导致前后读取不一致
(eg:事务中有两条都是查询A)
-- mysql 是默认开启事务自动提交的
SET autocommit = 0 -- 关闭自动提交
START TRANSACTION -- 事务开始
-- 标记一个事务的开始,从这个之后sql语句都在一个事务内
-- .....
COMMIT -- 提交
ROLLBACK -- 回滚
SET autocommit = 1 -- 开启自动提交
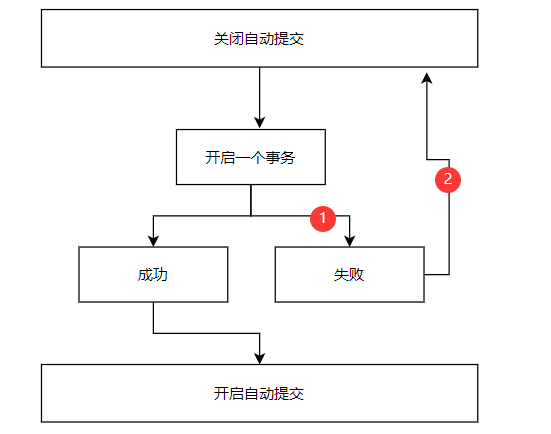
模拟用户转账
CREATE DATABASE IF NOT EXISTS shop
USE shop
CREATE TABLE `acount`(
`id` INT(3) AUTO_INCREMENT,
`name` VARCHAR(30),
`money` DECIMAL(9,2),
PRIMARY KEY(`id`)
)DEFAULT CHARSET=utf8
INSERT INTO acount VALUES(1,'A',2000),(2,'B',1000);
-- 转账:模拟事务提交
SET autocommit = 0;
START TRANSACTION ;
UPDATE acount SET money=money+200 WHERE NAME LIKE 'A';
UPDATE acount SET money=money-200 WHERE NAME LIKE 'B';
ROLLBACK;
COMMIT;
SET autocommit = 1;
索引
官网对索引的定义:index 是帮助mysql高效获取数据的数据结构
讲索引的博客:https://blog.codinglabs.org/articles/theory-of-mysql-index.html
索引的分类
- 主键索引(primary key)
- 唯一的标识,主键唯一且非空
- 唯一索引(unique key)
- 避免重复的列出现,一个表唯一索引可以有多个
- 常规索引(key/index)
- 默认的,index,key 关键字来设置
- 全文索引(full_text)
- 快速定位数据
--查看一个表的所有索引
SHOW INDEX FROM student
--添加一个全文索引(注意括号里面不能用student.`StudentName`)
ALTER TABLE `student` ADD FULLTEXT INDEX `fi_student_name`(`StudentName`);
--全文索引
EXPLAIN SELECT * FROM student WHERE MATCH(studentName) AGAINST('小');
加100 0000数据
DELIMITER $$ -- 写函数之前必须写
CREATE FUNCTION mock_data()
RETURNS INT
BEGIN
DECLARE num INT DEFAULT 1000000;
DECLARE i INT DEFAULT 0;
WHILE i<num DO
INSERT INTO app_user(`name`,`email`,`phone`,`gender`,`password`,`age`)
VALUES(
CONCAT('用户',i),'1014523451@163.com',
CONCAT('18', FLOOR(RAND()*(999999999-100000000)+100000000)),
FLOOR(RAND()*2),UUID(),FLOOR(RAND()*100)
);
SET i=i+1;
END WHILE;
RETURN i;
END;
SELECT mock_data()
CREATE INDEX id_app_user_name ON app_user(`name`);

索引原则
-
索引在小数据量不明显,在大的数据量明显
-
索引不是越多越好
-
索引一般加在常用来查询的字段上