相对于普通的LSTM实现的seq2seq模型,在编码器的区别就是传递的隐状态不同。附加Attention的模型会将编码器所有时刻的隐状态作为一个矩阵传入解码器。解码器的大致结构如图:
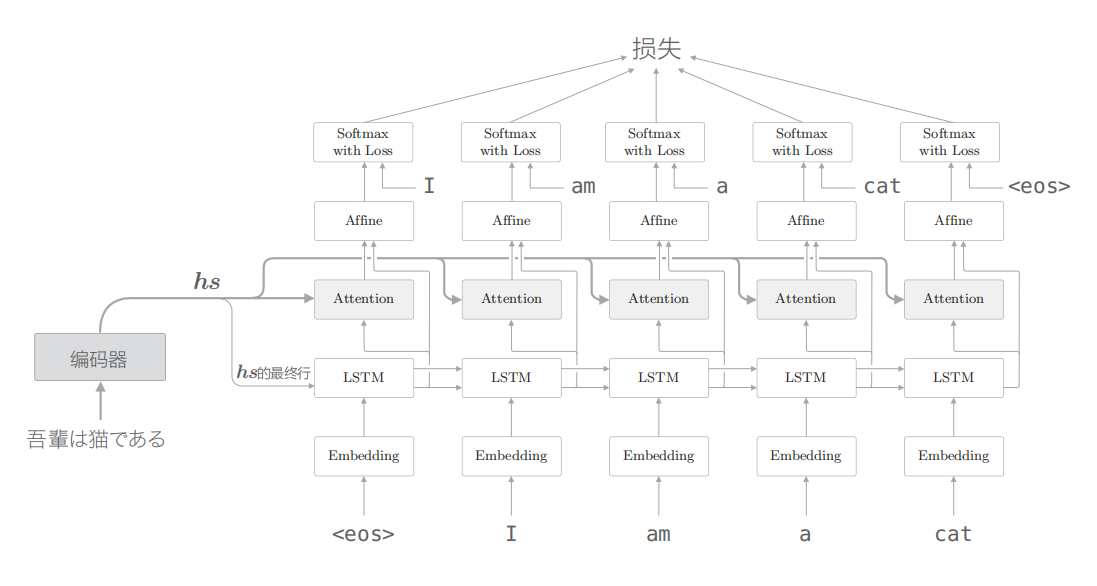
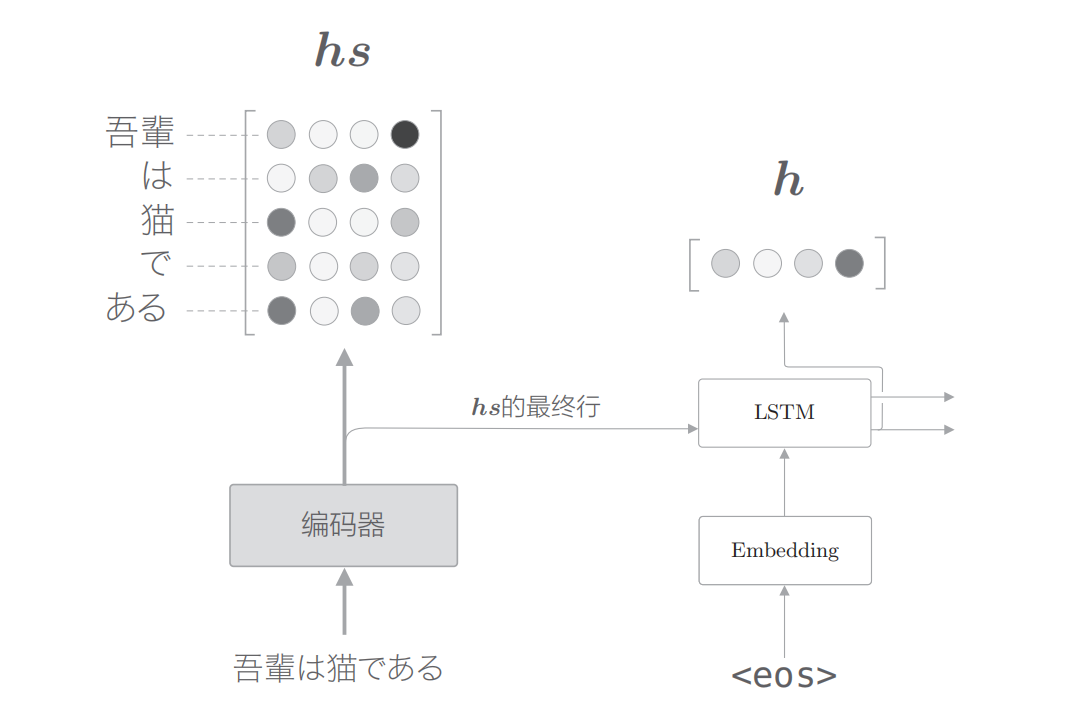
假设编码器传入的矩阵为hs,解码器某LSTM节点生成的向量为h。此时,我们的目标是用数值表示这个 h 在多大程度上和 hs 的各个单词向量“相似”。有几种方法可以做到这一点,这里使用最简单的向量内积。
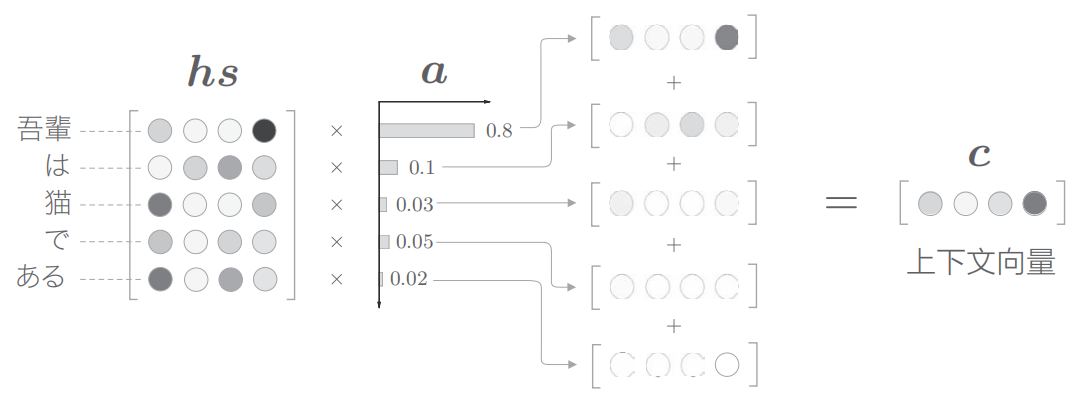
即是使用h向量与hs矩阵的行依次做内积然后softmax得到一个权重矩阵a。
得到a之后,按图示将其与hs矩阵的词向量相乘,得到的矩阵沿垂直方向相加,得到上下文向量c。这个上下文向量就是Attention的输出。
加深神经网络的技巧:残差网络
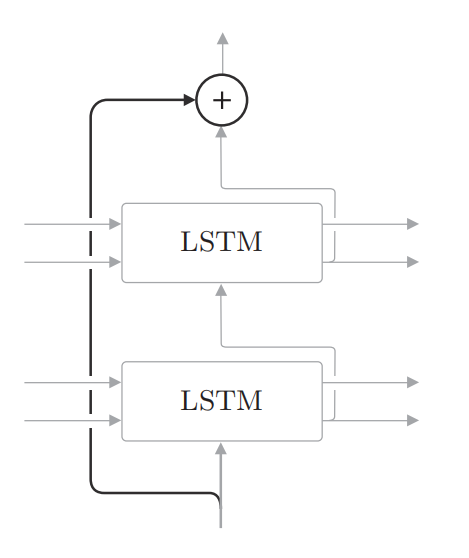
如图所示, 所谓残差连接, 就是指 “跨层连接”。此时, 在残差连 接的连接处, 有两个输出被相加。请注意这个加法 (确切地说, 是对应元素 的加法 ) 非常重要。因为加法在反向传播时 “按原样” 传播梯度, 所以残差连接中的梯度可以不受任何影响地传播到前一个层。这样一来, 即便加深了层, 梯度也能正常传播, 而不会发生梯度消失 (或者梯度爆炸 ), 学习可以顺利进行。
在时间方向上, RNN层的反向传播会出现梯度消失或梯度爆炸的问题。梯度消失可以通过 LSTM、GRU 等Gated RNN应对, 梯度爆 炸可以通过梯度裁剪应对。而对于深度方向上的梯度消失, 这里介绍的残差连接很有效。
self-attention 和 transformer 参考下面两个链接。
参考:
《深度学习进阶:自然语言处理》