原文链接:http://www.sqlservercentral.com/articles/Stairway+Series/72442/
SQL Server中的索引内部结构:到SQL Server索引级别10的阶梯
By David Durant, 2012/01/20
该系列
本文是楼梯系列的一部分:SQL Server索引的阶梯
索引是数据库设计的基础,并且告诉开发人员使用数据库非常了解设计人员的意图。不幸的是,当性能问题出现时,索引常常被添加为事后考虑。最后是一系列简单的文章,这些文章应该能让任何数据库专业人员迅速跟上他们的步伐
在以前的级别中,我们已经对索引采取了一种合乎逻辑的方法,重点是它们能为我们做什么。现在是时候采取物理方法,考察指标的内部结构了;为了理解索引内部性,可以理解索引开销。只有了解索引结构,以及它是如何维护的,才能理解和最小化索引创建、更改和删除的成本;以及行插入、更新和删除。
因此,从这个层次开始,我们将关注点扩大到包括索引的成本和索引的好处。毕竟,降低成本是利益最大化的一部分;最大化你的索引的好处就是这个楼梯的目的。
叶和叶水平
任何指数的结构都由叶级和非叶级组成。尽管我们从未明确地说过,所有以前的水平都集中在指数的叶级上。因此,它是一个聚集索引的叶级,即表本身;每个叶级条目都是表的一行。对于非聚集索引,它是包含每行一个条目的叶级(过滤后的索引除外);每个条目由索引键列组成,可选包含列和书签,其中要么是聚集索引键列,要么是RID(行ID)值。
索引项也称为索引行;无论它是表行(聚集索引叶级条目),都是指表行(非聚集索引页级),或指向较低级别的页面(非叶级别)。
非叶级别是构建在叶级之上的结构,它使SQL Server能够:
在索引键序列中维护索引的条目。
快速查找给定索引键值的叶级行。
在第1级,我们使用电话簿作为类比来解释索引的好处。我们的电话簿用户正在寻找“Meyer,Helen”,他知道条目会在任何排序的姓的中间,然后直接跳到白色页面的中间开始搜索。然而,SQL Server并没有这样的内在的英语语言的名称,或者其他任何数据。它也不知道哪个页面是“中间”页面,除非它从头到尾把整个索引都走了。因此,SQL Server在索引中构建了一些额外的结构。
非叶水平
该附加结构称为索引的非叶级别或节点级别;它被认为是建立在叶层之上,不管它的页面在哪里。它的目的是为SQL Server提供每个索引的单个页面入口点,以及从该页到包含任何给定搜索键值的页面的一个简短的遍历。
索引中的每一页,无论其级别如何,都包含索引行或条目。在页级页面中,正如我们反复看到的,每个条目都指向一个表行或者是表行。因此,如果该表包含10亿行,索引的叶级别将包含10亿个条目。
在叶级以上的水平,即最低的非叶层;每个条目指向一个叶级页面。如果我们的10亿条目索引平均每一页有100个条目,对于一个索引的搜索键包含几个数字、日期和代码列,这是一个现实的数字;然后,叶级将包含10 000,000,000 / 100 = 10,000,000页。反过来,最低的非叶级将包含10,000,000个条目,每个条目指向一个叶级页面,并且将跨越100,000页。
每个较高的非叶级都有页面,每个页面的条目都指向下一级的页面。因此,我们的下一个更高的非叶级别将包含100,000个条目,并有1000页大小。上面的级别包含1000个条目,大小为10页;上面的那一页只有一页上有10个条目;这就是它停止的地方。
位于索引顶部的唯一页面称为根页。位于根页级和叶级以上的索引的级别称为中间层。等级的编号从零开始,从叶级开始向上。因此,最低的中级水平总是1级。
非叶级条目只包含索引键列和指向较低级别页面的指针。包含的列只存在于叶级条目中;它们不在非叶级条目中。
除了根页面之外,索引中的每个页面都包含两个额外的指针。这些指针指向下一页和上一页,在索引序列中,在同一级别上。由此产生的双向链表使SQL Server能够以升序或降序的顺序扫描任何级别的页面。
一个简单的例子
下面的图1所示的简单图帮助说明了这种树状结构的索引。此图表示一个在理论人员的LastName / FirstName列上创建的索引。使用以下SQL:Employee表:
CREATE NONCLUSTERED INDEX IX_Full_Name
ON Personnel.Employee
(
LastName,
FirstName,
)
GO
图注:
指向页面的指针包括数据库文件号和页码。因此,指针值为5:4567指向数据库文件# 5的4567页。
大多数样本值已经从人身上取走了。在AdventureWorksdatabase中联系表。还增加了一些用于说明的目的。
卡尔·奥尔森是这个例子中最受欢迎的名字。有这么多的Karl Olsens,他们的条目跨越了一个完整的中间水平索引页。
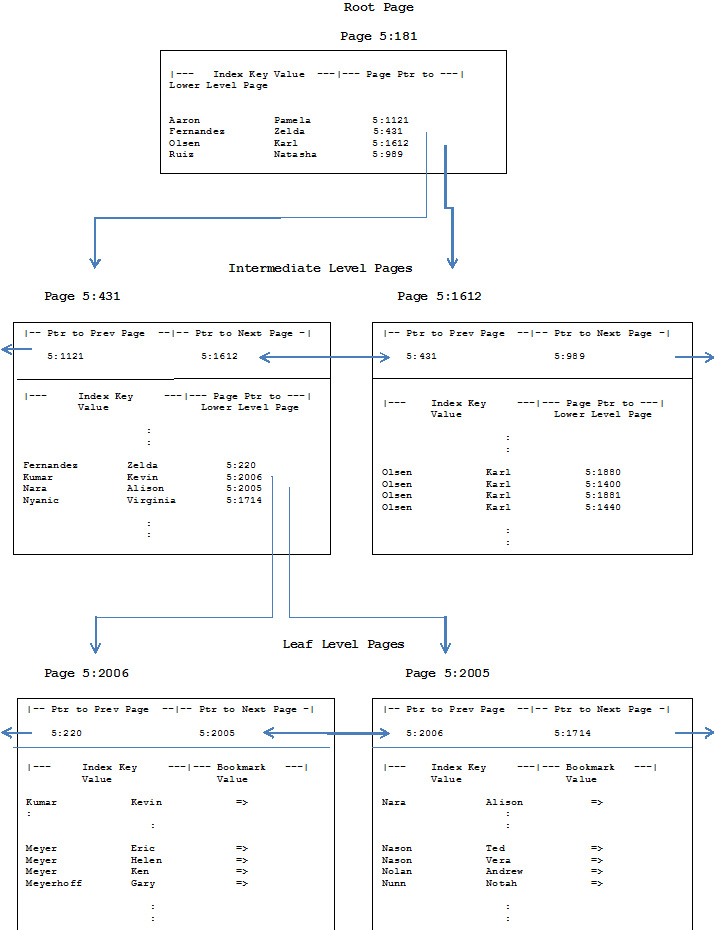
图1 -索引的垂直切片
为了清晰和说明,图表与一个典型的指数不同的是:
一个典型索引中的每个页面的条目数将大于图中所示的数字,因此,除了根之外,每个级别的页数都大于显示的页数。叶级,特别是,将有远多于可以显示在我们的空间有限图。
实际索引的条目不在页面上进行排序。这是页面的条目偏移指针,它提供对条目的排序访问。(请参阅第4级-页面和扩展,以获得关于偏移指针的更多信息。)
通常情况下,索引的物理和逻辑序列之间的相关性比图表中显示的要多。该索引的物理和逻辑序列之间缺乏相关性称为外部碎片,并在第11级-分段中讨论。
如前所述,索引可以有多个中间级别。
就好像我们的白页用户正在寻找海伦·迈耶,打开电话簿,发现第一页,只有第一页,是粉红色的。在“粉红页面”的排序列表中,有一个条目是“在费尔南德斯、塞尔达和奥尔森之间的名字”,“看蓝页5:431”。当我们的用户浏览到蓝页5:431的时候,页面上的一个条目上面写着“库玛尔,凯文”和“奈良”之间的名字,参见“白色页5:2006”。粉色的页面对应于根,蓝色的页面对应中间的层次,而白色的页面是叶子。
指数深度
根页面的位置存储在系统表中,以及其他关于索引的信息。每当SQL Server需要访问与索引键值相匹配的索引项时,它就从根页面开始,并在索引的每个级别上通过一个页面进行工作,直到到达包含该索引键的条目的叶级页面为止。在我们的10亿行表示例中,5页的读取将把SQL Server从根页带到叶级页面及其所需的条目;在我们的图表示例中,三个读取就足够了。在聚集索引中,这个叶级条目将是实际的数据行;在非聚集索引中,该条目将包含聚集索引键列或RID值。
索引的级别或深度的数量取决于索引键的大小和条目的数量。在AdventureWorks数据库中,没有索引的深度大于3。在具有非常大的表或非常宽的索引键列的数据库中,可能会出现6个或更大的深度。
sys。dm_db_index_物理cal_statsfunction提供关于索引类型、深度和大小等索引的信息。它是一个可查询的表值函数。清单1中显示的示例返回SalesOrderDetailtable的所有索引的汇总信息。
SELECT OBJECT_NAME(P.OBJECT_ID) AS 'Table'
, I.name AS 'Index'
, P.index_id AS 'IndexID'
, P.index_type_desc
, P.index_depth
, P.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(),
OBJECT_ID('Sales.SalesOrderDetail'),
NULL, NULL, NULL) P
JOIN sys.indexes I ON I.OBJECT_ID = P.OBJECT_ID
AND I.index_id = P.index_id;
清单1:查询系统。dm_db_index_物理cal_stats函数,如图2所示。

图2:查询系统的结果。dm_db_index_physical_stats函数
相反,清单2中所示的代码请求特定索引的详细信息,即SalesOrderDetail表中表中唯一的非聚集索引。它返回每个索引级别的一行,如图3所示。
清单2:查询系统。dm_db_index_physical_stats详细信息。
SELECT OBJECT_NAME(P.OBJECT_ID) AS 'Table'
, I.name AS 'Index'
, P.index_id AS 'IndexID'
, P.index_type_desc
, P.index_level
, P.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID('Sales.SalesOrderDetail'), 2, NULL, 'DETAILED') P
JOIN sys.indexes I ON I.OBJECT_ID = P.OBJECT_ID
AND I.index_id = P.index_id;
图3:查询系统的结果。dm_db_index_physical_stats为详细信息

从图3所示的结果中,我们可以看到:
该指数的叶级分布在407页。
一个和唯一的中级水平只需要两页。
根级别始终是一个单独的页面。
指数的非叶部分的大小通常是叶级的十分之一到百分之一。根据哪些列包含搜索键、书签的大小,以及是否指定了包含列的列。换句话说,相对而言,索引非常宽且非常短。这与大多数的索引示例图不同,例如图1中的图,它通常是高的和窄的。
结论
索引结构使SQL Server能够快速访问特定索引键值的任何条目。一旦找到该条目,SQL Server就可以:
访问该条目的行。
从这一点通过升序或降序遍历索引。
这种索引树结构已经使用了很长时间,甚至比关系数据库还要长,而且它已经证明了自己的时间。
记住,包含的列只适用于非聚集索引,它们只出现在叶级条目中;它们从更高级别的条目中被忽略,这就是为什么它们不会增加非叶级别的大小。
由于聚集索引的叶级是表的数据行,所以只有聚集索引的非叶部分是额外的信息,需要额外的存储。数据行将存在是否创建索引。因此,创建集群索引可能需要时间和消耗资源;但是,当创建完成时,数据库中消耗的额外空间很少。