Code_link:https://pan.baidu.com/s/1dshQt57196fhh67F8nqWow
本文是为既没有机器学习基础也没了解过TensorFlow的码农、序媛们准备的。如果已经了解什么是MNIST和softmax回归本文也可以再次帮助你提升理解。在阅读之前,请先确保在合适的环境中安装了TensorFlow(windows安装请点这里,其他版本请官网找),适当编写文章中提到的例子能提升理解。
首先我们需要了解什么是“MNIST”?
每当我们学习一门新的语言时,所有的入门教程官方都会提供一个典型的例子——“Hello World”。而在机器学习中,入门的例子称之为MNIST。
MNIST是一个简单的视觉计算数据集,它是像下面这样手写的数字图片:
每张图片还额外有一个标签记录了图片上数字是几,例如上面几张图的标签就是:5、0、4、1。
本文将会展现如何训练一个模型来识别这些图片,最终实现模型对图片上的数字进行预测。
首先要明确,我们的目标并不是要训练一个能在实际应用中使用的模型,而是通过这个过程了解如何使用TensorFlow完成整个机器学习的过程。我们会从一个非常简单的模型开始——Softmax回归。
然后要明白,例子对应的源代码非常简单,所有值得关注的信息仅仅在三行代码中。然而,这对于理解TensorFlow如何工作以及机器学习的核心概念非常重要,因此本文除了说明原理还会详细介绍每一行代码的功用。
阅读前需要了解的
阅读之前请先获取 mnist_softmax.py 的代码,文中会一步一步的介绍每一行代码的内容。建议读者分为2种方式去学习后面的内容:
- 跟随本文的介绍一行接着一行的将代码片段拷贝到python开发环境中,边阅读边理解代码的含义。
- 稍微有点基础的,可以在继续向下阅读之前先理解和运行下
mnist_softmax.py的代码,之后回来继续阅读以解惑不明部分。
本文包含以下内容:
- 学习MNIST的数据解析以及softmax回归算法。
- 创建一个基于图片像素识别图片数字的模型。
- 使用TensorFlow来训练模型识别数字,这个学习的过程是让它去看成千上万的图片。
- 使用我们的测试数据来验证模型的准确性。
模型创建
MINIST数据
MINIST数据集的官网是 Yann LeCun's website。下面这2行代码的作用是从MINIST官网自动下载并读取数据:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)MINIST的数据分为2个部分:55000份训练数据(mnist.train)和10000份测试数据(mnist.test)。这个划分有重要的象征意义,他展示了在机器学习中如何使用数据。在训练的过程中,我们必须单独保留一份没有用于机器训练的数据作为验证的数据,这才能确保训练的结果是可以在所有范围内推广的(可泛化)。
前面已经提到,每一份MINIST数据都由图片以及标签组成。我们将图片命名为“x”,将标记数字的标签命名为“y”。训练数据集和测试数据集都是同样的结构,例如:训练的图片名为 mnist.train.images 而训练的标签名为 mnist.train.labels。
每一个图片均为28×28像素,我们可以将其理解为一个二维数组的结构:
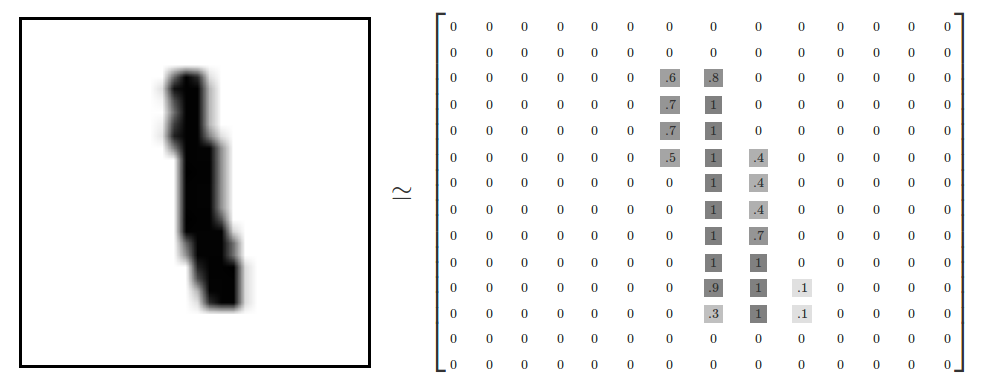
然后将这个数组扁平化成由784(28×28)个数字组成的一维数组。怎么扁平化数组并不重要,关键在于我们要保证所有的图片都使用一致的扁平化方法。因此,在数学意义上可以把MINIST图片看成是在784维度向量空间中的点,关于这个数据结构的复杂性可以参看这篇论文加以了解——Visualizing MNIST: An Exploration of Dimensionality Reduction。
扁平化会丢失图片的二维结构信息,优秀的图形结构算法都会利用二维结构信息,但是为了简化过程便于理解,这里先使用这种一维结构来进行softmax回归。
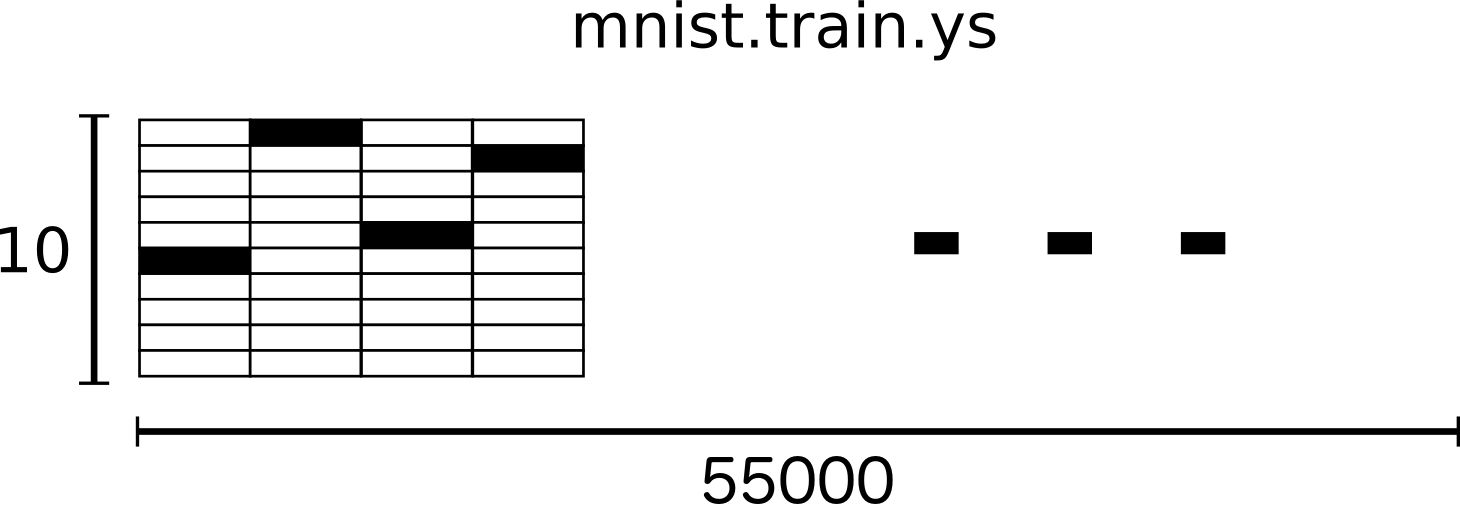
mnist.train.images 是一个形态为 [55000, 784] 的张量(tensor)。第一个维度表示图片个数的索引,第二个维度表示图片中每一个像素的索引。每一个像素的取值为0或1,表示该像素的亮度。 mnist.train.images 可以理解为下图这样的空间结构:

MNIST的每一张图片都有一个数值0~9的标记。教程中,我们将标签数据设置为“one-hot vectors”。“one-hot vectors”是指一个向量只有一个维度的数据是1,其他维度的数据都是0。在本文例子中,标记数据的维度将设置为1,而其他维度设置为0。例如3的向量结构是[0,0,0,1,0,0,0,0,0]。所以 mnist.train.labels 是一个结构为 [55000, 10] 的张量。
然后开始实际创建前面描述的模型。
Softmax回归
MNIST中每一张图片表示一个手写体0到9的数字,所以每一张图片所要表达的内容只有10种可能性。我们希望得到图片代表某个数字的概率。举个例子,一个模型当图片上的手写体数字是9时有80%的可能性识别的结果是9,还有5%的可能性识别出的结果是8。因这2者并没有覆盖100%的可能性,所有还有其他数字可能会出现。这是一个典型的softmax回归案例。softmax回归的作用是可以将概率分配给几个不同的对象,softmax提供了一个值处于0到1之间的列表,而列表中的值加起来为1。
一个softmax回归包含2步:首先根据输入的数据提取该输入属于各个分类的“证据”(evidence),然后将这个证据转换成一个概率值。
为了收集证据(evidence)以便将给定的图片划定到某个固定分类,我们对图片的像素值进行加权求和。如果有很明显的证据表明某个像素点会导致图片不属于该类,则加权值为负值反之为正。
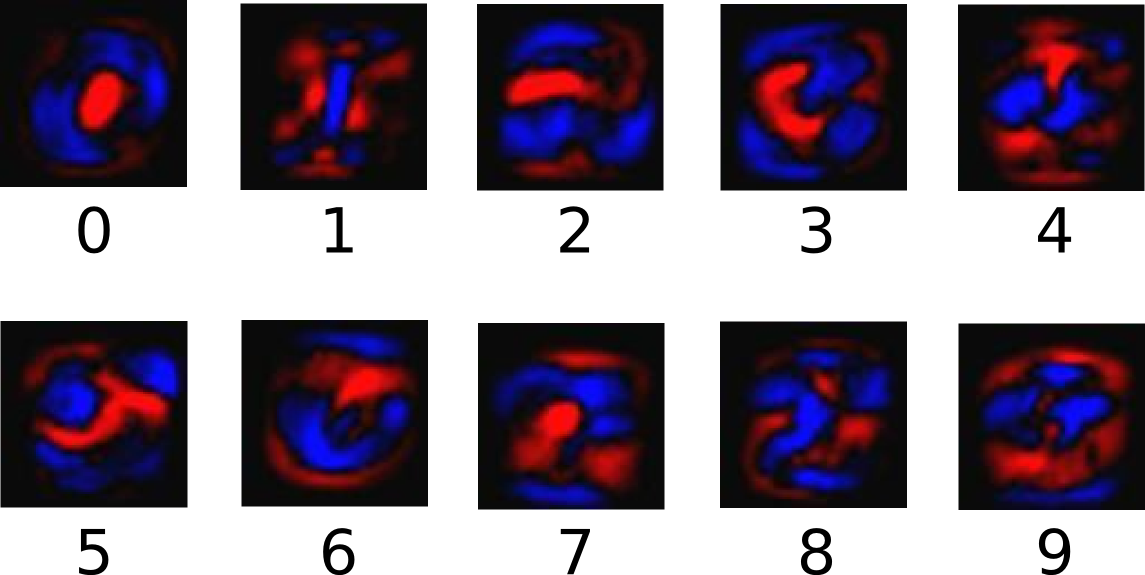
下面的图片展示了一个模型经过学习后,图片上的每个像素点对于特定数字的权值。红色表示负数权值、蓝色表示正数权值:
在训练的过程中,我们需要设定额外的偏置量(bias)以排除在输入中引入的干扰数据。下面图表示证据的提取计算公示,对于分类i给定一个x的输入得到:
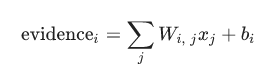
这里i表示分类(i=[0...9]),j表示图片x的像素索引(j=[0...784])、Wij表示分类i在像素点j的加权值、xj表示图片x在j像素点的值(xj=[0,1]),bi表示分类i的偏移量。然后用softmax函数将这些证据转换成一个概率值:
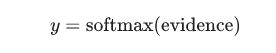
这里的softmax可以看成是一个转换函数,把线性函数的输出转换成需要的格式。在本文的例子中输出的就是图片在0~9这10个数字上的概率分布。因此,整个过程就是给定一个图片x,softmax最终会转化输出成一个对应每个分类概率值。它的定义是:
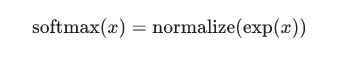
展开等式的子等式:
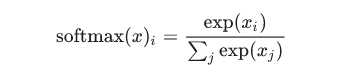
这个公式可以理解为:图片x在i分类中的加权值在所有加权值中的占比,exp()是e为底的指数计算公式。
上面的2个公示展示了softmax函数的计算过程:
- 将参数作为幂运算的指数输入到公式中。使用幂指数的价值在于能够进一步放大(正值)或缩小(负值)权重值,对于设定的权重非常敏感。因为softmax使用幂指运算,所以再小的负值只会导致计算结果趋近于0,所以实际上运算结果不会出现负数或0。
- 获取值之后,softmax对这些值进行归一化处理,使得在每个分类上形成有效的概率分布(保证每个分类的值在0到1之间,确保所有分类的和值为1)。
如果想了解更多关于softmax回归的细节,请阅读Michael Nieslen书中关于softmax的说明。
下图形象的展示了softmax回归的过程。Xj表示一个像素点(下图中j=[1,2,3])。然后通过像素点与权重Wij的乘积求和(下图中i=[1,2,3])再加上偏移量bi得到模型值,最后将模型进行softmax运算。
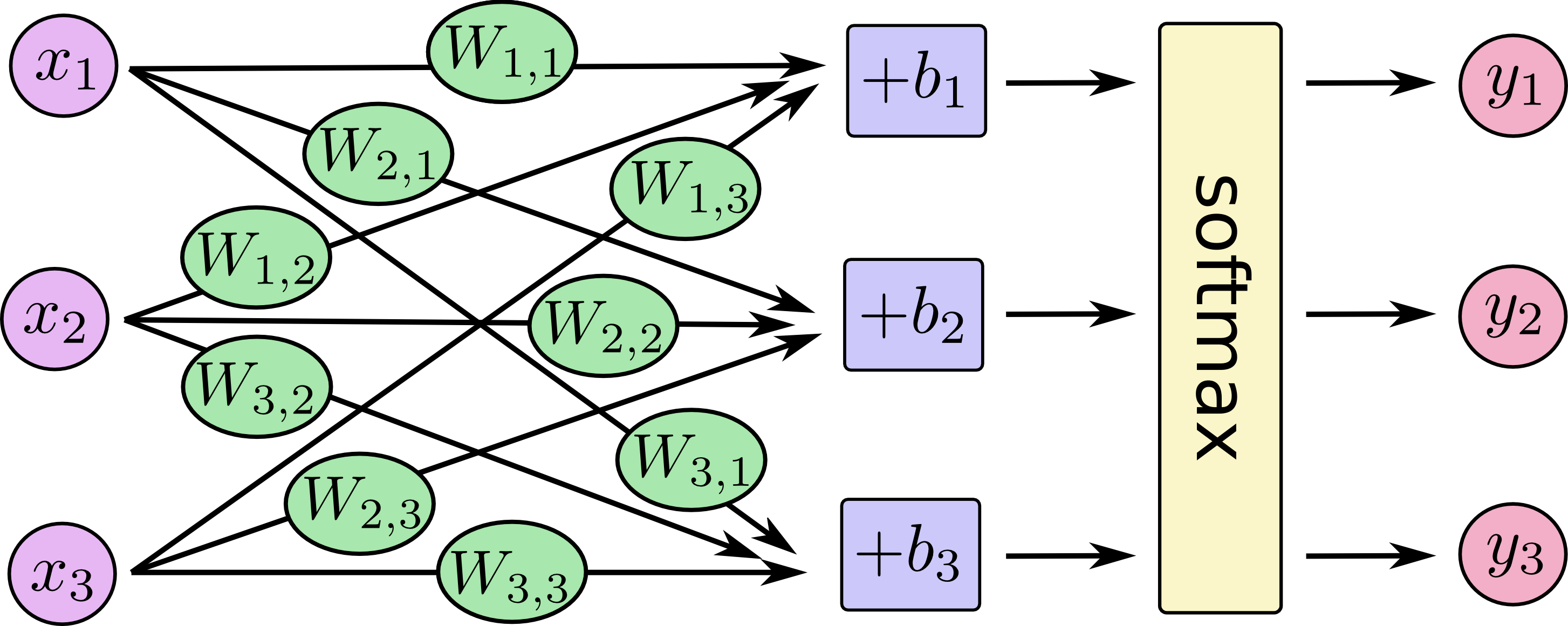
如果将其转换成线性方程式,得到:
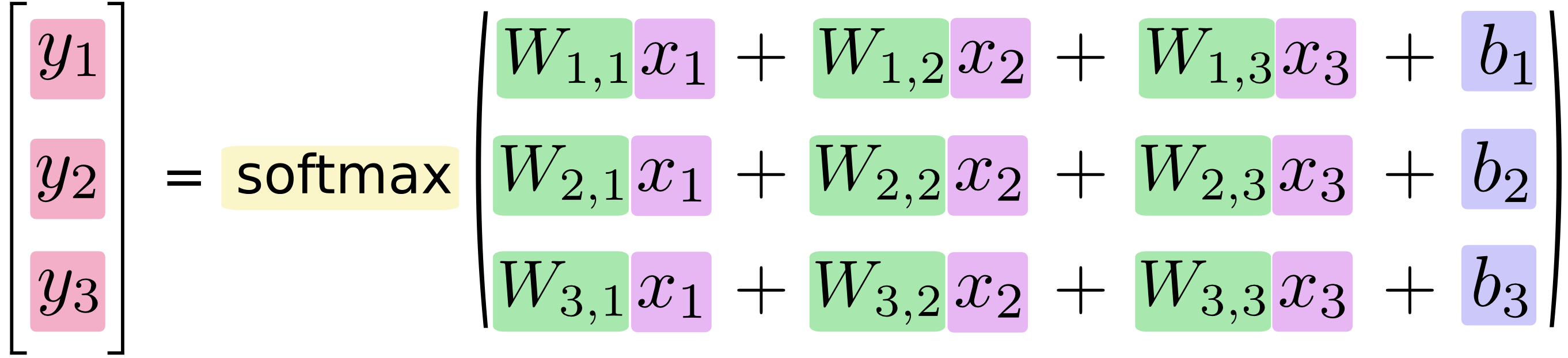
还可以用向量矩阵来表述这个过程。下图的结果将上面的方程式转换成向量矩阵,这样有助于提升计算效率。
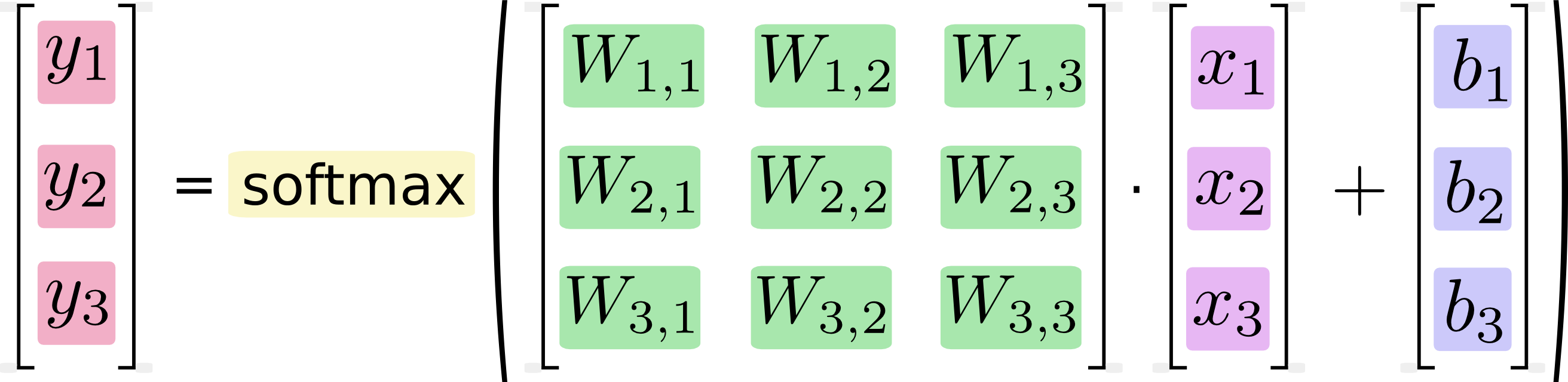
最后可以使用下面的等式形象的表示这个过程:
y=softmax(Wx+b)
接下来,我们将把这个过程使用TensorFlow实现。
实现回归过程
为了在python中实现高效的数字运算建议用 NumPy 这一类第三方库进行复杂的数学运算(比如下文会用到的矩阵乘法运算),因为它们使用了其他更高效的语言(C++)提升运算速度。使用外部库还是会存在一些效率问题:计算操作在python和其他语言之间来回切换会导致许多额外的性能开销,在使用GPU运算时这个问题尤为明显,在集群环境下同样存在这个问题。
TensorFlow同样使用C++等语言实现高效的运算,但是为了避免前面说到的问题,TensorFlow进行了一些完善。在 TensorFlow入门部分 已经说明,它的执行过程是先构建模型然后再执行模型,所以TensorFlow会在模型执行期间一次性使用外部语言进行所有的计算然后再切换回python返回结果(绝大部分机器学习库都以这种方式实现)。
首先,导入TensorFlow:
import tensorflow as tf声明变量x:
x = tf.placeholder(tf.float32, [None, 784]) x表示所有的手写体图片。它并不是一个固定值而是一个占位符,只有在TensorFlow运行时才会被设定真实值。根据前文描述的模型,输入是任意数量的MNIST图片,每张图片的像素值被扁平化到一个784维度的向量中([784]),我们用一个二维浮点数张量来记录所有图片的输入,这个张量的形状就是 [None, 784] 。这里的 None 表示任意维度的向量。
我们的模型还有 权重 和 偏移量。由于是可训练数据,我们将这些值指定为一个附加输入,在 TensorFlow入门部分 我们称之为 变量。变量就是可修改的张量,他在图中是一个可操作的节点。在计算的过程中,变量是样本训练的基础,通过不断调整变量来实现一个收敛过程找到变量的最佳值。
# tf.zeros表示所有的维度都为0
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))使用 tf.Variable 创建一个变量,然后使用 tf.zeros 将变量 W 和 b 设为值全为0的张量(就是将张量中的向量维度值设定为0)。由于我们在后续的过程中要使用大量的数据来训练 W 和 b 的值,因此他们的初始值是什么并不重要。
下面解释下W和b的意义:
- w的形状是一个[784,10]的张量,第一个向量列表表示每个图片都有784个像素点,第二个向量列表表示从“0”到“9”一共有10类图片。所以w用一个784维度的向量表示像素值,用10维度的向量表示分类,而2个向量进行乘法运算(或者说2个向量的笛卡尔集)就表示“某个像素在某个分类下的证据”。
- b的形状是[10],他仅表示10个分类的偏移值。
在TensorFlow中仅仅一行代码就可以实现整个运算过程:
y = tf.nn.softmax(tf.matmul(x, W) + b)解释一下这行代码:
-
tf.matmul(x, W)表达式表示W和x的乘积运算,对应之前等式(y=softmax(Wx+b))的Wx,这个计算结果会得到一个y1=[None, 10]的张量,表示每个图片在10个分类下权重计算结果。 -
tf.matmul(x, W) + b表示执行y2=y1+b的运算,它计算每个分类的偏移量。y2还是一个[None,10]的张量。 - 最后使用
tf.nn.softmax进行归一计算,得到每张图片在每个分类下概率。
到止为止,使用TensorFlow完成了计算模型的创建。回忆下做了什么事:先用几行代码创建了数据(占位和变量),然后用一行代码创建了运算模型,代码非常的简短。简短并不是因为TensorFlow特意为softmax回归计算做了什么特别的设计,而是因为无论是机器学习建模还是物理仿真运算,使用TensorFlow描述数值计算都非常灵活。模型一旦定义好就可以在不同的设备上运行,例如电脑的CPU、GPU甚至手机。
模型训练
为了训练模型,需要针对模型定义一个指标来衡量模型“有多好”。不过事实上在机器学习中典型的方法是定义某个指标来衡量模型“有多差”。这个指标称为“成本”(cost)或“损益”(loss),它表示某个模型与期望的结果有多远。训练的目的就是不断的减少损益值,损益值越小证明我们的模型越好。
通常情况下,“交叉熵”(cross-entropy)是非常适用于评估模型的损益值大小。交叉熵的概念来自于信息论的中关于信息压缩与编码的讨论,但是在博弈论、机器学习等其他许多领域也是重要的思想。他的数学定义是:
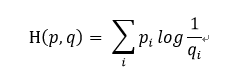
q表示预测的概率分布,p表示真实分布(图片标签的分布)。简单的说,交叉熵就是描述当前模型距离真实的数据值还有多少差距。
*信息论中的熵与交叉熵
TensorFlow官网在对应的教程中并没有解释什么是交叉熵,这里根据我对信息论相关的数学知识理解说明什么是交叉熵。如果对数学符号所代表的含义没有兴趣,可以跳过本小节
熵
信息论中的熵是指信息不确定性的度量。熵越高代表为了呈现某个事物所需要的信息量就越多。熵的值都是基于概率的,其概率解释是:当某些事物在样本空间中的占比率越高,则需要将他描述出来的信息量越少。若占比率越少,则描述他的信息就越多。根据这个理论,熵值实质上衡量是信息量大小的数值,加上单位后的数量就是实际中常用于标记数据量大小的值,通常情况下用1位信息表示2个信号来表述,这个单位我们称之为bit。
数学上对于均匀分布的信息,其熵可以用:
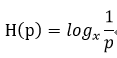 (1)
(1)
来表示。假设26个英文字符是均匀分布的,那么这里的p=1/26。若使用bit为运算单位,那么低x取值为2,所以计算得出26个英文字母需要4.7004bit信息来表述,取上界就是5bit的信息量。
但是在现实世界中,绝大部分事物都不是均匀分布的。比如英文单词,通常字母e出现的频率比z就高很多,所以这种情况需要分别对不同事物的“统计特征”逐个计算,在这种情况下,熵的计算公式为:
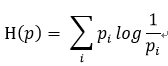 (2)
(2)
数学含义是:对于i个事物X,每个事物X的概率分布为Pi,其熵值为每个独立事物熵值占比的合计。
公式(1)是公式(2)在均匀分布下的推导:若P1=P2=P3=....=Pn且均分同一概率空间,那么可以推导出公式(1)。
举个例子。架设有4个英文字母集合v=[A,B,C,D],其对应的概率分布p=[1/2,1/2,0,0],那么:
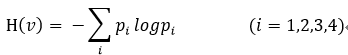
将公式展开:
![]()
若取bit作为度量单位,那么x=2,则得到的结果是H=1。所以如果按照这样的分布,只需要1bit的信息就可以表述所有的信息(因为C和D根本就不会出现,而A或B只需要一位[0,1]来表述)。
交叉熵
在公式(2)中p表示所有事物的真实分布,但是在实际情况中并不一定准确的清晰所有样本的真实分布,信息论中用交叉熵来表示这种情况,其表达式就是前面出现的公式:
q是预测分布,而p是真实分布。
还是使用上面的例子:集合v=[A,B,C,D,E]、p=[1/2,1/2,0,0],预测分布我们使用均匀分布p=[1/4,1/4,1/4,1/4],所以带入公式:
![]()
若取bit作为度量单位,那么x=2,则交叉熵的值H(p,q)=2。
交叉熵作为损益计算的意义
H(p,q)>=H(p)恒成立,当q等于真实分布q时取等号。因此在机器学习中,若p表示真实标记的分布,q为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。
为了在编码中实现交叉熵,首先需要增加一个占位符来输入真实分布值:
y_ = tf.placeholder(tf.float32, [None, 10])然后我们实现交叉熵功能:
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))这一行代码的含义:
- 使用
tf.log对y进行对数计算。 - 然后用y_与
tf.log相乘。 - 用
tf.reduce_sum根据reduction_indices=[1]指定的参数,计算y中第二个维度所有元素的总和。 - 最后,
tf.reduce_mean用于计算该批次的一个平均值。
需要注意的是,这里的cross_entropy仅仅用于示例以便于理解。在源代码中,不推荐使用这个公式,因为在数值上非常不稳定。推荐使用tf.nn.softmax_cross_entropy_with_logits 方法直接训练 tf.matmul(x, W) + b) 的结果。因为他在内部计算softmax,数值更加稳定。
现在,我们已经定义好模型和训练方式,TensorFlow接下来会使用“反转传播算法”逐步修改变量以找到能使损益值最小化的变量值。现在定义所需的优化器:
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)上面的代码设定梯度递减算法为训练的优化器,每次变量的调整范围为0.01。梯度递减是非常快捷高效的算法,TensorFlow需要做的是将每个变量一点点的向损益值变小的方向逐渐移动。TensorFlow提供了非常多的优化算法,只需要修改这行代码即可将优化器修改为其他算法。
整个过程TensorFlow都做了什么呢?在另外一篇 TensorFlow入门 的博文中介绍了TensorFlow的计算过程就是一个图。在后台运算时,TensorFlow会向这个图增加额外的操作以实现“反转传播算法”和“梯度递减算法”。最后TensorFlow返回一个独立的操作入口(就是上面代码中的train_step),这个入口会用梯度下降算法训练你的模型、微调你的变量、不断减少损益值。
现在可以在 InteractiveSession 中启用该模型:
sess = tf.InteractiveSession()在运行之前需要初始化所有的变量:
tf.global_variables_initializer().run()然后就可以开始训练了,我们允许一次执行1000次训练。
for _ in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})循环中的每一步,我们都会从训练图片分类的集合中(回想一下,前面提到每一个图片包含图片自身的像素值以及一个标记数值的标签)中随机取出100条随机数据,然后执行train_step将占位数据替换成从测试图片库mnist.train中获取的参数。
使用一个小批量的随机数称为随机训练(stochastic training),在这个例子中可以叫随机梯度递减训练。理想状态下,当然期望所有的数据都用于每一步训练,这样可以覆盖到所有样本,但是所带来的负面影响是计算成本太高。所以,每次训练都随机使用不同的数据子集,这样既降低计算成本又有效最大化利用数据。
模型评估
现在我们来到了所有工作的最后一步,验证所设计的模型是否足够好。
首先找出那些被模型预测正确的图标。 tf.argmax 是一个非常有用的方法,它能够找到张量中某个列表最高数值的条目索引。例如 tf.argmax(y,1) 是找到张量y第二个向量的最大值(图标标签是0~9,softmax计算完成后会得到一个分布概率,argmax方法就是找到每一个图片对应的最高概率),而 tf.argmax(y_,1) 设定的参数就是真实标签。然后使用 tf.equal 方法检查预测是否和真实情况一样。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))比较的结果会返回一个boolean列表,为了确定正确预测的占比,我们用float类型来表示boolean类型。例如对于boolean类型的列表[true,false,true,true]可以转换成[1,0,1,1],然后正确占比是75%。下面的代码完成了这一步工作。
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))最后,运行它测试模型预测图片数据的准确率。
# 这里使用的是整个mnist.test的数据
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))输出的结果应该是92%左右。
最后我们说说这个结果。从严格意义上来说,92%的正确率是非常差的。因为我们所使用的模型不仅非常简单而且数据也非常规范。不过不必灰心,只要经过小小的跳转,可以让这个正确率立刻达到97%,而现在最好的模型达到了99.7%。关于模型准确性的讨论,可以看 这里。
本文的价值并不是正确率,而是了解如何进行机器学习建模。当然,对于机器学习这仅仅是一个开始,后续会在这篇文章的基础上继续介绍如何使用TensorFlow搭建更复杂更有价值的模型。
附记
在写本文时,正好在微信朋友圈和OC都看到传得正火爆的《自动编程是不可能的 我为什么不在乎人工智能》一文。关于人工智能是否值得在乎每个人都有自己的看法谈下去没什么价值,不过自动编程这一点倒是在这一代AI技术上不太可能做得比普通工程师做得更好。原因很简单,本文提到的一个数学公式就说明了这个问题:
这是信息交叉熵公式,也是机器学习常用的损益评估公式。当期望分布p=q时,获得最少信息量或最少损益值,收敛学习结果的过程,其实就是在找p=q或让q逐渐接近p的过程。
从信息论的角度来看,所有用户通过自然语言描述的需求对于机器来说熵值是非常高的,因为大段的自然语言中有用的内容在整体信息中的分布非常低。而通过产品人和研发工程师的转换最终成为熵值非常低的源码。所以靠不懂编程开发的人去实现有价值的程序个人认为几乎不可能。
不过AI对于编程肯定有增益效果。比如当年用C#写windows界面,妥妥拽拽代码就生成好了,码农下一步活就是在各种回调事件中写业务、写DAO、写调用。AI也可以通过大数据观察各种功能的实现方式,最终帮码农快速生成一个60~70%可用的代码,然后序员们在以后的基础上继续写逻辑。个人觉得这个思路可以推广到很多行业——减少重复劳动,增加有特定意义的劳动时间,最终实现提升生产率