1. 写在前面
今天是新生周的最后一天,意味着自己班级里的小朋友的接触也要告一段落了。心中也有那么一丝丝的不舍。好在自己终于完成了软工的第二次作业,也算是给自己一个安慰吧。开学的这一周让我知道了,软工实践是如何“充实”自己的大学生活的。在这里也要感谢一下班里的陈俞辛、董钧昊、蔡宇航、陈柏涛同学,感谢他们在我遇到问题的时候给予我的帮助!
PSP表格
| psp2.1 | personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 50 |
| Estimate | 估计这个任务需要多少时间 | 780 | 965 |
| Development | 开发 | 180 | 200 |
| Analysis | 需求分析(包括学习新技术) | 120 | 150 |
| Design Spec | 生成设计文档 | 15 | 20 |
| Design Review | 设计复审 | 20 | 10 |
| Coding Standrd | 代码规范(为目前的开发制定合适的规范) | 15 | 10 |
| Design | 具体设计 | 30 | 25 |
| Coding | 具体编辑 | 150 | 250 |
| Code Review | 代码复审 | 30 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 90 |
| Reporting | 报告 | 60 | 50 |
| Test Repor | 测试报告 | 20 | 15 |
| Size Measurement | 计算工作量 | 30 | 20 |
| Postmortem&Process Improvement Plan | 事后总结,并提出过程改进计划 | 20 | 15 |
| - | 合计 | 780 | 965 |
2. 解题思路
- 本次作业的四个要求
- 统计字符
- 统计有效行数
- 统计单词数
- 统计词频
2.1 统计字符
统计字符数:只需要统计Ascii码,汉字不需考虑,
空格,水平制表符,换行符,均算字符。
- 只需考虑可视字符 (ASCII:32-126) 、水平制表符 (ASCII:9) 、换行符 (ASCII:10) 。
- 首先通过定义一个
fstream对象来打开文件,使用get()方法来获取字符,用eof()方法来判断文件是否已经读完。fstream的使用参见:参考博客一 - 监测到满足要求的字符就令计数器
cnt自增加一,并定义一个string变量来存储该文件中的所有字符。
2.2 统计有效行数
统计文件的有效行数:任何包含非空白字符的行,都需要统计。
- 首先想到的就是换行符
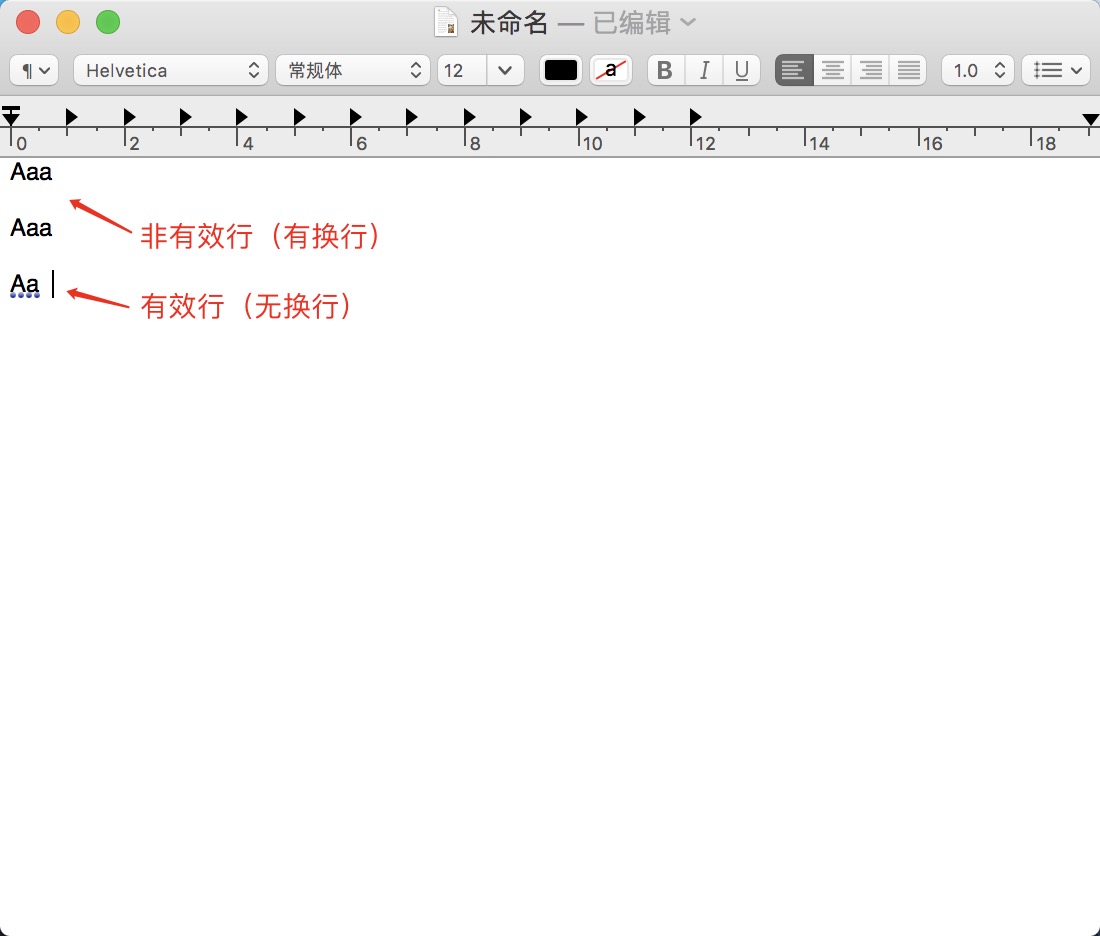
- 所以我采用一个
flag变量,检测到有效字符置flag为1,否则置0,然后对文档的所有字符进行扫描。 - 当
flag为1且检测到换行符,行数加一。扫描完整个文件后,检测flag的值,如果为1,代表最后一行是“没有换行符的”有效行,行数自增加一。
2.3 统计单词数
统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 这里我采用了多重循环检测的方式,判断是否为有效单词。如果是的话就将它插入哈希表,以供之后的统计词频功能使用。
- 后来查阅资料的时候了解到了正则表达式匹配的方法,可惜没有时间来实现,但是以后自己也会学习相关的知识。
2.4 统计词频
统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
- 由于是按照字典序来排序并统计出现次数,所以我定义了一个结构体。
struct node {
string name;//名
int times;//出现频次
node *next;
node(string n, int number)
{
name = n;
times = number;
next = NULL;
}
};
name用来存放单词字符,times用来存放出现次数,next用来连接节点,实现开散列。- 根据单词的字母组成来构造哈希函数如下
int hash = ((w[0] - 96)) + ((w[1] - 96) * 26) + ((w[2] - 96) * 26 * 26);
- 根据哈希值为每个检测到的单词新建一个节点,并插入到开散列中。
- 调用插入函数
insert(),当该单词的哈希值对应的散列单元存在节点,则插入到该单元下的链表中,并使times++。 - 如果不存在节点直接接在散列单元上即可。
- 所有单词插入完毕后。扫描十次散列表,每次都选出
times最大的一个节点,并将它删除。得益于散列函数,不必排序。
3. 实现过程
- 通过这次作业让我学到,好的封装可以大大提高编码效率!
- 因为自己着急打代码的原因,导致封装花了很多时间!
3.1 类的概述
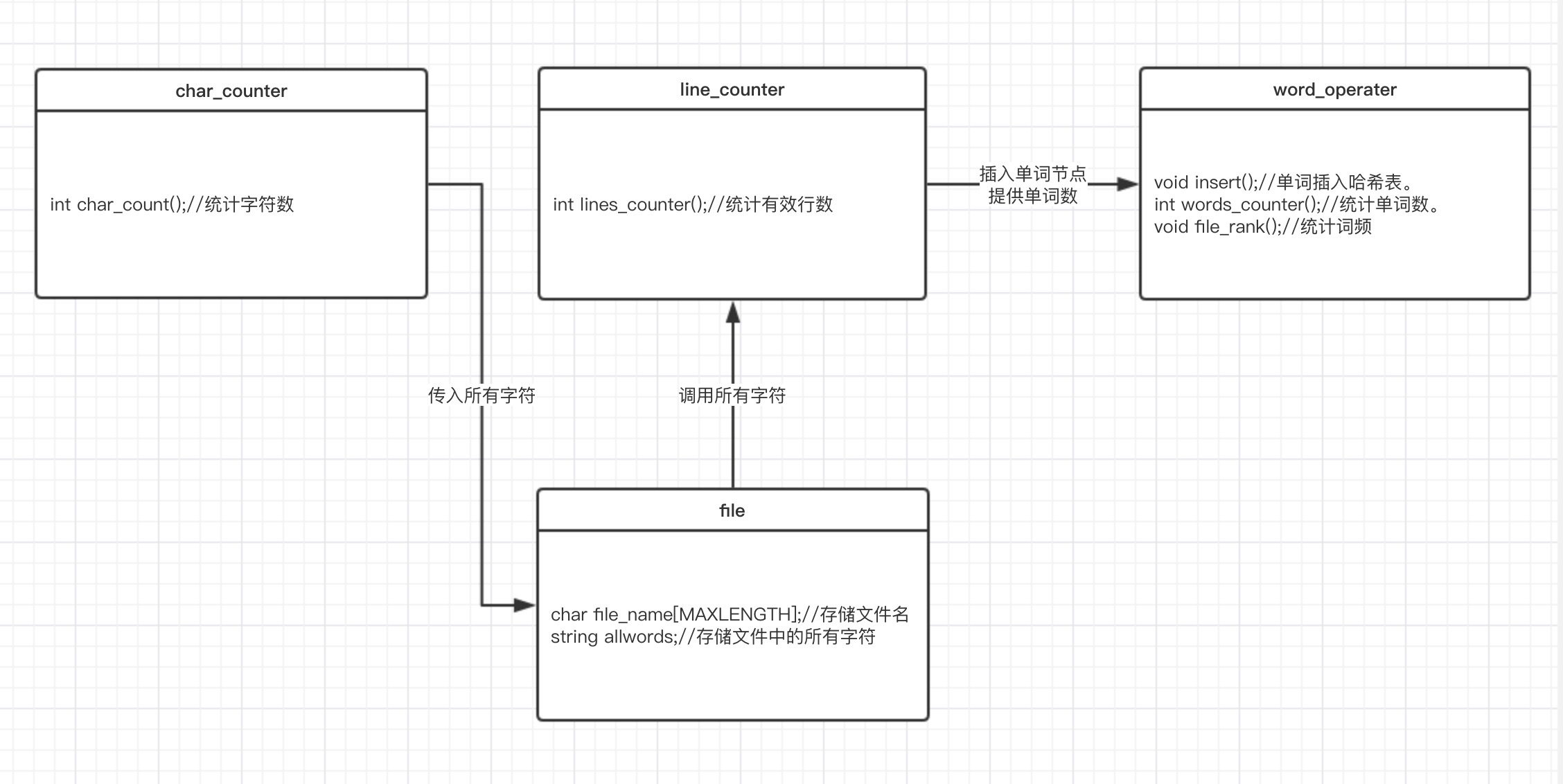
- 为了实现上述功能,我写了四个类:
char_counter:int char_count();:负责统计字符数。
file:负责存储文件的相关信息,比如文件名,文件中的所有字符。line_counter:int lines_counter();:统计有效行数
word_operater:void insert();:单词插入哈希表。int words_counter();:统计单词数。void file_rank();:负责统计词频。
3.2 GitHub仓库组织
031602523
|- src
|-WordCount.sln
|-WordCount
|-Char_counter.cpp
|-Line_counter.cpp
|-Word_operater.cpp
|-main.cpp
|-char_cnt.h
|-file.h
|-line_cnt.h
|-pre.h
|-word_op.h
|-stdafx.h
|-targetver.h
|-stdafx.cpp
|-unittest1.cpp
3.3 类之间的关系
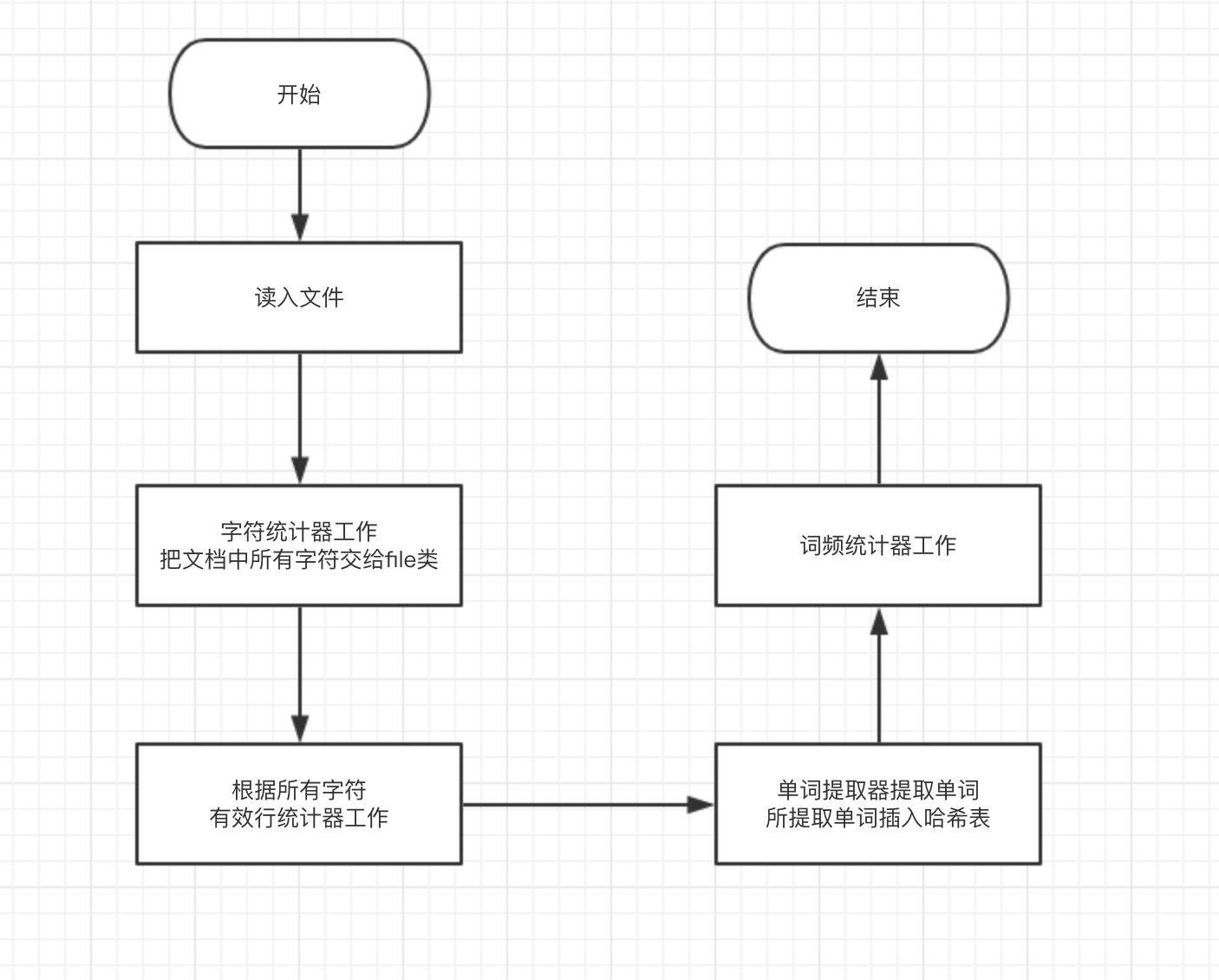
3.4 程序流程图
4.关键代码
- 我觉得字符提取和有效行代码是重中之重,再此贴上两段程序的代码。
4.1 有效行统计
int Line_counter::lines_counter(istream &f, Files &fn)
{
int flag = 0;
int cnt = 0;
string temp = fn.get_alstring();
int len = temp.length();
for (int i = 0; i < len; i++)
{
if (temp[i] >= 33 && temp[i] <= 126)//表示该行是有效行
{
flag = 1;
continue;
}
if (temp[i] == 10 && flag == 1)//当该行是有效行,并且遍历到1个换行符时,行数加1
{
cnt++;
flag = 0;
}
}
if (flag == 1)//最后一行如果没有换行符,也要加1
cnt++;
return cnt;
}
4.2 字符统计
int Char_counter::char_count(istream &f, Files &fn)
{
char a;
int cnt = 0;
string temp = "";
while (f.get(a))//字符读取不成功就终止
{
if ((a >= 32 && a <= 126) || a == '
' || a == ' ')
cnt++;
temp += a;//把每个字符传入all_string
}
fn.set_alstring(temp);
return cnt;
}
5. 分析与测试
- 这是我本次作业的最大收获之一,除了学会了封装,还初步学会了
vs的一些功能。
5.1 单元测试
| 测试内容 | 测试目的 | 预计输出 | 测试结果 |
|---|---|---|---|
| 无符合条件的字符 | 能否识别正确的字符 | 字符数为0 | 通过 |
| 无有效行 | 能否正确判断是否包含非空白字符 | 行数为0 | 通过 |
| 无满足定义的单词 | 能否正确判断是否为单词定义的字符串 | 单词数为0 | 通过 |
| 随机生成的文本内容 | 统计功能的函数是否正常 | 行数25,字符数1065,单词数61 | 通过 |
| 相同的单词,但是大小写不同 | 能否判断大小写单词 | 单词数4 | 通过 |
| 数字打头的单词,例如"12asda” | 能否正确判断是否为单词定义的字符串 | 单词数0 | 通过 |
| 高频单词小于10个 | 统计高频单词的函数是否考虑到单词数不足10个 | 没有发生vector越界 | 通过 |
| 高频单词大于10个 | 统计高频单词的函数是否正常 | 与人工识别的标准答案相同 | 通过 |
| 文末无换行 | 是否会多读一行 | 字符数4,行数1 | 通过 |
| 文末有换行 | 是否少读一行 | 3字符数5,行数2 | 通过 |
- 这里给出一个测试点的代码。
TEST_METHOD(TestMethod1)
{
ifstream f;
Files file_input;
int u = 1;
Char_counter cc;
Line_counter lc;
Word_operater wo;
ofstream outfile;
string std[10];
int std1[10];
int a, b, c;
file_input.set_filename("input1.txt");
f.open("input1.txt", ios::in);
if (!f.is_open())
{
cout << "Warning! can't open this file!" << endl;
}
a = cc.char_count(f, file_input);
b = lc.lines_counter(f, file_input);
c = wo.words_counter(f, file_input);
cc.set_chrcnt(a);
lc.set_lnecnt(b);
wo.set_wrdcnt(c);
wo.file_rank(file_input, wo, outfile);
Assert::AreEqual(1560, a);
Assert::AreEqual(29, b);
Assert::AreEqual(98, c);
std[0] = "gwsw9c4";
std[1] = "iqbl9b8";
std[2] = "jrim";
std[3] = "bvjb";
std[4] = "dfcmb7";
std[5] = "does9x";
std[6] = "eshwh6";
std[7] = "gkcu";
std[8] = "jawe5jh";
std[9] = "jseb50l";
std1[0] = 9;
std1[1] = 6;
std1[2] = 6;
std1[3] = 5;
std1[4] = 4;
std1[5] = 4;
std1[6] = 4;
std1[7] = 4;
std1[8] = 3;
std1[9] = 3;
//int *p1 = wo.get_w_times();
//string *p2 = wo.get_word_str();
for (int i = 0; i < 10; i++)
{
Assert::AreEqual(std[i],wo.word_str[i]);
Assert::AreEqual(std1[i], wo.word_times[i]);
}
//Assert::AreEqual(1560, a);
//Assert::AreEqual(29, b);
//Assert::AreEqual(98, c);
}
};
5.2 性能分析
- 选择一份长文本循环进行10000次测试。主要的时间损耗在单词匹配和输出。

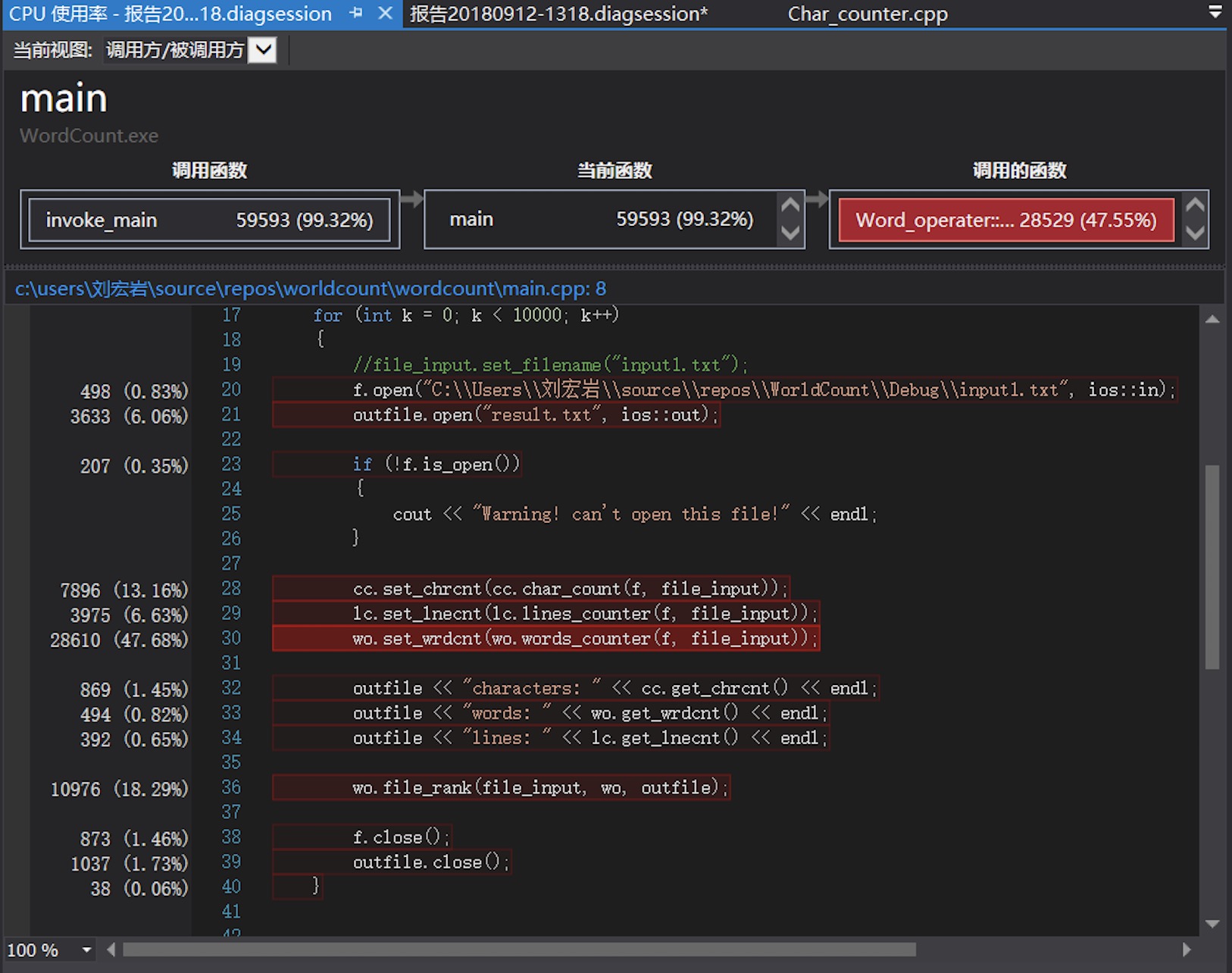
- 针对耗费时间的函数,采取了一些优化,去掉了不必要的操作。可以看出时间上优化了
10(17%)秒,还是有一点点改进的。

5.3 代码覆盖率
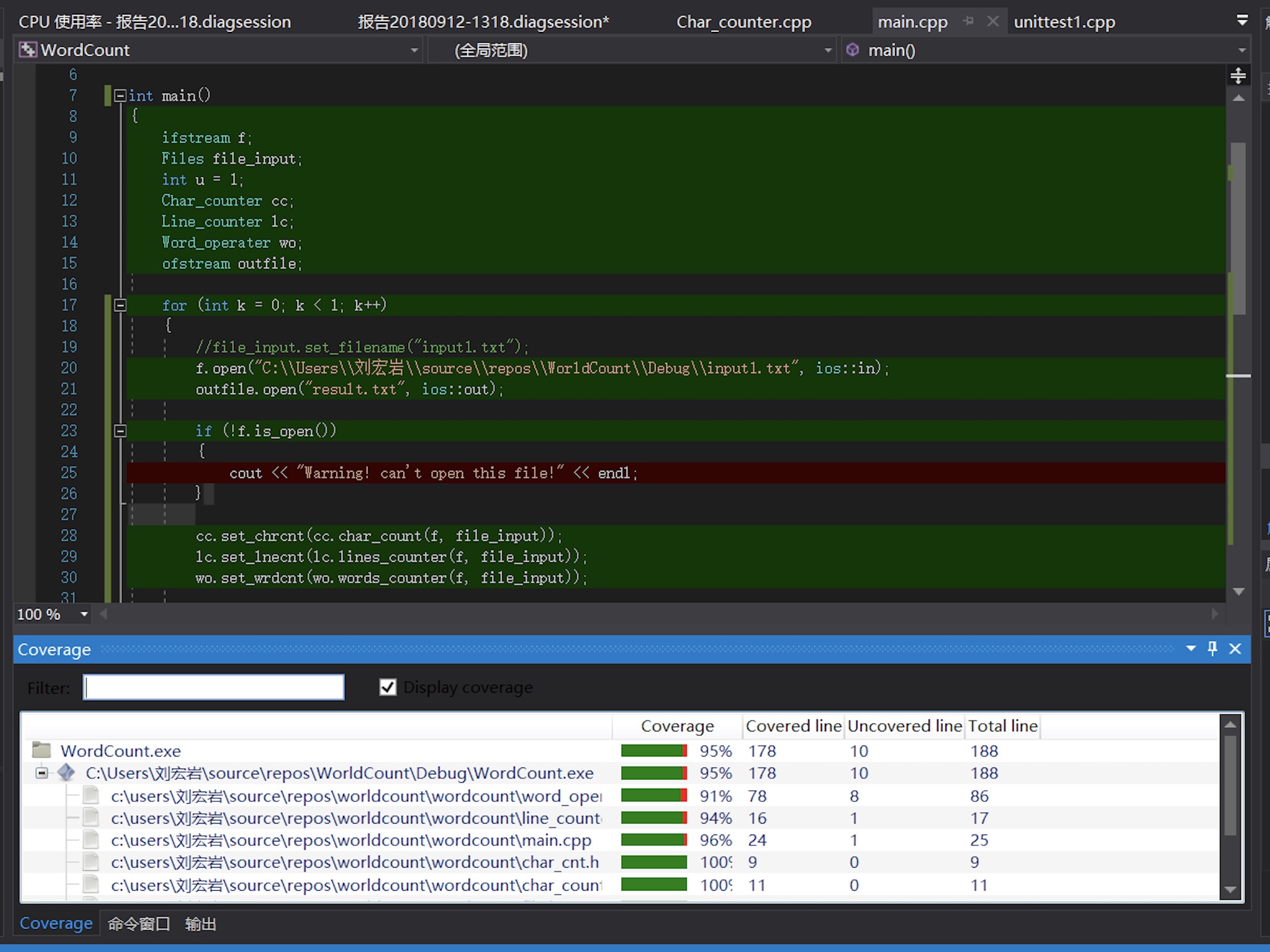
- 测试所得代码覆盖率为
95%.
6. 异常处理
- 我对是否能正确读入文件采取了异常处理。代码如下:
if (!f.is_open())
{
cout << "Warning! can't open this file!" << endl;
}
- 我还遇见了堆栈空间占用过大的问题,原因是我的
Word_operater累中包含了很大的哈希表。于是我采用了指针的指针,在构造函数中声明它,解决了这个异常,贴上代码:
class Word_operater
{
private:
//node *hash_table[18280] = { NULL };//哈希表
node **hash_table = NULL;
int words_cnt;
public:
string word_str[10] = {""};
int word_times[10] = {0};
Word_operater()
{
hash_table = new node*[18280];
memset(hash_table,0,sizeof(node*)*18280);
words_cnt = 0;
for (int i = 0; i <= 18279; i++)//初始化整个结构体指针数组
{
hash_table[i] = new node("", 0);
}
for (int j = 0; j < 10; j++)
{
word_str[j] = "";
word_times[j] = 0;
}
}
- 对于只有一个输入参数的情况(argc = 0):
if (argc == 1)
{
filename = "input.txt";
//cin >> filename;
}
else if (argc==2)
{
filename = argv[1];
}
7. 作业心得
- 本次作业虽然说不难,但是每一个部分都需要精心的设计与准备。由于自己担任了新生班导的工作,在时间上有些力不从心。我尽全力挤出了一天可用的时间来完成作业,终于在快接近ddl的今天完成了最后的要求。可能是自己的时间安排不合理,没有一个完整的规划,也要提高自己的效率。最后发表一下自己的感慨啊:软工实践真的可以充实自己的每一天。
- 因为自己好久都没有编码,对C++也不是那么的熟悉,许多东西也是从博客中慢慢学习,请教同学,慢慢的掌握与熟悉。这个过程,让自己复习了许多变得生疏的知识,也提醒着自己有很多知识的盲区。日后也要复习并学习一些相关知识,备战最后的团队作业!
- 看了邹欣老师的构建之法,也拜读了一些大牛的博客,觉得这次作业的目的不是完成那些功能,而是学习软件工程中的重要思想,比如封装,这个是我的亲身经历,好的封装一定可以提高编程时的效率。面向对象的思想,也让编码看起来不那么枯燥,比如我想要统计字符数,我就实例化一个“字符统计机”把东西都给他,他就会马上给我结果。是不是觉得很生动哈哈哈。同时本次作业的第二个目的,我觉得是让我们熟悉
VS这个“宇宙第一ide”,以前觉得VS与dev-c++没事么不同,这样用来才发现其中的不同。 - 在阅读构建之法的时候,邹欣老师提出了一系列程序员存在的问题。反思自身,发现这些问题在自己身上也有出现。就比如编码前,不去思考,直接上去就打代码。没有构思的过程,写出的程序很乱,可读性也不好,在封装的时候也花费了我很多的时间。在以后的作业中,我会专门用一些时间来规划整个程序的架构,这样写起代码也会得心应手很多。正如柯老师说的那样“最不会打代码的人,才着急去打代码”。