Flink中的数据交换是围绕着下面的原则设计的:
1.数据交换的控制流(即,为了启动交换而传递的消息)是由接收者发起的,就像原始的MapReduce一样。
2.用于数据交换的数据流,即通过电缆的实际数据传输,被抽象为了IntermediateResult,并且是可插拔的。 这意味着系统可以使用同一实现同时支持流数据传输和批处理数据传输。
数据交换也涉及到了一些角色,包括:
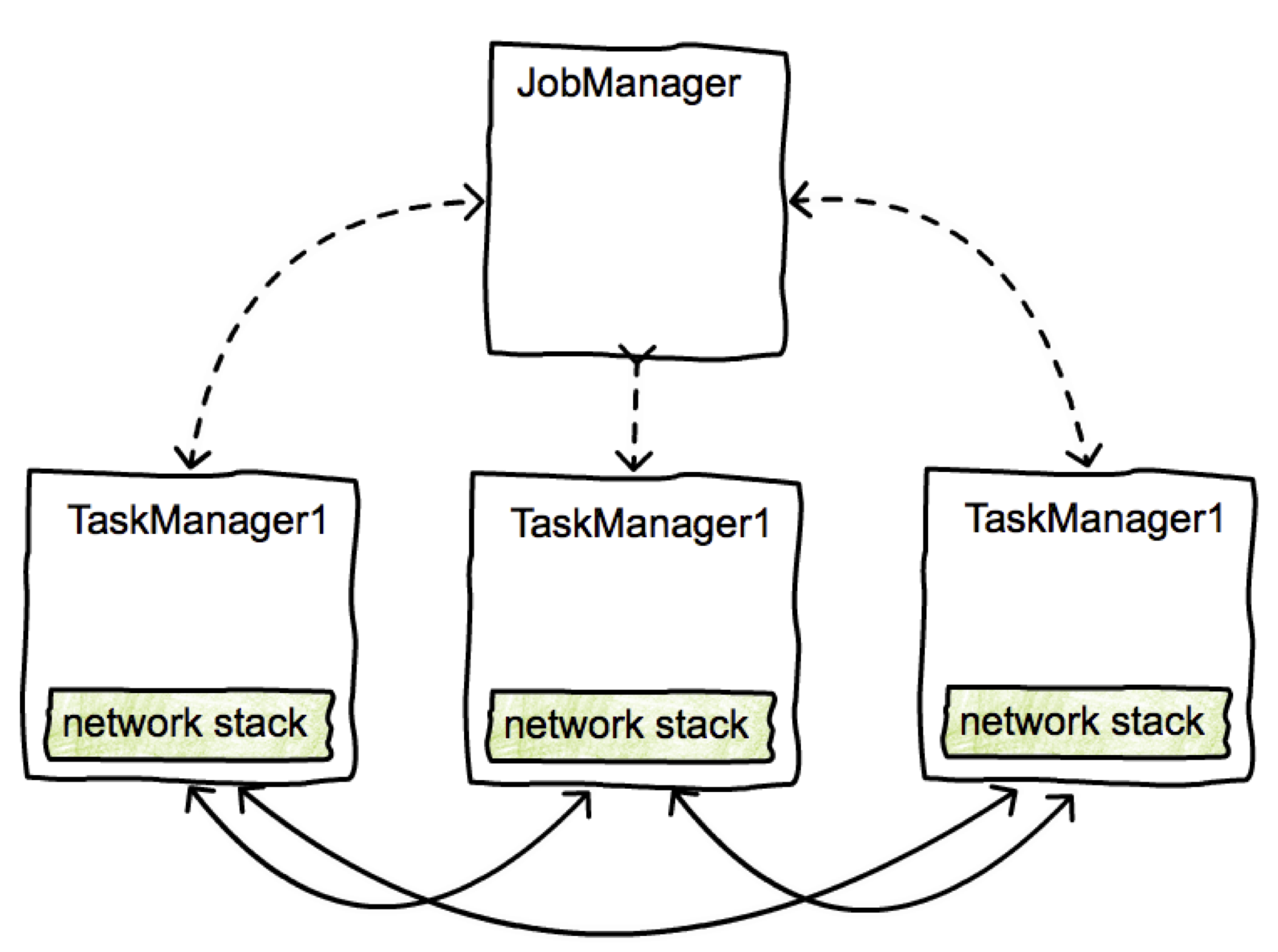
1.JobManager,master节点,负责任务调度,异常恢复,任务协调,并且通过ExecutionGraph这样的数据结构来保存一个作业的全景图。
2.TaskManagers,工作节点,负责将多个任务并行的在线程中执行,每个TM中包含一个CommunicationManager(在tasks之间共享)和一个MemoryManager (在tasks之间共享)。TM之间通过TCP连接来交互数据。
需要注意的是,在Flink中,数据交换是发生在TM之间的,而不是task之间,在同一个TM中的不同task会复用同一个网络连接。
ExecutionGraph,执行图是一个数据结构,其中包含有关作业计算的“基本事实”。 它由代表计算任务的顶点(ExecutionVertex)和代表任务产生的数据的中间结果(IntermediateResultPartition)组成。 顶点通过ExecutionEdges(EE)链接到它们消耗的中间结果:

这些是JobManager中存在的逻辑数据结构。它们具有与运行时等效的结构,这些结构负责TaskManager上的实际数据处理。与IntermediateResultPartition等效的运行时称为ResultPartition。
ResultPartition(RP)表示BufferWriter写入的数据块,即单个任务产生的数据块。 RP是结果子分区(RS)的集合。这是为了区分发往不同接收者的数据,例如,在用于reduce或join的分区混洗的情况下。
ResultSubpartition(RS)表示由operator创建的数据的一个分区,以及将数据转发给接收operator的逻辑。 RS的特定实现确定了实际的数据传输逻辑,这是允许系统支持各种数据传输的可插拔机制。例如,PipelinedSubpartition是支持流数据交换的管道实现。 SpillableSubpartition是一个阻止实现,支持批量数据交换。
InputGate:接收方RP的逻辑等效项。 它负责收集数据缓冲区并将其移交给上游。
InputChannel:接收方RS的逻辑等效项。 它负责为特定分区收集数据缓冲区。
序列化器和反序列化器将类型化的记录可靠地转换为原始字节缓冲区,反之亦然,处理跨越多个缓冲区的记录等。
Control flow for data exchange
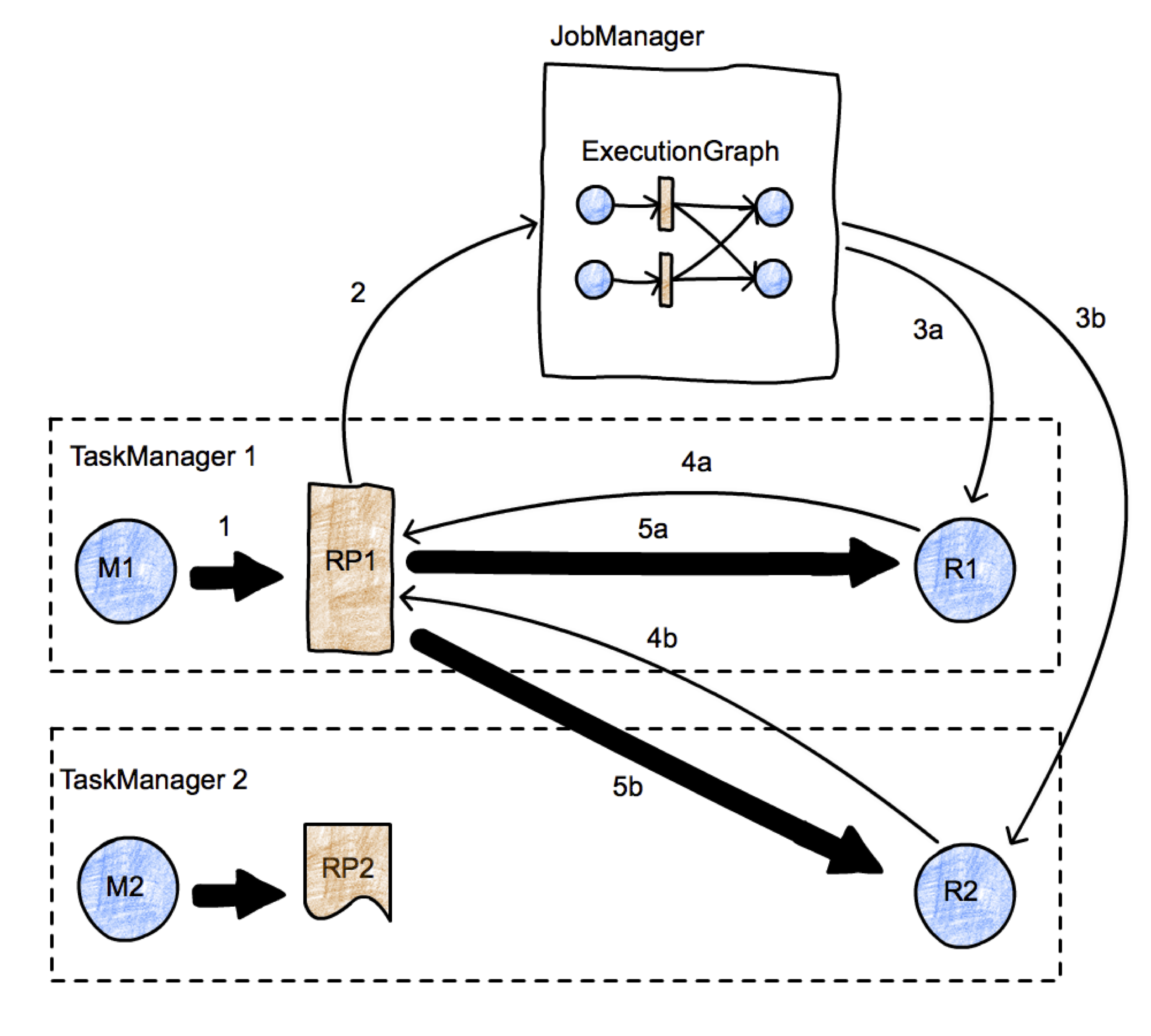
该图片表示具有两个并行任务的简单map-reduce作业。我们有两个TaskManager,两个任务(一个映射任务和一个reduce任务)在两个不同的节点中运行,一个JobManager在第三个节点中运行。我们专注于任务M1和R2之间转移的启动。数据传输使用粗箭头表示,消息使用细箭头表示。首先,M1产生一个ResultPartition(RP1)(箭头1)。当RP可供消费时(我们稍后再讨论),它会通知JobManager(箭头2)。 JobManager通知该分区(任务R1和R2)的预期接收者该分区已准备就绪。如果尚未安排接收方,则实际上将触发任务的部署(箭头3a,3b)。然后,接收器将向RP请求数据(箭头4a和4b)。这将在本地(案例5a)或通过TaskManagers的网络堆栈(5b)启动任务之间的数据传输(箭头5a和5b)。当RP决定将其可用性通知JobManager时,该过程具有一定的自由度。例如,如果RP1在通知JM之前完全产生了自身(并且可能已写入文件中),则数据交换大致相当于Hadoop中实现的批量交换。如果RP1在产生第一个记录后立即通知JM,我们就可以进行流数据交换。
Transfer of a byte buffer between two tasks

序列化程序将记录序列化为它们的二进制表示形式,并将它们放置在固定大小的缓冲区中(记录可以跨越多个缓冲区)。这些缓冲区并移交给BufferWriter并写出到ResultPartition(RP)。 RP由几个子分区(ResultSubpartitions-RS)组成,这些子分区收集特定使用者的缓冲区。在图中,该缓冲区发往第二个reducer(在TaskManager 2中),并将其放置在RS2中。由于这是第一个缓冲区,因此RS2可供使用(请注意,此行为实现了流式分发),并通知JobManager。
JobManager查找RS2的使用者,并通知TaskManager 2可用数据块。发送到TM2的消息向下传播到应该接收此缓冲区的InputChannel,后者进而通知RS2可以启动网络传输。然后,RS2将缓冲区移交给TM1的网络堆栈,后者又将其移交给Netty进行运输。网络连接是长期运行的,并且存在于TaskManager之间,而不是单个任务之间。
一旦TM2接收到缓冲区,它就会通过相似的对象层次结构,从InputChannel(与IRPQ等效的接收器端)开始,到达InputGate(包含多个IC),最后在RecordDeserializer中结束,从缓冲区生成类型化的记录,并将其交给接收任务,在这种情况下为ReduceDriver。