一图道尽心酸:
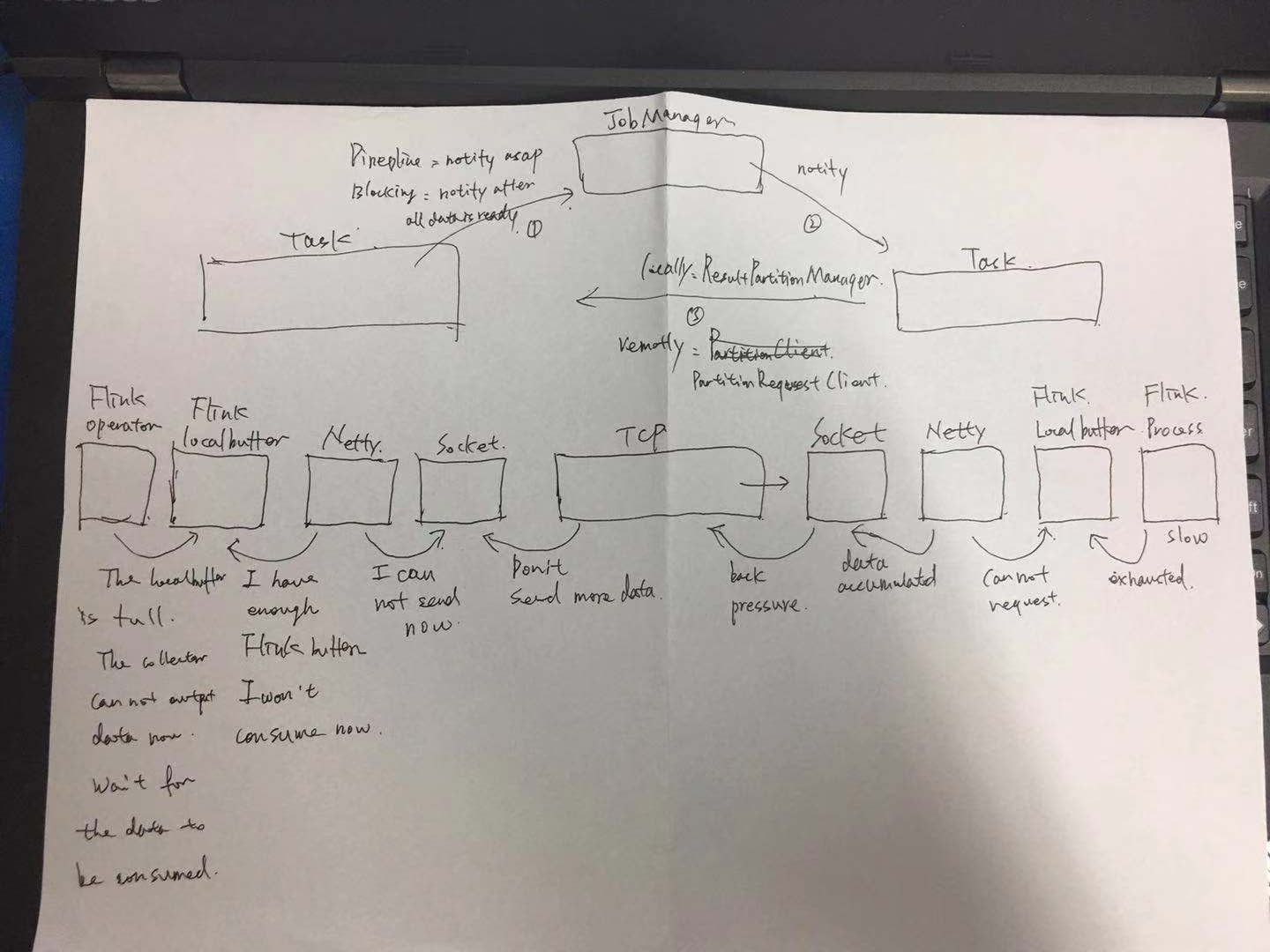
大的原理,上游的task产生数据后,会写在本地的缓存中,然后通知JM自己的数据已经好了,JM通知下游的Task去拉取数据,下游的Task然后去上游的Task拉取数据,形成链条。
但是在何时通知JM?这里有一个设置,比如pipeline还是blocking,pipeline意味着上游哪怕产生一个数据,也会去通知,blocking则需要缓存的插槽存满了才会去通知,默认是pipeline。
虽然生产数据的是Task,但是一个TaskManager中的所有Task共享一个NetworkEnvironment,下游的Task利用ResultPartitionManager主动去上游Task拉数据,底层利用的是Netty和TCP实现网络链路的传输。
那么,一直都在说Flink的背压是一种自然的方式,为什么是自然的了?
从上面的图中下面的链路中可以看到,当下游的process逻辑比较慢,无法及时处理数据时,他自己的local buffer中的消息就不能及时被消费,进而导致netty无法把数据放入local buffer,进而netty也不会去socket上读取新到达的数据,进而在tcp机制中,tcp也不会从上游的socket去读取新的数据,上游的netty也是一样的逻辑,它无法发送数据,也就不能从上游的localbuffer中消费数据,所以上游的localbuffer可能就是满的,上游的operator或者process在处理数据之后进行collect.out的时候申请不能本地缓存,导致上游的process被阻塞。这样,在这个链路上,就实现了背压。
如果还有相应的上游,则会一直反压上去,一直影响到source,导致source也放慢从外部消息源读取消息的速度。一旦瓶颈解除,网络链路畅通,则背压也会自然而然的解除。