在flink的数据传输过程中,有两类数据,一类数据是控制流数据,比如提交作业,比如连接jm,另一类数据是业务数据。flink对此采用了不同的传输机制,控制流数据的传输采用akka进行,业务类数据传输在自己实现了序列化框架的前提下使用netty进行。之所以采用akka进行控制流数据的传送,是因为akka支持异步调用,并且支持良好的并发模型。所以,了解一下akka进行消息传送的知识,也有助于理解flink的作业运行逻辑。
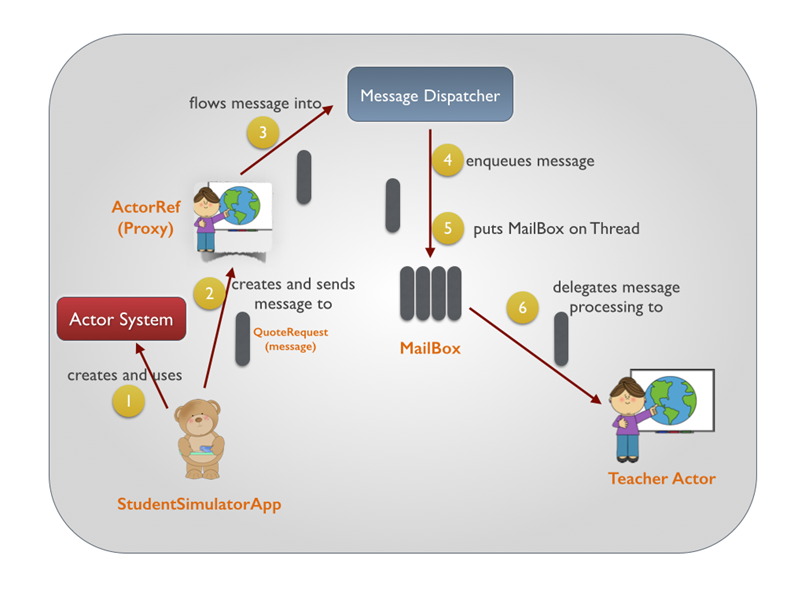
这张图反映了一个典型的消息发送过程,所有的这些对象,actor,mailbox,dispathcer等等,都存在于一个叫actorSystem的对象中。而actorSystem同时也持有一个根actor,它是所有用户创建actor的父类,如下图。

ActorSystem是进入到Actor的世界的一扇大门。通过它你可以创建或中止Actor。甚至还可以把整个Actor环境给关闭掉。另一方面来说,Actor是一个分层的结构,ActorSystem之于Actor有点类似于java.lang.Object或者scala.Any的角色——也就是说,它是所有Actor的根对象。当你通过ActorSystem的actorOf方法创建了一个Actor时,你其实创建的是ActorSystem下面的一个Actor。
对于一个actorSystem而言,主要的成员变量包含以下几个:
provider:ActorRefProvider,实际创建actor的工厂
guardian:InternalActorRef,用户创建actor的监管者
systemGuardian:InternalActorRef,系统创建actor的监管者
threadFactor:ThreadFactory,事件运行线程池模型
mailboxes:Mailboxes,存放事件的邮箱
dispatcher:ExecutionContextExecutor,负责事件分发的分发器
deadLetters:ActorRef,一个接受deadLetter的actor
而上面需要解释的一个概念是邮箱:MailBox
默认的邮箱是UnboundedMailbox,底层其实是一个java.util.concurrent.ConcurrentLinkedQueue,它非阻塞并且无界。初次之外,akka提供了很多别的邮箱,包括SingleConsumerOnlyUnboundedMailbox、NonBlockingBoundedMailbox、UnboundedControlAwareMailbox、UnboundedPriorityMailbox、UnboundedStablePriorityMailbox等等,可以根据不同的使用场景进行配置。
另一个比较重要的概念是分发器,默认的分发器就是Dispatcher,这个模型中,每个actor都有自己的邮箱,但是他们共享一个dispatcher,这个dispatcher可以运行在不同的线程池模型上,默认的线程池模型是fork-join-executor,这个分发器是专门为非阻塞模型优化。

还有Pinned dispatcher,这个模型中每个actor有一个自己的邮箱,同时有自己的只有一个线程的线程池,不同actor之间的线程不会共享,并且底层只支持thread-pool-executor。这个模型适合于处理阻塞任务,因为他们跑在不同的线程中,比如耗时的IO操作。

除此之外还有balancing dispatcher,这个模式将尝试从繁忙的actor重新分配工作到空闲的actor。 所有actor共享单个邮箱,并从中获取他们的消息。 这里假定所有使用此调度器的actor都可以处理发送到其中一个actor的所有的消息;即actor属于actor池,并且对客户端来说没有保证来决定哪个actor实例实际上处理某个特定的消息。 可共享性:仅对同一类型的Actor共享 邮箱:任意,为所有的Actor创建一个 使用场景:Work-sharing 底层驱动:java.util.concurrent.ExecutorService 通过”executor”指定,可使用 “fork-join-executor”, “thread-pool-executor” 或akka.dispatcher.ExecutorServiceConfigurator的限定 请注意不能将BalancingDispatcher用作一个路由器调度程序。
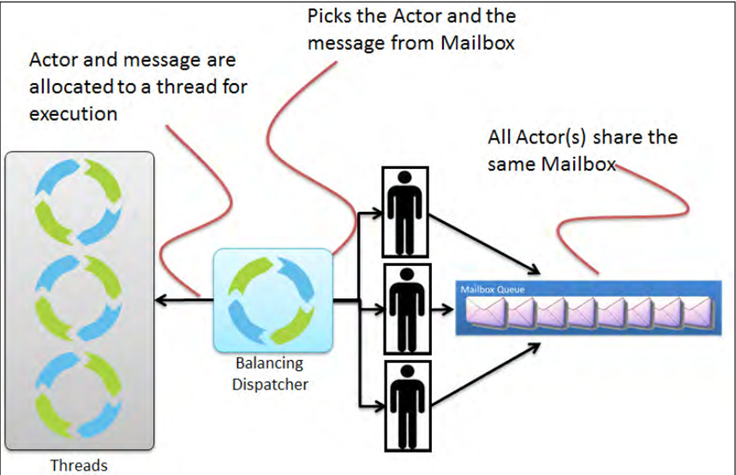
OK,在了解了基础知识之后,我们来串一下发消息的流程:
1 ActorRef 2 def !(message: Any)(implicit sender: ActorRef = Actor.noSender) = underlying.sendMessage(message, sender 3 Dispatch 4 def sendMessage(msg: Envelope): Unit = 5 try { 6 if (system.settings.SerializeAllMessages) { 7 val unwrapped = (msg.message match { 8 case DeadLetter(wrapped, _, _) ⇒ wrapped 9 case other ⇒ other 10 }).asInstanceOf[AnyRef] 11 if (!unwrapped.isInstanceOf[NoSerializationVerificationNeeded]) { 12 val s = SerializationExtension(system) 13 s.deserialize(s.serialize(unwrapped).get, unwrapped.getClass).get 14 } 15 } 16 dispatcher.dispatch(this, msg) 17 } catch handleException
当我们通过!来发送消息,最后会调用到16行的dispatcher.dispatch方法。
1 protected[akka] def dispatch(receiver: ActorCell, invocation: Envelope): Unit = { 2 protected[akka] def dispatch(receiver: ActorCell, invocation: Envelope): Unit = { 3 val mbox = receiver.mailbox 4 mbox.enqueue(receiver.self, invocation) 5 registerForExecution(mbox, true, false) 6 } 7 8 protected[akka] override def registerForExecution(mbox: Mailbox, hasMessageHint: Boolean, hasSystemMessageHint: Boolean): Boolean = { 9 if (mbox.canBeScheduledForExecution(hasMessageHint, hasSystemMessageHint)) { //This needs to be here to ensure thread safety and no races 10 if (mbox.setAsScheduled()) { 11 try { 12 executorService execute mbox 13 true 14 } catch { 15 case e: RejectedExecutionException ⇒ 16 try { 17 executorService execute mbox 18 true 19 } catch { //Retry once 20 case e: RejectedExecutionException ⇒ 21 mbox.setAsIdle() 22 eventStream.publish(Error(e, getClass.getName, getClass, "registerForExecution was rejected twice!")) 23 throw e 24 } 25 } 26 } else false 27 } else false 28 }
这其中的关键在于12行,使用底层的线程池模型来执行这个mbox,当然,mbox能执行的前提是他本身是一个runnable对象,提交即意味着执行其中的run方法。
1 MailBox 2 override final def run(): Unit = { 3 try { 4 if (!isClosed) { //Volatile read, needed here 5 processAllSystemMessages() //First, deal with any system messages 6 processMailbox() //Then deal with messages 7 } 8 } finally { 9 setAsIdle() //Volatile write, needed here 10 dispatcher.registerForExecution(this, false, false) 11 } 12 }
其中processAllSystemMessage方法处理类似watch之类的系统消息,processMailBox处理用户消息。
1 MailBox 2 @tailrec private final def processMailbox( 3 left: Int = java.lang.Math.max(dispatcher.throughput, 1), 4 deadlineNs: Long = if (dispatcher.isThroughputDeadlineTimeDefined == true) System.nanoTime + dispatcher.throughputDeadlineTime.toNanos else 0L): Unit = 5 if (shouldProcessMessage) { 6 val next = dequeue() 7 if (next ne null) { 8 if (Mailbox.debug) println(actor.self + " processing message " + next) 9 actor invoke next 10 if (Thread.interrupted()) 11 throw new InterruptedException("Interrupted while processing actor messages") 12 processAllSystemMessages() 13 if ((left > 1) && ((dispatcher.isThroughputDeadlineTimeDefined == false) || (System.nanoTime - deadlineNs) < 0)) 14 processMailbox(left - 1, deadlineNs) 15 } 16 }
processMailBox的关键在于第9行的代码,真正调用这个actor本身来执行next这个消息。这里的dispatcher.throughput限制了每次执行的消息条数。
1 Actor 2 final def invoke(messageHandle: Envelope): Unit = try { 3 currentMessage = messageHandle 4 cancelReceiveTimeout() // FIXME: leave this here??? 5 messageHandle.message match { 6 case msg: AutoReceivedMessage ⇒ autoReceiveMessage(messageHandle) 7 case msg ⇒ receiveMessage(msg) 8 } 9 currentMessage = null // reset current message after successful invocation 10 } catch handleNonFatalOrInterruptedException { e ⇒ 11 handleInvokeFailure(Nil, e) 12 } finally { 13 checkReceiveTimeout // Reschedule receive timeout 14 }
invoke方法中,紧接着调用了receiveMessage方法。
1 Actor 2 final def receiveMessage(msg: Any): Unit = actor.aroundReceive(behaviorStack.head, msg) 3 4 protected[akka] def aroundReceive(receive: Actor.Receive, msg: Any): Unit = receive.applyOrElse(msg, unhandled)
这里终于看到了我们在实现一个actor的时候必然要实现的receiver方法,它在第4行最终被调用。
那么同时能够存在多少个actor执行任务了?那就要看fork-join-pool中提供的线程的个数,以及提交的actor在执行任务的时候需要的线程个数了。虽然每一个actor在执行的时候可以触发的消息个数是有最大值的,但是同时在执行的actor的个数应该是动态的。如果某一个actor使用了线程池中所有的线程,那可能其他actor就没法同时执行,如果大多数actor都只使用一个线程触发消息,则可以同时有多个actor在线程池中运行。但如果相互之间有发送消息,则只有等待,不过,akka本身就是异步的,对于大多数消息而言,发送消息之后就不管了,只等着对方处理完毕之后再发送消息给自己来实现回调。
在flink中提供了大量的默认的akka的配置,比较重要的几个如下:
1 akka.ask.timeout:10s 阻塞操作,可能因为机器繁忙或者网络堵塞导致timeout,可以尝试设置大一点。 2 akka.client.timeout:60s 在client端的全部阻塞操作的时长 3 akka.fork-join-executor.parallelism-factor:2.0 ceil(available processors*factor) bounded by the min and max 4 akka.fork-join-executor.parallelism-max:64 5 akka.fork-join-executor.parallelism-min:8 6 akka.framesize:10485760b,1.25MB JM和TM之间传输的最大的消息值 7 akka.lookup.timeout:10s 找JM的时间 8 akka.retry-gate-closed-for:50 如果远端的链接断开,多少毫秒之内,gate应该关闭 9 akka.throughput:15 每个调度周期能够处理的消息的最大值,小的值意味着公平,大的值意味着效率
参考了如下的地址,感谢。
https://blog.csdn.net/pzw_0612/article/details/47385177
https://www.cnblogs.com/devos/p/4438402.html
https://blog.csdn.net/birdben/article/details/49796923