1 spark streaming
1.1 Spark Streaming 介绍
批量计算

流计算

1.2 Spark Streaming 入门
Netcat 的使用

项目实例
目标:使用 Spark Streaming 程序和 Socket server 进行交互, 从 Server 处获取实时传输过来的字符串, 拆开单词并统计单词数量, 最后打印出来每一个小批次的单词数量

步骤:
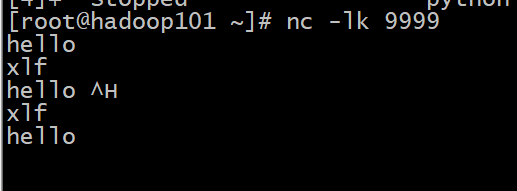
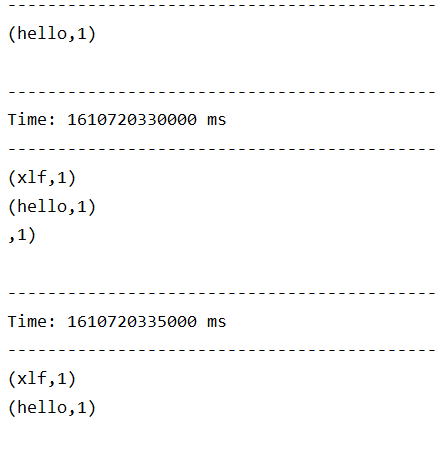
开始进行交互:
注意:
Spark Streaming 并不是真正的来一条数据处理一条
Spark Streaming 的处理机制叫做小批量, 英文叫做 mini-batch, 是收集了一定时间的数据后生成 RDD, 后针对 RDD 进行各种转换操作, 这个原理提现在如下两个地方
- 控制台中打印的结果是一个批次一个批次的, 统计单词数量也是按照一个批次一个批次的统计
- 多长时间生成一个
RDD去统计呢? 由new StreamingContext(sparkConf, Seconds(1))这段代码中的第二个参数指定批次生成的时间
Spark Streaming 中至少要有两个线程
在使用 spark-submit 启动程序的时候, 不能指定一个线程
- 主线程被阻塞了, 等待程序运行
- 需要开启后台线程获取数据
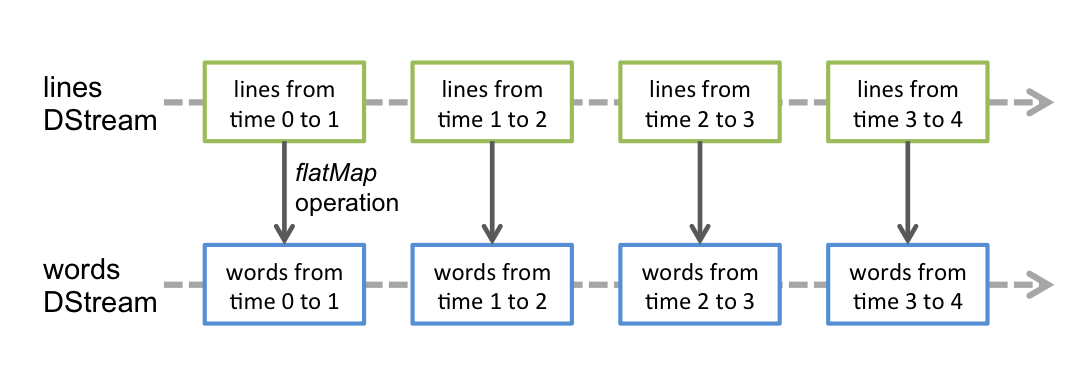
1.3 各种算子
-
这些算子类似
RDD, 也会生成新的DStream -
这些算子操作最终会落到每一个
DStream生成的RDD中
| 算子 | 释义 |
|---|---|
|
|
将一个数据一对多的转换为另外的形式, 规则通过传入函数指定 |
|
|
一对一的转换数据 |
|
|
这个算子需要特别注意, 这个聚合并不是针对于整个流, 而是针对于某个批次的数据 |
2 Structured Streaming
2.1 Spark 编程模型的进化过程
| 编程模型 | 解释 |
|---|---|
|
|
|
|
|
|
|
|
|
2.2 Spark Streaming 和 Structured Streaming
Spark Streaming 时代

-
Spark Streaming其实就是RDD的API的流式工具, 其本质还是RDD, 存储和执行过程依然类似RDD
Structured Streaming 时代
-
Structured Streaming其实就是Dataset的API的流式工具,API和Dataset保持高度一致
Spark Streaming 和 Structured Streaming
-
Structured Streaming相比于Spark Streaming的进步就类似于Dataset相比于RDD的进步 -
另外还有一点,
Structured Streaming已经支持了连续流模型, 也就是类似于Flink那样的实时流, 而不是小批量, 但在使用的时候仍然有限制, 大部分情况还是应该采用小批量模式
在 2.2.0 以后 Structured Streaming 被标注为稳定版本, 意味着以后的 Spark 流式开发不应该在采用 Spark Streaming 了
2.1 Structured Streaming 入门案例
需求
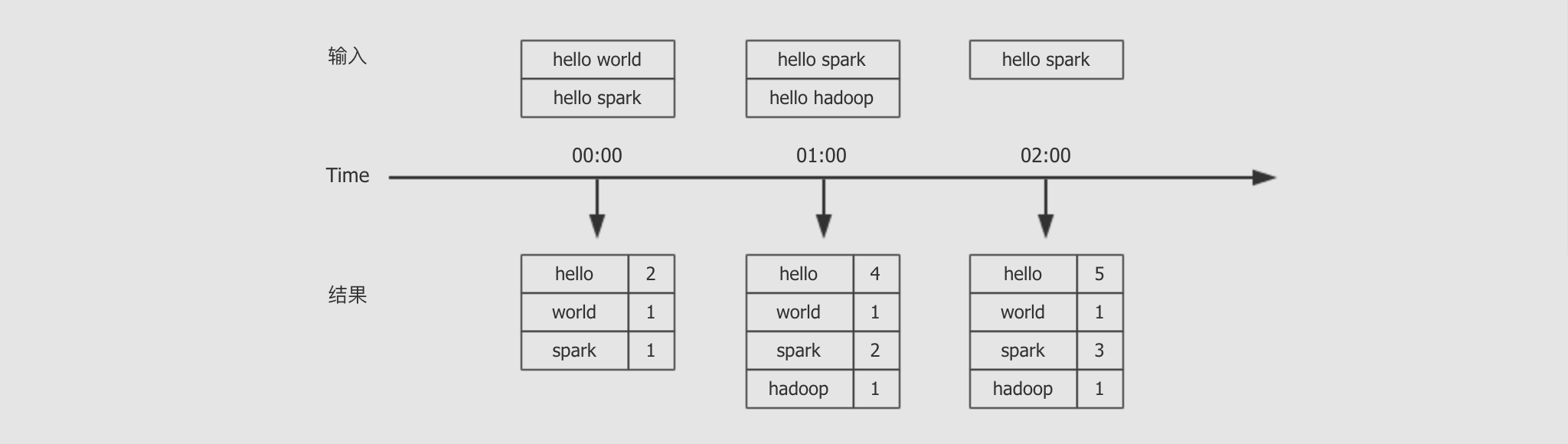
-
编写一个流式计算的应用, 不断的接收外部系统的消息
-
对消息中的单词进行词频统计
-
统计全局的结果
步骤:
交互结果:
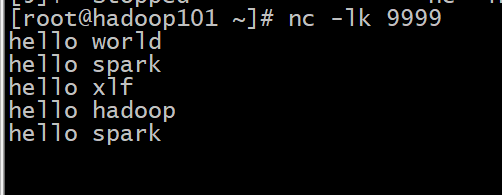
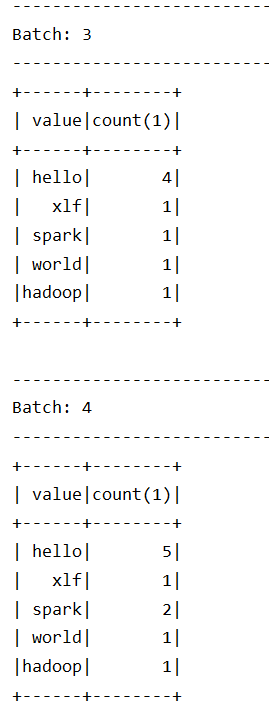
从结果集中可以观察到以下内容
-
Structured Streaming依然是小批量的流处理 -
Structured Streaming的输出是类似DataFrame的, 也具有Schema, 所以也是针对结构化数据进行优化的 -
从输出的时间特点上来看, 是一个批次先开始, 然后收集数据, 再进行展示, 这一点和
Spark Streaming不太一样
2.1 从 HDFS 中读取数据
使用 Structured Streaming 整合 HDFS, 从其中读取数据的能力
步骤
-
案例结构
-
产生小文件并推送到
HDFS -
流式计算统计
HDFS上的小文件 -
运行和总结
实验步骤:
Step1:利用py产生文件源源不断向hdfs上传文件
Step2:编写 Structured Streaming 程序处理数据
py代码:
spark处理流式文件
总结

-
Python生成文件到HDFS, 这一步在真实环境下, 可能是由Flume和Sqoop收集并上传至HDFS -
Structured Streaming从HDFS中读取数据并处理 -
Structured Streaming讲结果表展示在控制台