spark环境搭建
1 下载并上传
官网下载:下载 Spark 安装包, 下载时候选择对应的 Hadoop 版本,然后上传到虚拟机上
2 解压并拷贝
3 修改配置文件
3.1 配置 spark-env.sh 文件
- 进入配置目录, 并复制一份新的配置文件, 以供在此基础之上进行修改
- 将以下内容复制进配置文件末尾
3.2 配置 slaves 文件
修改配置文件 slaves, 以指定从节点为止, 从在使用 sbin/start-all.sh 启动集群的时候, 可以一键启动整个集群所有的 Worker
- 进入配置目录, 并复制一份新的配置文件, 以供在此基础之上进行修改
- 配置所有从节点的地址
3.3 配置 HistoryServer
默认情况下, Spark 程序运行完毕后, 就无法再查看运行记录的 Web UI 了, 通过 HistoryServer 可以提供一个服务, 通过读取日志文件, 使得我们可以在程序运行结束后, 依然能够查看运行过程
- 复制
spark-defaults.conf, 以供修改
- 将以下内容复制到末尾处, 通过这段配置, 可以指定 Spark 将日志输入到 HDFS 中
- 将以下内容复制到 ' spark-env.sh ' 的末尾, 配置 HistoryServer 启动参数, 使得 HistoryServer 在启动的时候读取 HDFS 中写入的 Spark 日志
- 为 Spark 创建 HDFS 中的日志目录
4 分发和运行
- 将 Spark 安装包分发给集群中其它机器
- 启动 Spark Master 和 Slaves, 以及 HistoryServer
5 Spark 集群高可用搭建
对于 Spark Standalone 集群来说, 当 Worker 调度出现问题的时候, 会自动的弹性容错, 将出错的 Task 调度到其它 Worker 执行
但是对于 Master 来说, 是会出现单点失败的, 为了避免可能出现的单点失败问题, Spark 提供了两种方式满足高可用
-
使用 Zookeeper 实现 Masters 的主备切换
-
使用文件系统做主备切换
5.1 停止 Spark 集群
5.2 修改配置文件
增加 Spark 运行时参数, 从而指定 Zookeeper 的位置
- 进入
spark-env.sh
- 编辑
spark-env.sh, 添加 Spark 启动参数, 并去掉 SPARK_MASTER_HOST 地址

5.3 分发配置文件到整个集群
5.4 启动
在 node01 上启动整个集群
在 node02 上单独再启动一个 Master
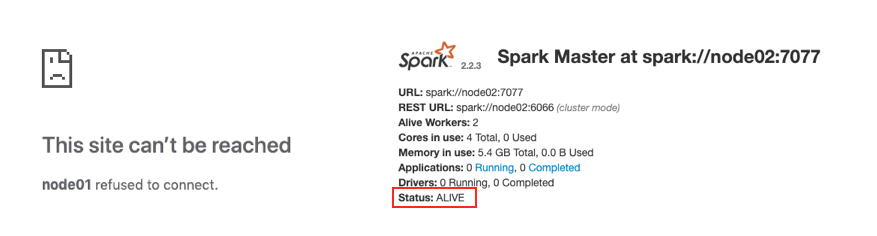
5.5 查看 node01 master 和 node02 master 的 WebUI
- http://node01:8080 一个是
ALIVE(主), 另外一个是STANDBY(备)

- 如果关闭一个, 则另外一个成为'ALIVE'