第二次作业
任务一:
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
第一步:爬取特定城市数据
虽然课本上有现成的,但是还是想复原所有的过程所以打开网页观察html文本
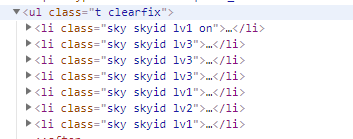
思路:配出所需要的soup->select语句->文本信息
代码如下:
"""
任务一:(1)在指定网站上,爬取七日数据
"""
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
target_url = "http://www.weather.com.cn/weather/101220301.shtml"#这个网址是含有七天的天气情况
headers = {
"User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64; en-US;rv:1,9pre)Gecko/2008072421 Minefield/3.0.2pre"}
req = urllib.request.Request(target_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])#选取适合的编码模式
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
# 以上都是相似的模板 #
lis = soup.select('ul[class="t clearfix"] li')#每一个日期下所在的标签tag
# 读取数据,得到目标
for li in lis:
date = li.select('h1')[0].text#获取日期的信息
weather = li.select('p[class="wea"]')[0].text #获取天气的信息
temp = li.select('p[class="tem"] i')[0].text#获取气温的信息
winds = li.select('p[class="win"] span') # 特殊的文本在属性里
win3 = li.select('p[class="win"] i')[0].text #风级
for wind in winds:#
win1 = wind["title"]
win2 = wind["class"] #属性的文本提取
win = str(win1) + str(win2)+str(win3)#直接相加会报错,所以用str转化,还可以用append(但是我好想忘了之后可能会补充一下)
print(date, weather, temp,win)
结果

第二步:建立数据库
一开始的做法得到的结果
由于防止被评定为抄袭加入一开始想引进的参数(风向)
代码如下:

"""
任务一:(2)建立数据库
"""
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class WeatherDataBase: # 第二步的主要结果体现在于数据库的构建
def openDB(self): # 数据库的知识不太清楚应该是先定义一些基本操作:增删改查(关系数据库)
self.con = sqlite3.connect("weather1.db")
# 建议每次操作的时候将一开始的db删除,否则db名称不变但是添加新的数据类型属性之类会报错 要是新建的db会浪费空间#
self.cursor = self.con.cursor()
try:
self.cursor.execute(
"create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),wWind varchar(128),constraint pk_weather primary key(wCity,wDate)) ")
# 添加了新的类型风向#
except:
self.cursor.execute("delete from weathers")#里面的内容好像是SQL语句(数据库内容掌握的不是很好
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp, wind): # 多引进参数wind
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp,wWind)values(?,?,?,?,?)",
(city, date, weather, temp, wind))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s%-48s" % ("city", "date", "weather", "temp", "wind"))
for row in rows:
print("%-16s%-16s%-32s%-16s%-48s" % (row[0], row[1], row[2], row[3], row[4]))
class WeatherSourse: # 第一步的改写但也有变化
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64; en-US;rv:1,9pre)Gecko/2008072421 Minefield/3.0.2pre"
}
self.cityCode = {"芜湖": "101220301", "苏州": "101190401", "北京": "101010100", "广州": "101280101"}
# 好像是选取目标的城市在中国天气网的对应代码#
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(city + "can't be found!")
return
target_city_url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(target_city_url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"]) # 选取适合的编码模式
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
# 以上都是相似的模板 #
lis = soup.select('ul[class="t clearfix"] li') # 每一个日期下所在的标签tag
# 读取数据,得到目标
for li in lis:
date = li.select('h1')[0].text # 获取日期的信息
weather = li.select('p[class="wea"]')[0].text # 获取天气的信息
temp = li.select('p[class="tem"] i')[0].text # 获取气温的信息
winds = li.select('p[class="win"] span') # 特殊的文本在属性里
win3 = li.select('p[class="win"] i')[0].text # 风级
for wind in winds: #
win1 = wind["title"]
win2 = wind["class"] # 属性的文本提取
win = str(win1) + str(win2) + str(win3) # 直接相加会报错,所以用str转化,还可以用append(但是我好想忘了之后可能会补充一下)
# 以上都是第一步完成的内容#
self.db.insert(city, date, weather, temp, win)
except Exception as err:
print(err)
def process(self, cities):
self.db = WeatherDataBase()
self.db.openDB()
for city in cities:
self.forecastCity(city)
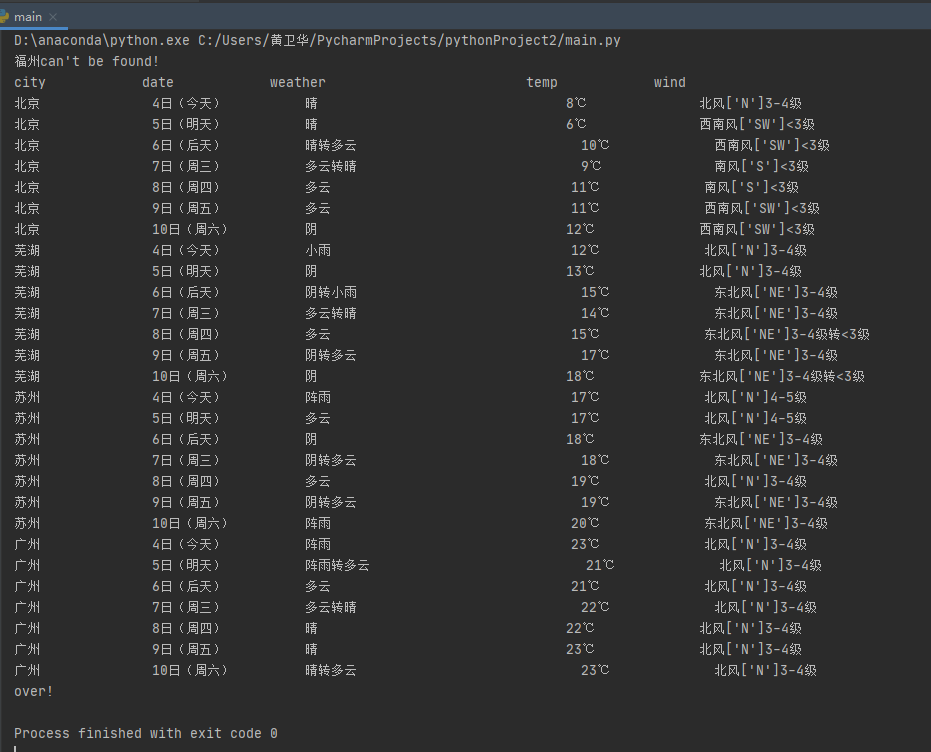
self.db.show()
# 省略print的每行结果将最后的db展示出来
self.db.closeDB()
ws = WeatherSourse()
ws.process(["北京", "芜湖", "苏州", "广州", "福州"])#想验证不存在数据的表示
print("The weather1.db is over!")
心得体会
有的心得体会已经写在注释里面了,讲一讲这个任务给我的感受吧!
难度不是特别大
毕竟书上有代码可以借鉴,而且思路也是很清楚
SQL语句的掌握很明显是是不足的,经常用错想要去改进的地方(第二步的class weatherDateBase中)没有实现
能力不足T-T
然后就是感到自己的重度拖延症>_<
任务二
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
/新浪股票:http://finance.sina.com.cn/stock/
"""
第一次实践:采用的是东方财富网
http://quote.eastmoney.com/center/gridlist.html#hs_a_board
(打开的页面网址)
"""
import requests
import re # 正则表达式
# 打开页面获取数据
def get_info(stock_dic1, page, stock_dic2):
url = "http://87.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124007929044454484524_1601878281258" +
"&pn=" + str(page)
+ "&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f26" +
"&fs=" + stock_dic1
+ "&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152" +
"&_=" + stock_dic2
headers = {"User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;"
"rv:1.9pre)Gecko/200872421Minefield/3.0.2pre"}
req = requests.get(url, headers=headers)
pat = '"diff":[(.*?)]'
data = re.compile(pat, re.S).findall(req.text)
return data # 得到的是一页数据
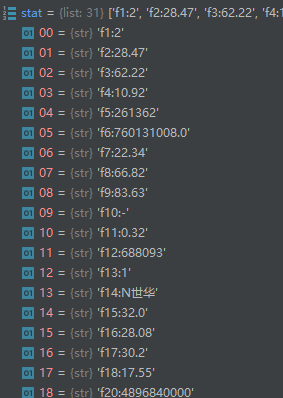
'''得到形如data为
['{"f1":2,"f2":28.47,"f3":62.22,"f4":10.92,"f5":261362,"f6":760131008.0,"f7":22.34,"f8":66.82,
"f9":83.63,"f10":"-","f11":0.32,"f12":"688093","f13":1,"f14":"N世华","f15":32.0,"f16":28.08,
"f17":30.2,"f18":17.55,"f20":4896840000,"f21":1113548391,"f22":0.6,"f23":4.93,"f24":62.22,"f25":62.22,
"f62":69930153.0,"f115":52.19,"f128":"-","f140":"-","f141":"-","f136":"-","f152":2},{"f1":2,"f2":55.
'''
# 获取单个页面信息最后得到一个页面下所有记录
def get_one_page(stock_dic1, page, stock_dic2):
data = get_info(stock_dic1, page, stock_dic2) # 单独一个股票的数据
data_in_one_page = data[0].strip("{").strip("}").split('},{') # 一页股票数据
data_all = [] # 所有股票的数据
before_acc = (page - 1) * 20
acc_in_one_page = 1
for i in range(len(data_in_one_page)):
data_one = data_in_one_page[i].replace('"', "")
total_acc = acc_in_one_page + before_acc
push_info(total_acc, data_one)
data_all.append(data_one)
acc_in_one_page += 1 # 强加序号 #
return data_all
'''得到形如 data_all
['f1:2,f2:28.47,f3:62.22,f4:10.92,f5:261362,f6:760131008.0,f7:22.34,f8:66.82,f9:83.63,f10:-,f11:0.32,f12:688093,f13:1,
f14:N世华,f15:32.0,f16:28.08,f17:30.2,f18:17.55,f20:4896840000,f21:1113548391,f22:0.6,f23:4.93,f24:62.22,f25:62.22,
f62:69930153.0,f115:52.19,f128:-,f140:-,f141:-,f136:-,f152:2', 'f1:2,
'''
# 具体数据得到一条记录
def push_info(acc_in_one_page, data_one_company): # 强行加入序号
'''传入参数的格式
'f1:2,f2:28.47,f3:62.22,f4:10.92,f5:261362,f6:760131008.0,f7:22.34,f8:66.82,f9:83.63,f10:-,f11:0.32,f12:688093,f13:1,f14:N世华,
f15:32.0,f16:28.08,f17:30.2,f18:17.55,f20:4896840000,f21:1113548391,f22:0.6,f23:4.93,f24:62.22,f25:62.22,f62:69930153.0,
f115:52.19,f128:-,f140:-,f141:-,f136:-,f152:2'
'''
stat = data_one_company.split(',')
name = stat[13].split(":")[1]
num = stat[11].split(":")[1]
lastest_pri = stat[1].split(":")[1]
dzf = stat[2].split(":")[1]
dze = stat[3].split(":")[1]
cjl = stat[4].split(":")[1]
cje = stat[5].split(":")[1]
zf = stat[6].split(":")[1]
top = stat[14].split(":")[1]
low = stat[15].split(":")[1]
today = stat[16].split(":")[1]
yestd = stat[17].split(":")[1]
print(acc_in_one_page, name, num, lastest_pri, dzf, dze, cjl, cje, zf, top, low, today, yestd) # 一条记录
# main函数
stock_dic1 = {
"沪深A股": "m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23",
"上证A股": "m:1+t:2,m:1+t:23",
"深证A股": "m:0+t:6,m:0+t:13,m:0+t:80",
"新股": "m:0+f:8,m:1+f:8",
"中小板": "m:0+t:13",
"创业板": "m:0+t:80"
}
stock_dic2 = {
"沪深A股": "1601536578738",
"上证A股": "1601536578736",
"深证A股": "1601536578759",
"新股": "1601536578765",
"中小板": "1601536578882",
"创业板": "1601536578888"
}
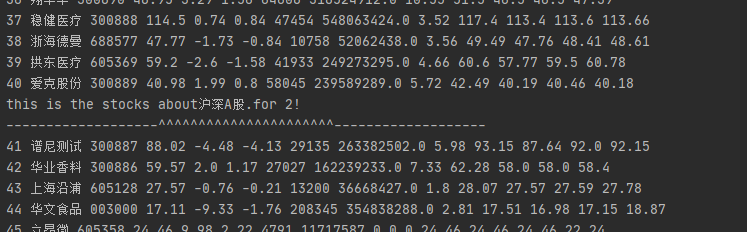
print("序号 ", "代码 ", "名称 ", "最新价 ", "涨跌幅(%) ", "涨跌额 ", "成交量 ", "成交额 ", "振幅(%) ", "最高 ", "最低 ", "今开 ", "昨收 ")
for i in stock_dic1.keys():
print("---------------------------****************---------------------------")
total_acc = 0 # 总计数
page_num = 1 # 第几页的页数
print("this is the stocks about" + i + "." + "for " + str(page_num) + " page !")
stock_all = get_one_page(stock_dic1[i], page_num, stock_dic2[i])
while page_num <= 5: #限制一下页数
page_num += 1
if get_info(stock_dic1[i], page_num, stock_dic2[i]) != get_info(stock_dic1[i], page_num - 1, stock_dic2[i]):
stock_all = get_one_page(stock_dic1[i], page_num, stock_dic2[i])
print("this is the stocks about" + i + "." + "for " + str(page_num) + "!")
print("-------------------^^^^^^^^^^^^^^^^^^^^^^-------------------")
else:
break
print("this is the stocks about" + i + "has finished, for the next!")
print("the task is over")
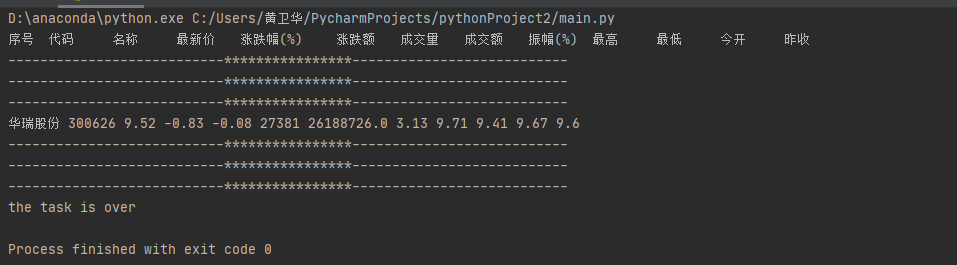
结果如下:开始->同一类型的不同页面->不同股票之间的过渡->结尾部分



心得体会
任务二,对于我而言,有点难,即使有相同的参考资料都改了很长时间;
分析其原因还是对于从网页上的爬取数据的能力欠缺吧!
一开始有想过以不懂的方式将这次试验完成,但是总是报错,然后就一步步的找原因,也许是思路框架不理解还是怎么样,一直到最后还是报错
就重头开始完成,将url打开分析网址到文本信息的提取每一步都debug后最后完成了
嗯,和原来期望差距还是挺大的一开始是想写到Excel里面,但是最后直接将文本信息print出来 挺简单粗暴的方式 T-T
导致结果还是排版不好,之后完成了再看情况是否会修改吧
附上中间找的资料和信息吧(中间debug)

ps:再找不同url的时候可以点击不同的股票过一小会就会发现有的js文件名的不同,不用一个个看
当看到stat里的信息的时候还是很激动!!-
最大收获就是split的replace的运用,和不惧怕杂乱数据的勇气吧!
可以改进的地方应该就是前面两个函数,返回的data其实很混乱,也不是所有都有用到
任务三
要求:根据自选3位数+学号后3位选取股票,获取印股票信息。抓包方法同作业②。
import requests
import re # 正则表达式
# 获取单个页面信息最后得到一个页面下所有记录
def get_one_page(stock_dic1, page, stock_dic2):
url = "http://87.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124007929044454484524_1601878281258" +
"&pn=" + str(page)
+ "&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f26" +
"&fs=" + stock_dic1
+ "&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152" +
"&_=" + stock_dic2 # 所要打开的网址 #
headers = {"User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;"
"rv:1.9pre)Gecko/200872421Minefield/3.0.2pre"}
req = requests.get(url, headers=headers)
pat = '"diff":[(.*?)]' # 选取开始记录数据的起点 #
data = re.compile(pat, re.S).findall(req.text)
data_in_one_page = data[0].strip("{").strip("}").split('},{') # 一页股票数据
data_all = [] # 所有股票的数据
for i in range(len(data_in_one_page)):
data_one = data_in_one_page[i].replace('"', "") # 文本中的将“去除 #
push_info(data_one)
data_all.append(data_one)
# 具体数据得到一条记录
def push_info(data_one_company):
stat = data_one_company.split(',') #将文本以,分开
num = stat[11].split(":")[1] #以:分开读取数据
if str(num).endswith("626"):
name = stat[13].split(":")[1]
lastest_pri = stat[1].split(":")[1]
dzf = stat[2].split(":")[1]
dze = stat[3].split(":")[1]
cjl = stat[4].split(":")[1]
cje = stat[5].split(":")[1]
zf = stat[6].split(":")[1]
top = stat[14].split(":")[1]
low = stat[15].split(":")[1]
today = stat[16].split(":")[1]
yestd = stat[17].split(":")[1]
print(name, num, lastest_pri, dzf, dze, cjl, cje, zf, top, low, today, yestd) # 一条记录
# main函数
stock_dic1 = {
"沪深A股": "m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23",
"上证A股": "m:1+t:2,m:1+t:23",
"深证A股": "m:0+t:6,m:0+t:13,m:0+t:80",
"新股": "m:0+f:8,m:1+f:8",
"中小板": "m:0+t:13",
"创业板": "m:0+t:80"
}
stock_dic2 = {
"沪深A股": "1601536578738",
"上证A股": "1601536578736",
"深证A股": "1601536578759",
"新股": "1601536578765",
"中小板": "1601536578882",
"创业板": "1601536578888"
}
page = 1
print("序号 ", "代码 ", "名称 ", "最新价 ", "涨跌幅(%) ", "涨跌额 ", "成交量 ", "成交额 ", "振幅(%) ", "最高 ", "最低 ", "今开 ", "昨收 ")
for i in stock_dic1.keys():
print("---------------------------****************---------------------------")
get_one_page(stock_dic1[i], page, stock_dic2[i])
while page<= 20: # 限制一下页数
page+=1
get_one_page(stock_dic1[i], page, stock_dic2[i])
print("the task is over")
心得体会
在任务二的基础上所以简单很多,稍作修改即可