the second
作业要求
* 题目:论文查重
1. 描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
2.样例:
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
3.额外要求:
要求输入输出采用文件输入输出,规范如下:
从命令行参数给出:论文原文的文件的绝对路径。 从命令行参数给出:抄袭版论文的文件的绝对路径。 从命令行参数给出:输出的答案文件的绝对路径。
作业
我的思路
- 首先肯定是要处理好从命令行读取路径和结尾输出指定路径
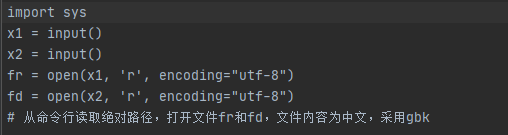
将输入输出更改:
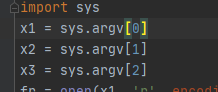
- 做文件处理工作,可以先把这一部分当做黑箱
- 最后按照规定写入数据,并且返回文件的地址(自定义一个文件,如果没有就在指定的路径下新建;但是在自己测试的时候没有这样,是直接返回重复率)
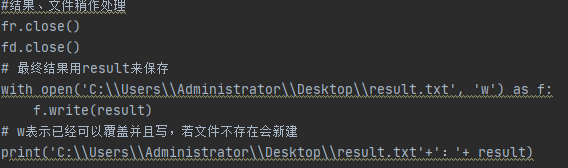
附上我的github的代码:021800626(完整代码、requirements.txt)
(在仓库里文件,命名的时候是随意的然后会有说明每个文件的作用以及自己的感受之类的,和最后一个总的代码)
谈一下我的黑箱:
提前说明:因为是按照自己的想法然后找的资料完成这次作业,没有很按照软工实践的理论上数据结构,数据操作,描述性语句这三部分。基本上是混合起来。这个是有点遗憾的!
我的想法:
其实很简单:灵感来源于一位老师上课讲的文章的特征向量,
然后就想先求出原文件和抄袭文件两个特征向量,
最后一比较就得到重复率(这里的“比较”是余弦相似性)
具体的步骤:
第一步是划定每一个特征向量的坐标也就是后面的stat和stat1要具有一定的可比性(防止有的“汉字”没有同时出现在两个文件)
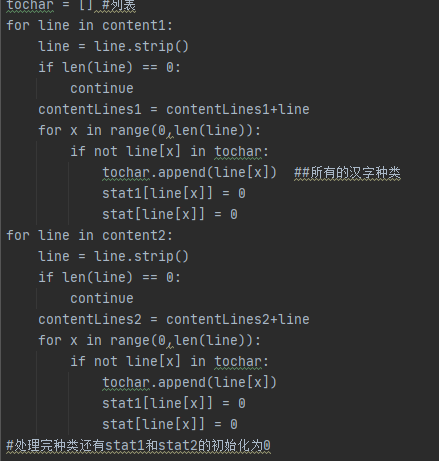
第二步是根据选取的文件分别构建stat和stat1

第三步是余弦相似性公式利用即可

bug可能的出现:
在用python写完所有的步骤后,其实会有很多隐藏的bug:列表,向量和字典这三个数据类型
由于最终的比较是用向量,所以就必需化字典(stat和stat1)为向量,
但是,但是本人能力不足,不会直接字典到向量,所以采用先字典到列表,再列表到向量(基本上也复习了之前学的python的基础)
很显然基本数据类型里面没有向量,所以调用numpy.array(这是找资料得到的)

做完上述的工作基本上没有什么bug(其实也是自己实际运行中出现的)
补充:
数据结构的定义:
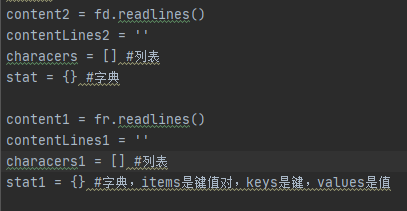
测试
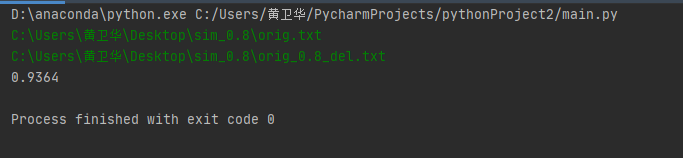
说明:是通过terminal的窗口进入输入直接结果,测试十次用的是给的样本然后输入是绝对路径
基本上应该是可以,但还是存在问题就是了,结果如下:


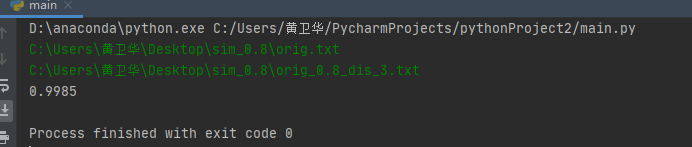
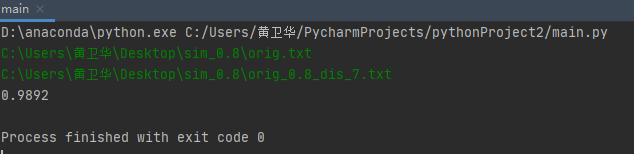
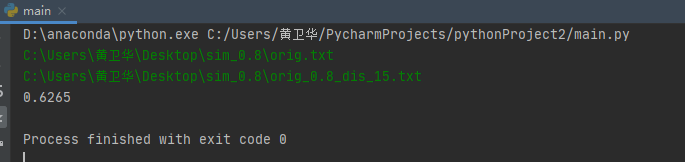
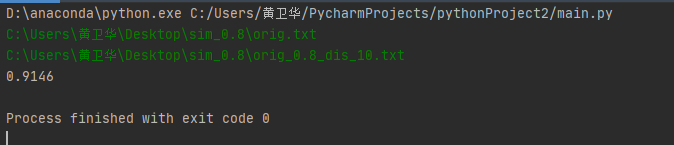
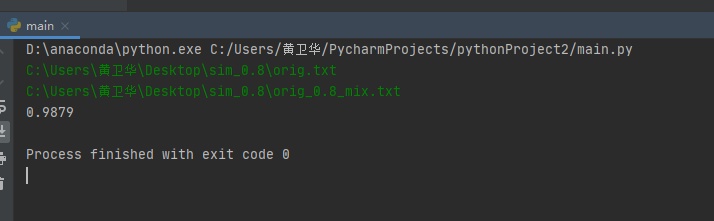
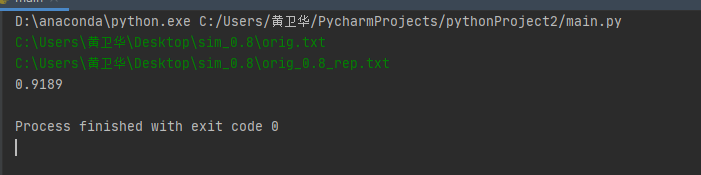
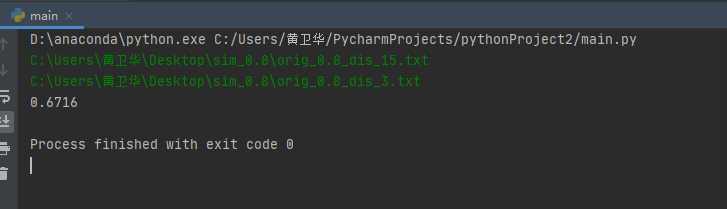
测试性能
分为两步一个时间还有就是覆盖率
时间&内存:
取的是任意一个实例

性能测试补充:

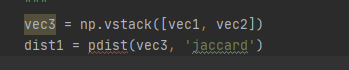
改进方法:
jaccard的距离来衡量
0和异常处理:
不知道题目上结尾输出0是什么意思
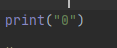
虽然已经有如下图

但是我还是print
下面异常:
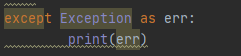
很简单的方法,执行过程中出现任何异常都会抛出来。
但都是英文相当于没做
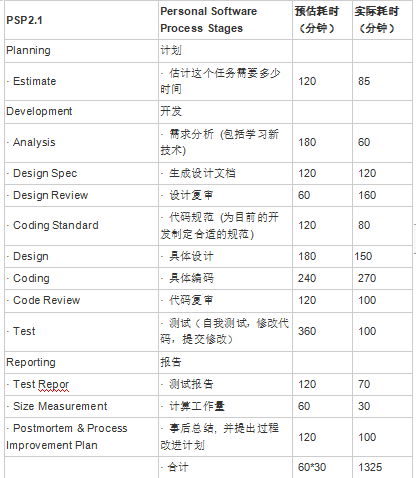
psp表
补充一下最后发现要求的输出文件自定义然后改为:

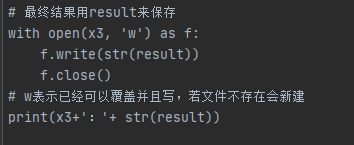
收获:
- 一开始觉得自己不可能独立的完成作业,或者比价早地完成作业(比预期要早)
- 第一次将自己的想法可以表述出来,当然其实我也是知道自己的代码还存在问题:
在划分的时候我是每一个字计算,在已知抄袭的情况下肯定正确,但是很多时候我们可以几个词连在一起来判断,这样会避免误判(也查了资料,但是好像需要jieba库等等)
- 这次项目的难点我觉得每一步都是难点!,什么github的仓库建立还有release,
- 希望下次可以做到将函数封装起来。
附上代码
import os
import copy
import numpy as np
import sys
from scipy.spatial.distance import pdist
x1 = sys.argv[0]
x2 = sys.argv[1]
x3 = sys.argv[2]
try:
fr = open(x1, 'r', encoding="utf-8")
fd = open(x2, 'r', encoding="utf-8")
# 从命令行读取绝对路径,打开文件fr和fd,文件内容为中文,采用gbk
# 中间为查重算法
# 预处理
content2 = fd.readlines()
contentLines2 = ''
characers = [] # 列表
stat = {} # 字典
content1 = fr.readlines()
contentLines1 = ''
characers1 = [] # 列表
stat1 = {} # 字典,items是键值对,keys是键,values是值
tochar = [] # 列表
for line in content1:
line = line.strip()
if len(line) == 0:
continue
contentLines1 = contentLines1 + line
for x in range(0, len(line)):
if not line[x] in tochar:
tochar.append(line[x]) ##所有的汉字种类
stat1[line[x]] = 0
stat[line[x]] = 0
for line in content2:
line = line.strip()
if len(line) == 0:
continue
contentLines2 = contentLines2 + line
for x in range(0, len(line)):
if not line[x] in tochar:
tochar.append(line[x])
stat1[line[x]] = 0
stat[line[x]] = 0
for line in content1:
line = line.strip() # 去空格
if len(line) == 0:
continue
contentLines1 = contentLines1 + line
for x in range(0, len(line)):
if not line[x] in characers1:
characers1.append(line[x])
if line[x] not in stat1:
stat1[line[x]] = 1
stat1[line[x]] += 1
##同理抄袭文件
for line in content2:
line = line.strip() # 去空格
if len(line) == 0:
continue
contentLines2 = contentLines2 + line
for x in range(0, len(line)):
if not line[x] in characers:
characers.append(line[x])
if line[x] not in stat:
stat[line[x]] = 1
stat[line[x]] = stat[line[x]] + 1
# 第二步按照排序(不知道后面的特征值是否需要)
##同理先原文件
# e[0]是按键划分,e[1]是按值划分
stat1 = sorted(stat1.items(), key=lambda e: e[0], reverse=True)
##之后的抄袭文件
stat = sorted(stat.items(), key=lambda e: e[0], reverse=True)
lis = []
# bug 修改 dic到list
for i in stat:
lis.append(i[1])
vec1 = np.array(lis)
vec1 = vec1.reshape(-1)
lis1 = []
for i in stat1:
lis1.append(i[1])
vec2 = np.array(lis1)
vec2 = vec2.reshape(-1)
""""
核心部分
fz = float(np.dot(vec1, vec2))
fz = round(fz, 6)
fm = float(np.linalg.norm(vec1) * np.linalg.norm(vec2))
fm = round(fm, 6)
result = float(fz / fm)
result = result * 7 - 6
result = round(result, 2)
"""
vec3 = np.vstack([vec1, vec2])
dist1 = pdist(vec3, 'jaccard')
fr.close()
fd.close()
with open(x3, 'w') as f:
f.write(str(dist1))
f.close()
except Exception as err:
print(err)
print("0")