两种链接方式
用DBAPI构建数据库链接
import pymysql import pandas as pd con = pymysql.connect(host="127.0.0.1",user="root",password="password",db="world") # 读取sql data_sql=pd.read_sql("SQL查询语句",con) # 存储 data_sql.to_csv("test.csv")
用sqlalchemy构建数据库链接
import pandas as pd import sqlalchemy from sqlalchemy import create_engine # 用sqlalchemy构建数据库链接engine db_info = {'user':'user', 'password':'pwd', 'host':'localhost', 'database':'xx_db' # 这里我们事先指定了数据库,后续操作只需要表即可 } engine = create_engine('mysql+pymysql://%(user)s:%(password)s@%(host)s/%(database)s?charset=utf8' % db_info,encoding='utf-8') #这里直接使用pymysql连接,echo=True,会显示在加载数据库所执行的SQL语句。 # sql 命令 sql_cmd = "SELECT * FROM table" df = pd.read_sql(sql=sql_cmd, con=engine)
从Mysql读取数据,返回DataFrame格式的数据
read_sql
pandas.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
效果:将SQL查询或数据库表读入DataFrame。
官方关于参数的详细介绍:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_sql.html
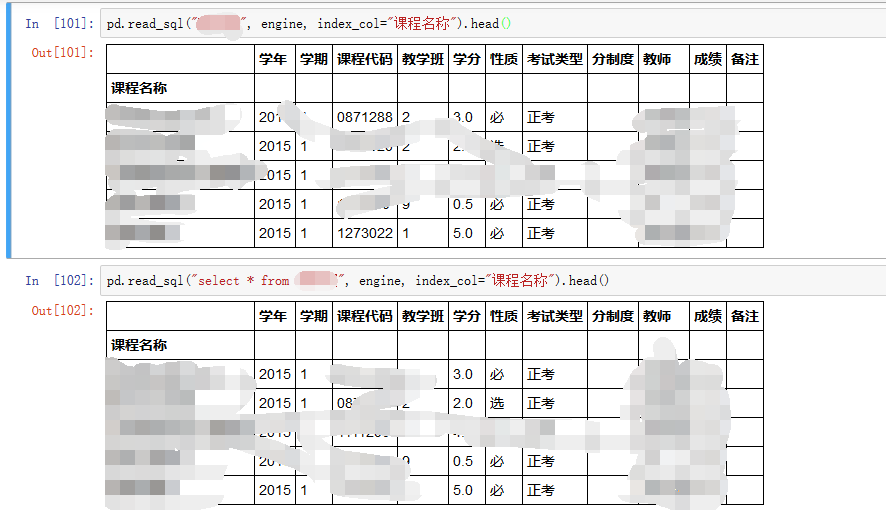
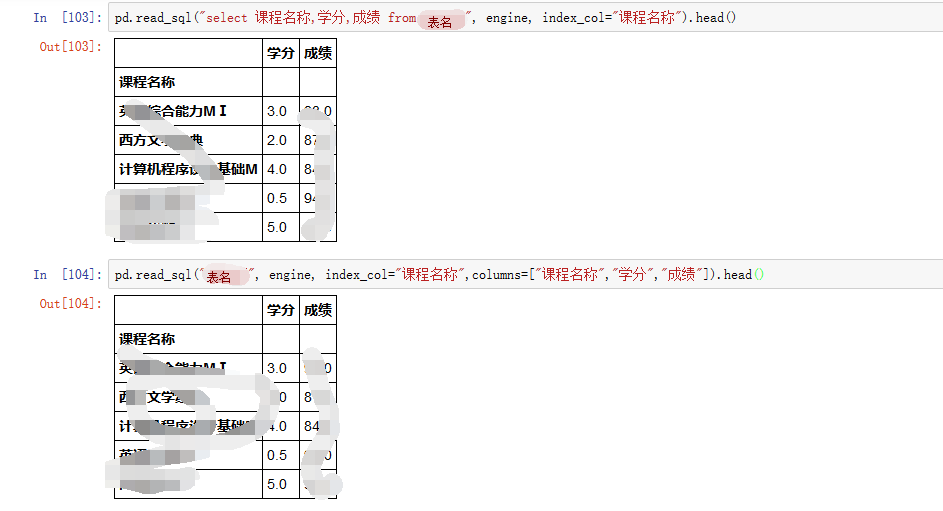
如何使用read_sql
来源:https://www.cnblogs.com/cymwill/p/8289367.html
下面两个的作用又是相同的:
将DataFrame格式的数据存储到Mysql
to_sql
DataFrame.to_sql(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None,method=None)
官方关于参数的详细介绍:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_sql.html
如何使用to_sql下部分来源:https://www.jianshu.com/p/d615699ff254
我们从一个简单的例子开始。在 mysql 数据库中有一个 emp_data 表,假设我们使用 pandas DataFrame ,将数据拷贝到另外一个新表 emp_backup。
import pandas as pd from sqlalchemy import create_engine import sqlalchemy engine = create_engine('mysql+pymysql://user:password@localhost/stonetest?charset=utf8') df = pd.read_sql('emp_master', engine) df.to_sql('emp_backup', engine)
使用 mysql 的 describe 命令比较 emp_master 表和 emp_backup 表结构:
mysql> describe emp_master;
+----------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------------+-------------+------+-----+---------+-------+
| EMP_ID | int(11) | NO | PRI | NULL | |
| GENDER | varchar(10) | YES | | NULL | |
| AGE | int(11) | YES | | NULL | |
| EMAIL | varchar(50) | YES | | NULL | |
| PHONE_NR | varchar(20) | YES | | NULL | |
| EDUCATION | varchar(20) | YES | | NULL | |
| MARITAL_STAT | varchar(20) | YES | | NULL | |
| NR_OF_CHILDREN | int(11) | YES | | NULL | |
+----------------+-------------+------+-----+---------+-------+
8 rows in set (0.00 sec)
emp_backup 表结构:
mysql> describe emp_backup;
+----------------+------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------------+------------+------+-----+---------+-------+
| index | bigint(20) | YES | MUL | NULL | |
| EMP_ID | bigint(20) | YES | | NULL | |
| GENDER | text | YES | | NULL | |
| AGE | bigint(20) | YES | | NULL | |
| EMAIL | text | YES | | NULL | |
| PHONE_NR | text | YES | | NULL | |
| EDUCATION | text | YES | | NULL | |
| MARITAL_STAT | text | YES | | NULL | |
| NR_OF_CHILDREN | bigint(20) | YES | | NULL | |
+----------------+------------+------+-----+---------+-------+
9 rows in set (0.00 sec)
我们发现,to_sql() 并没有考虑将 emp_master 表字段的数据类型同步到目标表,而是简单的区分数字型和字符型,这是第一个问题,第二个问题呢,目标表没有 primary key。因为 pandas 定位是数据分析工具,数据源可以来自 CSV 这种文本型文件,本身是没有严格数据类型的。而且,pandas 数据 to_excel() 或者to_sql() 只是方便数据存放到不同的目的地,本身也不是一个数据库升迁工具。
但如果我们需要严谨地保留原表字段的数据类型,以及保留 primary key,该怎么做呢?
使用 SQL 语句来创建表结构
如果数据源本身是来自数据库,通过脚本操作是比较方便的。如果数据源是来自 CSV 之类的文本文件,可以手写 SQL 语句或者利用 pandas get_schema() 方法,如下例:
import sqlalchemy print(pd.io.sql.get_schema(df, 'emp_backup', keys='EMP_ID', dtype={'EMP_ID': sqlalchemy.types.BigInteger(), 'GENDER': sqlalchemy.types.String(length=20), 'AGE': sqlalchemy.types.BigInteger(), 'EMAIL': sqlalchemy.types.String(length=50), 'PHONE_NR': sqlalchemy.types.String(length=50), 'EDUCATION': sqlalchemy.types.String(length=50), 'MARITAL_STAT': sqlalchemy.types.String(length=50), 'NR_OF_CHILDREN': sqlalchemy.types.BigInteger() }, con=engine))
get_schema()并不是一个公开的方法,没有文档可以查看。生成的 SQL 语句如下:
CREATE TABLE emp_backup ( `EMP_ID` BIGINT NOT NULL AUTO_INCREMENT, `GENDER` VARCHAR(20), `AGE` BIGINT, `EMAIL` VARCHAR(50), `PHONE_NR` VARCHAR(50), `EDUCATION` VARCHAR(50), `MARITAL_STAT` VARCHAR(50), `NR_OF_CHILDREN` BIGINT, CONSTRAINT emp_pk PRIMARY KEY (`EMP_ID`) )
to_sql() 方法使用 append 方式插入数据
to_sql() 方法的 if_exists 参数用于当目标表已经存在时的处理方式,默认是 fail,即目标表存在就失败,另外两个选项是 replace 表示替代原表,即删除再创建,append 选项仅添加数据。使用 append 可以达到要求。
import pandas as pd from sqlalchemy import create_engine import sqlalchemy engine = create_engine('mysql+pymysql://user:password@localhost/stonetest?charset=utf8') df = pd.read_sql('emp_master', engine) # make sure emp_master_backup table has been created # so the table schema is what we want df.to_sql('emp_backup', engine, index=False, if_exists='append')
也可以在 to_sql() 方法中,通过 dtype 参数指定字段的类型,然后在 mysql 中 通过 alter table 命令将字段 EMP_ID 变成 primary key。
df.to_sql('emp_backup', engine, if_exists='replace', index=False, dtype={'EMP_ID': sqlalchemy.types.BigInteger(), 'GENDER': sqlalchemy.types.String(length=20), 'AGE': sqlalchemy.types.BigInteger(), 'EMAIL': sqlalchemy.types.String(length=50), 'PHONE_NR': sqlalchemy.types.String(length=50), 'EDUCATION': sqlalchemy.types.String(length=50), 'MARITAL_STAT': sqlalchemy.types.String(length=50), 'NR_OF_CHILDREN': sqlalchemy.types.BigInteger() }) with engine.connect() as con: con.execute('ALTER TABLE emp_backup ADD PRIMARY KEY (`EMP_ID`);')
当然,如果数据源本身就是 mysql,当然不用大费周章来创建数据表的结构,直接使用 create table like xxx 就行。以下代码展示了这种用法:
import pandas as pd from sqlalchemy import create_engine engine = create_engine('mysql+pymysql://user:password@localhost/stonetest?charset=utf8') df = pd.read_sql('emp_master', engine) # Copy table structure with engine.connect() as con: con.execute('DROP TABLE if exists emp_backup') con.execute('CREATE TABLE emp_backup LIKE emp_master;') df.to_sql('emp_backup', engine, index=False, if_exists='append')