python垃圾回收机制
一、什么是垃圾回收机制?
垃圾回收机制(简称GC)是Python解释器自带一种机制,专门用来回收不可用的变量值所占用的内存空间
二、为什么要用垃圾回收机制?
程序运行过程中会申请大量的内存空间,而对于一些无用的内存空间如果不及时清理的话会导致内存使用殆尽(内存溢出),导致程序崩溃,因此管理内存是一件重要且繁杂的事情,而python解释器自带的垃圾回收机制把程序员从繁杂的内存管理中解放出来。
python采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅的策略
- Python的GC模块主要运用了引用计数来跟踪和回收垃圾。
- 在引用计数的基础上,还可以通过“标记-清除”解决容器对象可能产生的循环引用的问题。
- 通过分代回收以空间换取时间进一步提高垃圾回收的效率。
引用计数机制 引用计数的缺陷是循环引用的问题 为每个内存对象维护一个引用计数. 当有新的引用指向某对象时就该该对象的引用计数加1,当指向该对象的引用被销毁时将该对象计数减1,当计数归零时,就回收该对象所占用的内存资源 标记-清除 分两个步骤 1、标记:即从众多的内存对象中区分出不在会被使用的垃圾对象; 2、清除:把标记的垃圾对象清除.标记的时候需要确定内存对象的集合Root set,集合里的对象都是可以访问的.如果root set中的对象引用了其他的对象,那么被引用的对象也不能被标记为垃圾对象.然后从root set出发,递归遍历root set能访问到的所有对象,进行标记为不是垃圾对象.遍历结束后,没有被标记的就是垃圾对象 分代收集 根据一个统计学上的结论,如果一个内存对象在某次Mark过程中发现不是垃圾,那么它短期内成为垃圾的可能性就很小。
分代收集将那些在多次垃圾收集过程中都没有被标记为垃圾对象的内存对象集中到另外一个区域——年老的区域,即这个区域中的内存对象年龄比较大。
因为年老区域内内存对象短期内变成垃圾的概率很低,所以这些区域的垃圾收集频率可以降低,相对的,对年轻区域内的对象进行高频率的垃圾收集。这样可以提高垃圾收集的整体性能。
引用计数机制
在CPython中,大多数对象的生命周期都是通过对象的引用计数来管理的。引用计数是一种最直观、最简单的垃圾收集计数,与其他主流GC算法比较,它的最大优点是实时性,即任何内存,一旦没有指向它的引用,就会立即被回收。
import sys class test(): def __init__(self): '''初始化对象''' print('对象引用次数: ', sys.getrefcount(self)) # getrefcount()方法用于返回对象的引用计数 def func(c): print('对象引用次数: ',sys.getrefcount(c)) #getrefcount()方法用于返回对象的引用计数 if __name__ == '__main__': #生成对象 a=test() func(a) #增加引用 b=a func(a) #销毁引用对象b del b func(a)
输出结果:
对象引用次数: 3 对象引用次数: 4 对象引用次数: 5 对象引用次数: 4
导致引用计数+1的情况
- 对象被创建:例如a=1
- 对象被引用:例如 b=a
- 对象被作为参数,传入到一个函数中,例如func(a)
- 对象作为一个元素,存储在容器中,例如list1=[a,a]
导致引用计数-1的情况
- 对象的别名被显式销毁,例如del a
- 对象的别名被赋予新的对象,例如a=24
- 一个对象离开它的作用域,例如f函数执行完毕时,func函数中的局部变量(全局变量不会)
- 对象所在的容器被销毁,或从容器中删除对象
引用计数机制的问题
1.在每次内存对象呗引用或者引用被销毁时都需要修改引用计数,这类操作被称为footprint。引用计数的footprint是很高的,使得程序的整体性能受到很大的影响。
2.引用计数机制还存在着一个致命的弱点,即 循环引用 (也称交叉引用)。
# 变量名l1指向列表1,变量名l2指向列表2 l1=['列表1中的第一个元素'] # 列表1被引用一次 l2=['列表2中的第一个元素'] # 列表2被引用一次 l1.append(l2) #把列表2追加到l1中作为第二个元素,列表2的引用计数为2 l2.append(l1) # 把列表1追加到l2中作为第二个元素,列表1的引用计数为2 # l1与l2 print(l1) print(l2) # 如果我们执行del l1,列表1的引用计数=2-1,即列表1不会被回收,同理del l2,列表2的引用计数=2-1,此时无论列表1还是列表2都没有任何名字关联,但是引用计数均不为0,所以循环引用是致命的,这与手动进行内存管理所产生的内存泄露毫无区别 要解决这个问题,Python引入了其他的垃圾收集机制来弥补引用计数的缺陷: 1、“标记-清除” 2、“分代回收”
标记-清除&分代回收
Python引入了其他的垃圾收集机制来弥补引用计数的缺陷
标记-清除
容器对象(比如:list,set,dict,class,instance)都可以包含对其他对象的引用,所以都可能产生循环引用。而“标记-清除”计数就是为了解决循环引用的问题。
在了解标记清除算法前,我们需要明确一点, 内存中有两块区域:堆区与栈区,在定义变量时,变量名存放于栈区,变量值存放于堆区,内存管理回收的则是堆区的内容 ,详解如下图
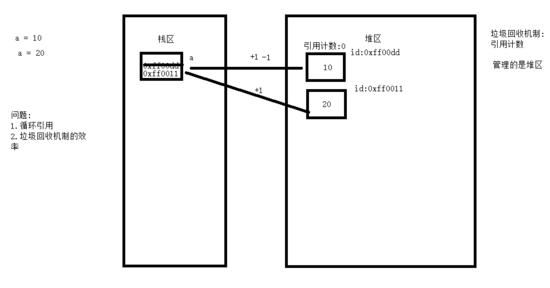
标记/清除算法的做法 是当有效内存空间被耗尽的时候,就会停止整个程序,然后进行两项工作,第一项则是标记,第二项则是清除
标记:标记的过程其实就是,遍历所有的GC Roots对象(栈区中的所有内容或者线程都可以作为GC Roots对象),然后将所有GC Roots的对象可以直接或间接访问到的对象标记为存活的对象。
清除:清除的过程将遍历堆中所有的对象,将没有标记的对象全部清除掉。
GC roots对象直接访问到的对象,插图如下
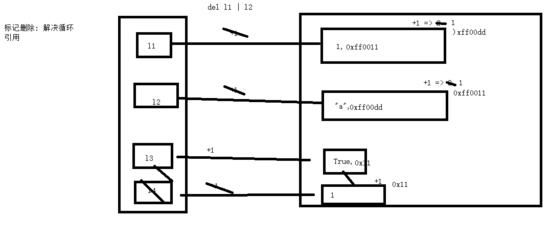
用图形解释,环引用的例子中的l1与l2,在什么时候启动标记清除,标记清除的整个过程
分代回收
分代:
分代回收的核心思想是: 在多次扫描的情况下,都没有被回收的变量,gc机制就会认为,该变量是常用变量,gc对其扫描的频率会降低 ,具体实现原理如下:
分代指的是根据存活时间来为变量划分不同等级(也就是不同的代)
新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次,如果发现变量依然被引用,那么该对象的权重(权重本质就是个整数)加一,当变量的权重大于某个设定得值(假设为3),会将它移动到更高一级的青春代,青春代的gc扫描的频率低于新生代(扫描时间间隔更长),假设5分钟扫描青春代一次,这样每次gc需要扫描的变量的总个数就变少了,节省了扫描的总时间,接下来,青春代中的对象,也会以同样的方式被移动到老年代中。也就是等级(代)越高,被垃圾回收机制扫描的频率越低
回收:
回收依然是使用引用计数作为回收的依据
图示:
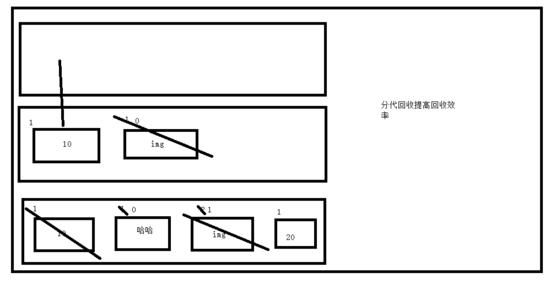
缺点:
例如一个变量刚刚从新生代移入青春代,该变量的绑定关系就解除了,该变量应该被回收,青春代的扫描频率低于新生代,所以该变量的回收时间被延迟。
参考:http://sh.qihoo.com/pc/9d4c172691445d42d?cota=3&sign=360_e39369d1&refer_scene=so_1