参考文献:极客时间傅健老师的《Netty源码剖析与实战》Talk is cheap.show me the code!
什么是粘包和半包
在客户端发送数据时,实际是把数据写入到了TCP发送缓存里面的。
半包:顾名思义就是接收到半个包,如果发送的包的大小比TCP发送缓存的容量大,那么这个数据包就会被分成多个包,通过socket多次发送到服务端,服务端第一次从接受缓存里面获取的数据,实际是整个包的一部分,半包不是说只收到了全包的一半,是说收到了全包的一部分。
粘包:如果发送的包的大小比TCP发送缓存容量小,并且TCP缓存可以存放多个包,那么客户端和服务端的一次通信就可能传递了多个包,这时候服务端从接受缓存就可能一下读取了多个包
举个栗子:
我们现在发送两条消息:“ABC”,“DEF”,那么对方接收到的消息不一定是这种格式的,对方可能一次性就接收到“ABCDEF”,也可能分好几次接收到“AB”,“CD”,“EF”,或者更为恶劣一次接收到了两个消息“A”,“BCDEF”。那么这样一次接收两个消息的称为粘包现象,分三次四接收到多个不完整的现象是半包现象。
粘包的主要原因:
发送方每次写入数据 < 套接字缓冲区大小,接收方读取套接字缓冲区数据不够及时。
半包的主要原因:
发送方写入数据 > 套接字缓冲区大小,还有就是发送的数据大于协议的MTU(Maximum Transmission Unit 最大传输单元)的时候必须拆包。(MTU其实就是TCP协议每层的大小)
换个角度:
收发:一个发送可能被多次接收,多次发送可能被一次接收
传输:一个发送可能占用多个传输包,多个发送可能公用一个传输包
根本原因:
TCP是流动协议,消息无边界。(UDP像邮寄的包裹,虽然一次运输多个的,但每个包裹都有“界限”,一个一个签收,所以无粘包、半包问题)
解决问题的根本手段:找出消息的边界
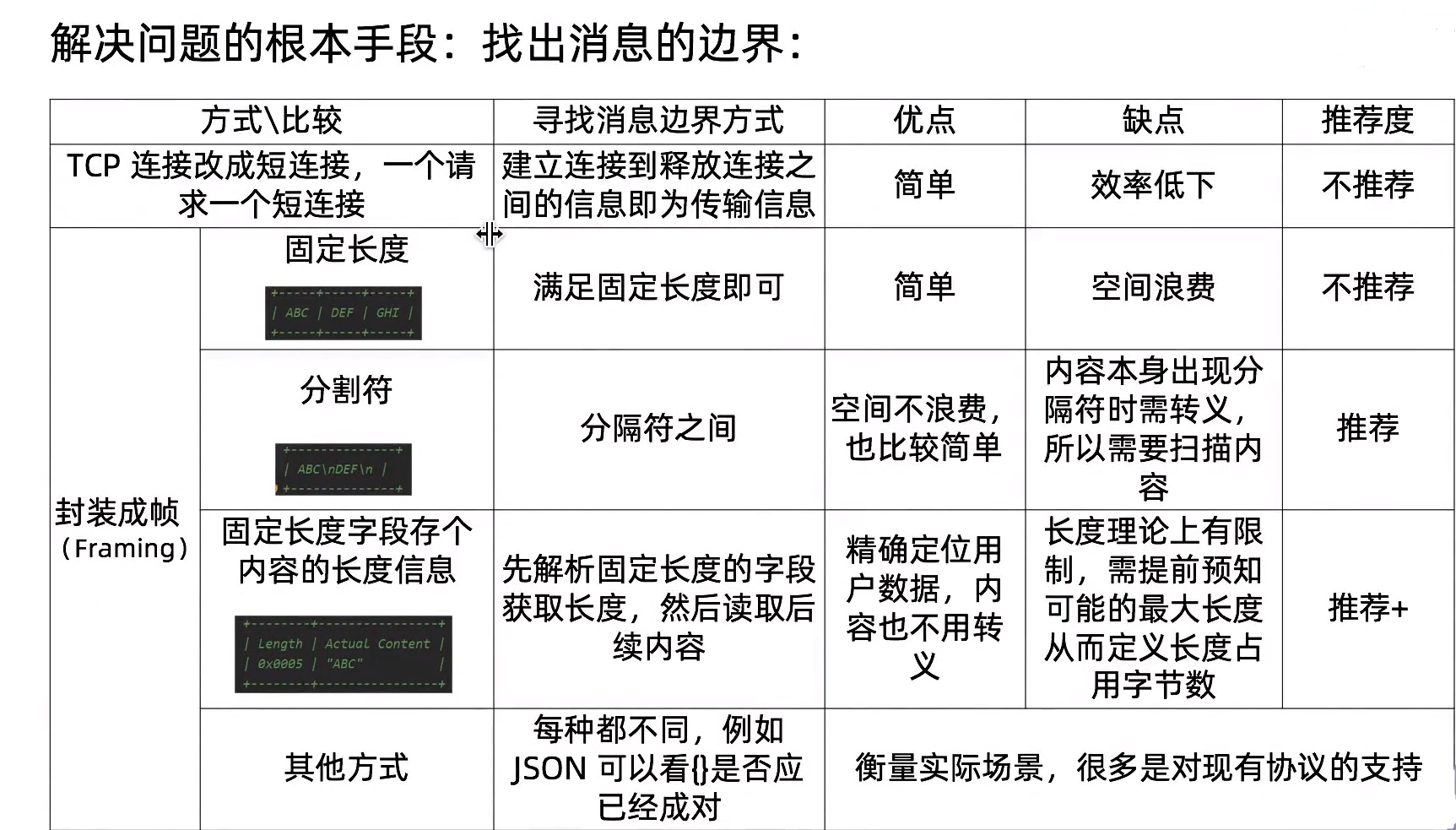
Netty对三种常用封帧方式的支持(三个类都继承ByteTomessageDecoder.java)

解读Netty处理粘包、半包的源码-------解码核心工作流程:
先找到ByteToMessageDecoder.java,可以看到它继承了ChannelInboundHandlerAdapter.java

这个ChannelInboundHandlerAdapter有个核心的入口方法“channelRead()”;
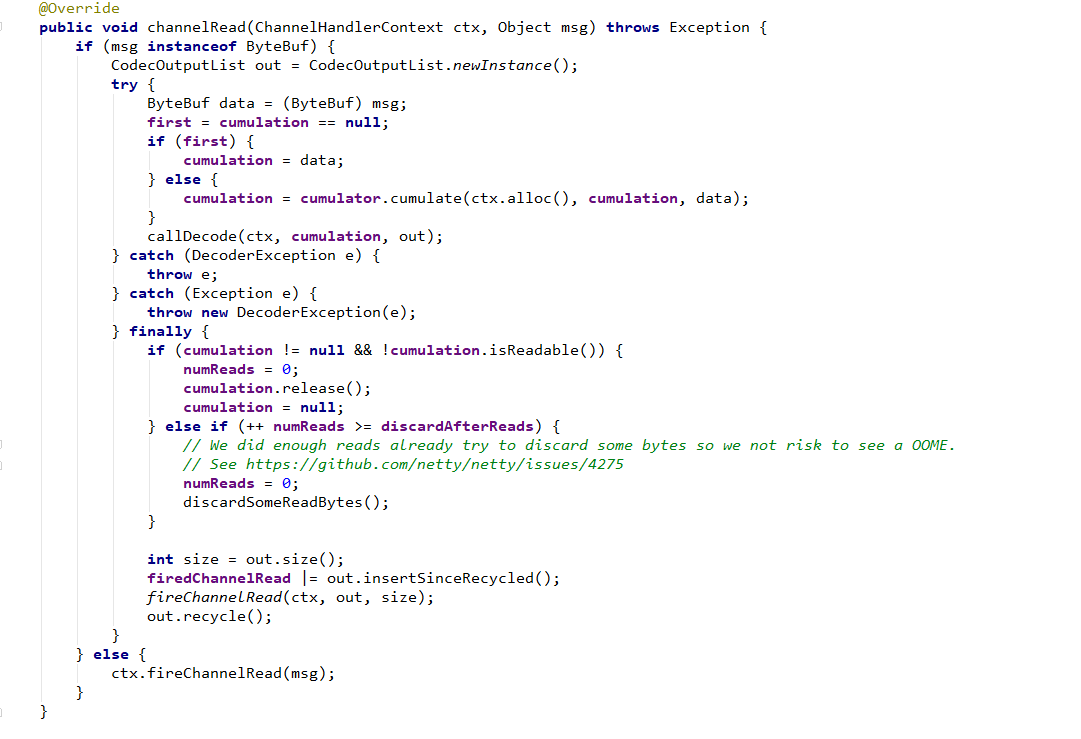
图中的msg就相当于我们的数据,开始就把数据转换成data,
ByteBuf data = (ByteBuf) msg;
然后判断cumulation是否为null,cumulation是数据积累器,用来积累数据。
ByteBuf cumulation;
first = cumulation == null; if (first) { cumulation = data; } else { cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data); }
第一次的时候肯定为null 所以first是true,直接把data数据给了cumulation。再接下来就是解码:
callDecode(ctx, cumulation, out);
进入具体方法

参数中的in就是数据积累器中的数据,也就是我们传入的数据。往下走又这么个方法调用:
decodeRemovalReentryProtection(ctx, in, out);
需要注意的是:decode中时,不能执行完handler remove清理操作,decode完之后需要清理数据,改方法的名称长久是标识功能的。点进去可以查看

可以看出有个decodeState = STATE_CALLING_CHILD_DECODE;这个就是处理刚才remove handler 的;接下来就是“decode(ctx, in, out);”;这个decode是个抽象方法

之前说过Netty对三种封帧的支持分别是:“FixedLengthFrameDecoder”,“DelimiterBasedFrameDecoder”,“LengthFieldBasedFrameDecoder”。这里以“FixedLengthFrameDecoder”为例,所以点开FixedLengthFrameDecoder的decode();
@Override protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception { Object decoded = decode(ctx, in); if (decoded != null) { out.add(decoded); } }
然后再进去查看Object decoded = decode(ctx, in);
protected Object decode( @SuppressWarnings("UnusedParameters") ChannelHandlerContext ctx, ByteBuf in) throws Exception { if (in.readableBytes() < frameLength) { return null; } else { return in.readRetainedSlice(frameLength); } }
这时候就能发现关键点,代码标粗,这个in还是数据积累器的数据,取得之后进行判断,如果小于则返回null不能解出,否则解出。这样一来就完成了一个数据解析的过程。