前言:
信息熵是一种用于衡量系统内部信息量的度量。在信息论中,信息是系统有序程度的一种度量。
信息是确定性的增加,不确定性的减少(香农定理)。而信息熵是系统无序程度的一种度量,是系统不确定性的量度。两者绝对值相等,但符号相反。一个系统的信息熵越小,该系统所含的信息量越大。
信息熵被广泛用于计算机编码,通信理论,博弈论等与“信息量”和“不确定性”相关的理论模型中。
熵权法就是一个通过信息熵理论确定系统中各指标权值的赋值方法,能够较为精确客观地判断系统中各指标对总评价的贡献大小。
信息熵的概念
• 单调性,即发生概率越高的事件,其所携带的信息熵越低。极端案例就是“太阳从东方升起”,因为为确定事件,所以不携带任何信息量。从信息论的角度,认为这句话没有消除任何不确定性。
• 非负性,即信息熵不能为负。这个很好理解,因为负的信息,即你得知了某个信息后,却增加了不确定性是不合逻辑
• 累加性,即多随机事件同时发生存在的总不确定性的量度是可以表示为各事件不确定性的量度的和。

熵权法介绍
熵最先由香农引入信息论,目前已经在工程技术、社会经济等领域得到了非常广泛的应用。
熵权法的基本思路是根据指标变异性的大小来确定客观权重。
熵权法相对于其他打分评价模型来说,具有精确客观的优点。基于信息熵所计算得出的权重能够较为精确地反应不同指标间的差别。但是相对应的,由于该模型的本质是用有限个决策样本去“估计”指标的信息熵,在样本量过少的情况下,基于熵权法所计算得出的权重则有可能出现较大误差。一般来讲,样本决策数必须大于等于指标数。
一般来说,若某个指标的信息熵![]() 越小,表明指标值得变异程度越大,提供的信息量越多,在综合评价中所能起到的作用也越大,其权重也就越大。相反,某个指标的信息熵
越小,表明指标值得变异程度越大,提供的信息量越多,在综合评价中所能起到的作用也越大,其权重也就越大。相反,某个指标的信息熵![]() 越大,表明指标值得变异程度越小,提供的信息量也越少,在综合评价中所起到的作用也越小,其权重也就越小。
越大,表明指标值得变异程度越小,提供的信息量也越少,在综合评价中所起到的作用也越小,其权重也就越小。
熵权法赋权步骤
数据标准化
将各个指标的数据进行标准化处理。
假设给定了k个指标![]() ,其中
,其中![]() 。假设对各指标数据标准化后的值为
。假设对各指标数据标准化后的值为![]() ,那么
,那么![]() 。
。
求各指标的信息熵
根据信息论中信息熵的定义,一组数据的信息熵 ![]() ,
,
(近似写为:![]() ,n取e为底数) ,其中
,n取e为底数) ,其中 ![]() 。
。
,如果 ![]() 则定义
则定义 ![]() 再带入。
再带入。
确定各指标权重
根据信息熵的计算公式,计算出各个指标的信息熵为![]() 。通过信息熵计算各指标的权重:
。通过信息熵计算各指标的权重:![]() 。
。
熵权法赋权实例
背景介绍
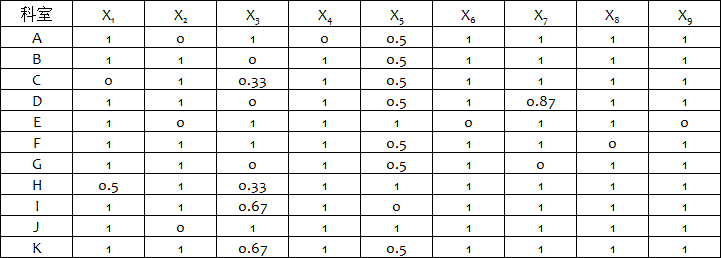
某医院为了提高自身的护理水平,对拥有的11个科室进行了考核,考核标准包括9项整体护理,并对护理水平较好的科室进行奖励。下表是对各个科室指标考核后的评分结果。
表1 11个科室9项整体护理评价指标得分表

但是由于各项护理的难易程度不同,因此需要对9项护理进行赋权,以便能够更加合理的对各个科室的护理水平进行评价。
熵权法进行赋权
1.数据标准化
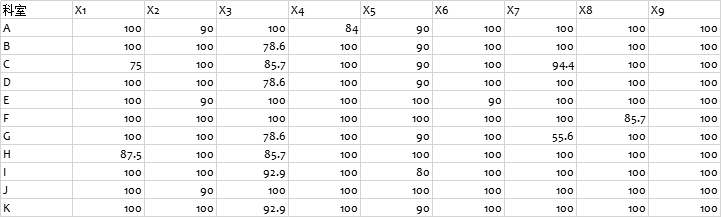
根据原始评分表,对数据进行标准化后可以得到下列数据标准化表
表2 11个科室9项整体护理评价指标得分表标准化表
2.求各指标的信息熵
根据信息熵的计算公式![]() ,可以计算出9项护理指标各自的信息熵如下:
,可以计算出9项护理指标各自的信息熵如下:
表3 9项指标信息熵表

3.计算各指标的权重
根据指标权重的计算公式![]() ,可以得到各个指标的权重如下表所示:
,可以得到各个指标的权重如下表所示:
表4 9项指标权重表

4.对各个科室进行评分
根据计算出的指标权重,以及对11个科室9项护理水平的评分。设Zl为第l个科室的最终得分,则 ![]() ,各个科室最终得分如下表所示:
,各个科室最终得分如下表所示:
表5 11个科室最终得分表

实现过程
数据源:
python3代码:
1 # -*- encoding=utf-8 -*-
2
3 import warnings
4 warnings.filterwarnings("ignore")
5 import pandas as pd
6 import numpy as np
7
8
9 def get_score(wi_list,data):
10 """
11 :param wi_list: 权重系数列表
12 :param data:评价指标数据框
13 :return:返回得分
14 """
15
16 # 将权重转换为矩阵
17
18 cof_var = np.mat(wi_list)
19
20 # 将数据框转换为矩阵
21 context_train_data = np.mat(data)
22
23 # 权重跟自变量相乘
24 last_hot_matrix = context_train_data * cof_var.T
25 last_hot_matrix = pd.DataFrame(last_hot_matrix)
26
27 # 累加求和得到总分
28 last_hot_score = list(last_hot_matrix.apply(sum))
29
30 # max-min 归一化
31
32 # last_hot_score_autoNorm = autoNorm(last_hot_score)
33
34 # 值映射成分数(0-100分)
35
36 # last_hot_score_result = [i * 100 for i in last_hot_score_autoNorm]
37
38 return last_hot_score
39
40
41
42 def get_entropy_weight(data):
43 """
44 :param data: 评价指标数据框
45 :return: 各指标权重列表
46 """
47 # 数据标准化
48 data = (data - data.min())/(data.max() - data.min())
49 m,n=data.shape
50 #将dataframe格式转化为matrix格式
51 data=data.as_matrix(columns=None)
52 k=1/np.log(m)
53 yij=data.sum(axis=0)
54 #第二步,计算pij
55 pij=data/yij
56 test=pij*np.log(pij)
57 test=np.nan_to_num(test)
58
59 #计算每种指标的信息熵
60 ej=-k*(test.sum(axis=0))
61 #计算每种指标的权重
62 wi=(1-ej)/np.sum(1-ej)
63
64 wi_list=list(wi)
65
66
67 return wi_list
68
69
70
71 if __name__ == '__main__':
72
73
74 data0 = pd.read_excel("C:\Users\Oreo\Desktop\test2.xlsx", encoding='utf8')
75
76 data = data0.iloc[:, 1:10]
77 mm=data
78 wi_list=get_entropy_weight(data)
79 score_list=get_score(mm,wi_list)
80 mm['score']=score_list
81 mm['科室']=data0['科室']
82 # 然后对数据框按得分从大到小排序
83 result = mm.sort_values(by='score', axis=0, ascending=False)
84 result['rank'] = range(1, len(result) + 1)
85
86 print(result)
87
88 # 写出csv数据
89 result.to_csv('C:\Users\Oreo\Desktop\test2_result.csv', index=False)
数据结果:

GitHub地址
参考链接