使用HWPFDocument对象读取03版doc文件或wps文件
导包

代码:
1、图片工具类
1 package com.poi.test; 2 3 import java.util.ArrayList; 4 import java.util.HashMap; 5 import java.util.HashSet; 6 import java.util.List; 7 import java.util.Map; 8 import java.util.Set; 9 10 import org.apache.poi.hwpf.HWPFDocument; 11 import org.apache.poi.hwpf.model.PicturesTable; 12 import org.apache.poi.hwpf.usermodel.CharacterRun; 13 import org.apache.poi.hwpf.usermodel.Picture; 14 import org.apache.poi.hwpf.usermodel.Range; 15 16 /** 17 * Provides access to the pictures both by offset, iteration over the 18 * un-claimed, and peeking forward 19 */ 20 public class PicturesSource {//这个类是poi官网找的 21 private PicturesTable picturesTable; 22 private Set<Picture> output = new HashSet<Picture>(); 23 private Map<Integer, Picture> lookup; 24 private List<Picture> nonU1based; 25 private List<Picture> all; 26 private int pn = 0; 27 28 public PicturesSource(HWPFDocument doc) { 29 picturesTable = doc.getPicturesTable(); 30 all = picturesTable.getAllPictures(); 31 32 // Build the Offset-Picture lookup map 33 lookup = new HashMap<Integer, Picture>(); 34 for (Picture p : all) { 35 lookup.put(p.getStartOffset(), p); 36 } 37 38 // Work out which Pictures aren't referenced by 39 // a u0001 in the main text 40 // These are u0008 escher floating ones, ones 41 // found outside the normal text, and who 42 // knows what else... 43 nonU1based = new ArrayList<Picture>(); 44 nonU1based.addAll(all); 45 Range r = doc.getRange(); 46 for (int i = 0; i < r.numCharacterRuns(); i++) { 47 CharacterRun cr = r.getCharacterRun(i); 48 if (picturesTable.hasPicture(cr)) { 49 Picture p = getFor(cr); 50 int at = nonU1based.indexOf(p); 51 nonU1based.set(at, null); 52 } 53 } 54 } 55 56 private boolean hasPicture(CharacterRun cr) { 57 return picturesTable.hasPicture(cr); 58 } 59 60 private void recordOutput(Picture picture) { 61 output.add(picture); 62 } 63 64 private boolean hasOutput(Picture picture) { 65 return output.contains(picture); 66 } 67 68 private int pictureNumber(Picture picture) { 69 return all.indexOf(picture) + 1; 70 } 71 72 public Picture getFor(CharacterRun cr) { 73 return lookup.get(cr.getPicOffset()); 74 } 75 76 /** 77 * Return the next unclaimed one, used towards the end 78 */ 79 private Picture nextUnclaimed() { 80 Picture p = null; 81 while (pn < nonU1based.size()) { 82 p = nonU1based.get(pn); 83 pn++; 84 if (p != null) 85 return p; 86 } 87 return null; 88 } 89 }
2、处理图片和段落文字
1 package com.poi.test; 2 3 import java.io.ByteArrayOutputStream; 4 import java.io.File; 5 import java.io.FileInputStream; 6 7 import org.apache.poi.hwpf.HWPFDocument; 8 import org.apache.poi.hwpf.model.PicturesTable; 9 import org.apache.poi.hwpf.usermodel.CharacterRun; 10 import org.apache.poi.hwpf.usermodel.Paragraph; 11 import org.apache.poi.hwpf.usermodel.Picture; 12 import org.apache.poi.hwpf.usermodel.Range; 13 14 public class PoiForWord { 15 /** 16 * 使用HWPFDocument解析word文档 17 * wps按doc处理即可 18 */ 19 public void parseDocByHWPFDocument(){ 20 try(FileInputStream is = new FileInputStream(new File("c:\a.wps"));HWPFDocument document = new HWPFDocument(is);){ 21 ByteArrayOutputStream baos = new ByteArrayOutputStream();//字节流,用来存储图片 22 PicturesSource pictures = new PicturesSource(document); 23 PicturesTable pictureTable = document.getPicturesTable(); 24 25 Range r = document.getRange();//区间 26 for(int i=0;i<r.numParagraphs();i++){ 27 Paragraph p = r.getParagraph(i);//段落 28 int fontSize = p.getCharacterRun(0).getFontSize();//字号,字号和是否加粗可用来当做标题或者某一关键标识的判断
boolean isBold = p.getCharacterRun(0).isBold();//是否加粗 29 String paragraphText = p.text();//段落文本 30 31 //以下代码解析图片,这样获取的图片是在文档流中的,是和文本按顺序解析的,可以很好的解决图片定位问题 32 for(int j=0;j<p.numCharacterRuns();j++){ 33 CharacterRun cr = p.getCharacterRun(j);//字符 34 if(pictureTable.hasPicture(cr)){ 35 Picture picture = pictures.getFor(cr); 36 //如果是在页面显示图片,可转换为base64编码的图片 37 picture.writeImageContent(baos);//将图片写入字节流 38 // String base64Image = "<img src='data:image/png;base64,"+new BASE64Encoder().encode(baos.toByteArray())+"'/>"; 39 } 40 } 41 } 42 }catch(Exception e){ 43 e.printStackTrace(); 44 } 45 } 46 47 }
3、处理表格

1 /** 2 * 使用HWPFDocument解析word文档 3 * wps按doc处理即可 4 */ 5 @Test 6 public void parseDocTableByHWPFDocument(){ 7 try(FileInputStream is = new FileInputStream(new File("d:\b.doc"));HWPFDocument document = new HWPFDocument(is);){ 8 Range r = document.getRange();//区间 9 for(int i=0;i<r.numParagraphs();i++){ 10 Paragraph p = r.getParagraph(i);//段落 11 String text = p.text(); 12 13 if(text.indexOf("序号")!=-1){//解析表格需要从表格第一个单元格获取表格,另一种表格的方式是直接获取所有表格,但是无法判断表格在文档中的位置 14 Table table = r.getTable(p); 15 16 int numRows = table.numRows();//获取行数 17 18 for(int j=0;j<numRows;j++){ 19 TableRow row = table.getRow(j); 20 int numCells = row.numCells();//当前行列数 21 for(int k=0;k<numCells;k++){ 22 TableCell cell = row.getCell(k); 23 System.out.print(cell.text()+" @ "); 24 } 25 System.out.println(); 26 } 27 } 28 } 29 }catch(Exception e){ 30 e.printStackTrace(); 31 } 32 }
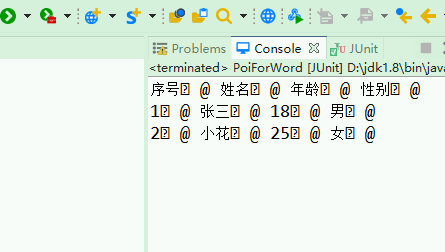
字符"?"可通过字符串替换或截取来解决
另一种解析的方式,只支持解析文本内容,且无法获取字号和加粗等字体格式
1 WordExtractor extor = new WordExtractor(is); 2 String[] paragraphText = extor.getParagraphText();