requests库
安装和文档地址:
利用pip安装:
pip install requests
中文文档:http://docs.python-requests.org/zh_CN/latest/index.html
github地址:http://github.com/requests/requests
发送GET请求:
1. 发送简单的get请求:
url = 'www.baidu.com' response = requests.get(url)
2. 添加headers和查询参数
传入headers参数增加请求头中的headers信息。如果想要将参数放在url中传递,可以利用params参数。相关实例代码:
import requests kw = { 'wd':'中国' } headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3642.0 Safari/537.36' } # params接收一个字典或者字符串的查询参数。字典类型自动转换为url编码,不需要urlencode() response = requests.get('https://baike.baidu.com/item/',params=kw,headers=headers) # 查看响应内容,response.text返回的是Unicode格式的数据 print(response.text) # 查看响应内容,response.content返回的字节流数据 print(response.content) # 查看完整的URL地址 print(response.url) #查看响应头部字符编码 print(response.encoding) # 查看响应码 print(response.status_code)
response.text与response.content的区别:
1. response.content:这个是直接在网络上面抓取的数据,没有经过任何解码。所以是一个byte类型。
硬盘与网络上传输的字符串都是byte类型。
2. response.text:这个是str的数据编码类型,是requests库将网页上的数据进行解码的字符串。解码需要指定一个
编码方式,requests会根据自己的猜测来判断编码的方式,但是有时候会判断错误,就会导致解码产生乱码,这时候
应该使用“response.concent.decode('utf-8')”进行手动解码。
import requests kw = { 'wd':'中国' } headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3642.0 Safari/537.36' } # params接收一个字典或者字符串的查询参数。字典类型自动转换为url编码,不需要urlencode() response = requests.get('https://baike.baidu.com/item/',params=kw,headers=headers) with open ('baidu.html','w',encoding='utf-8') as fp: fp.write(response.content.decode('utf-8'))
发送post请求:
1. 发送简单的post请求:
url = 'www.baidu.com' response = requests.post(furl)
2. 传入data数据:
直接传入一个字典,比如请求拉钩网的数据代码:
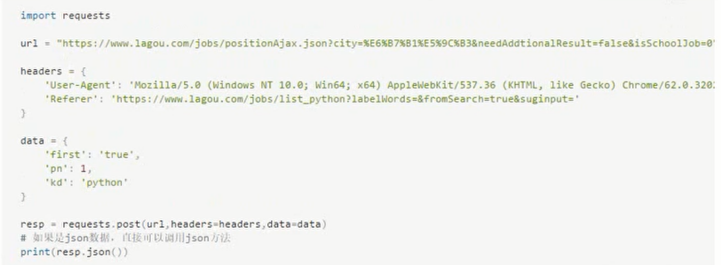
发送post请求非常简单,直接调用‘requests.post()’方法就可以。如果返回的是json数据,那么可以直接调用‘json()’方法
来将json字符串转换为字典或者列表。
使用代理:
使用requests添加代理非常简单,只要在请求方法中(比如:get或者post)传递proxies参数就可以:示例代码:
import requests headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3642.0 Safari/537.36' } url = 'http://httpbin.org/get' proxy = { 'http':'171.14.209.180:27829' } reps = requests.get(url,headers=headers,proxies=proxy) with open('xx.html','w',encoding='utf-8') as fp: fp.write(reps.text)
cookie:
如果在一个响应中包含cookie,那么可以利用cookies属性拿到这个返回的cookie值。
import requests resp = requests.get('http://www.baidu.com') print(resp.cookies) print(resp.cookies.get_dict())
session:
之前使用urllib库,是可以使用opener发送多个请求,多个请求之间是可以共享cookie的。那么如果使用requests,也要达到共享cookie的目的(session能够把cookie中的登录信息保存下来,直接发送请求),那么可以使用requests库给我们提供的session对象。注意,这里的seesion不是web开发中的那个session。
这个地方只是一个会话的对象而已。还是以登录人人为例,使用requests来实现。示例代码如下:
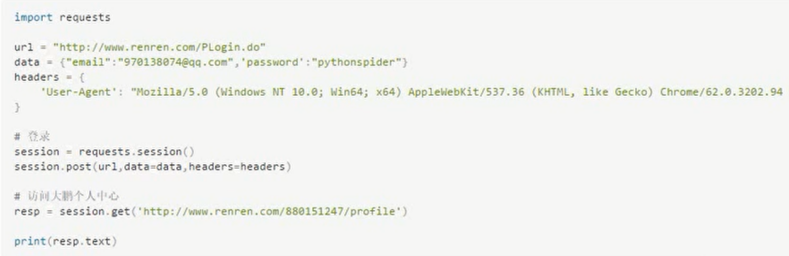
处理不信任的SSL证书(网站带X):
对于那些已经被信任的SSL证书的网站,比如:http://www.baidu.com/,那么使用requests直接就可以正常的返回响应。
resp = requests.get('http://www.12306.cn/mormhweb/',verify=False) print(resp.content.decode('utf-8'))