创建一个可复用的数据结构类库
可复用:就是在不同的工程里面可以使用这门课创建的数据结构库,在不同的编译器、不同的工程里使用DTLib都是可以的。
当代软件架构实践中的经验
——尽量使用单重继承的方式进行系统设计 (单重继承+多接口)
——尽量保持系统中只存在单一的继承树 (在当代的软件架构中是如何来保证呢?创建一个顶层的抽象父类来保证)
——尽量使用组合关系替代继承关系
不幸的事实:
——C++语言的灵活性使得代码中可以存在多个继承树
——C++编译器的差异使得同样的代码可能表现不同的行为
new操作符如果失败会发生什么?
大多数人认为,new失败返回一个空指针
早期的编译器确实在new失败的时候,返回一个空指针。但是现代的C++编译器,行为却不是这样的。在new操作失败的时候,会抛出一个标准库的异常。这就会给我们创建一个可复用的库,带来了困难。因为我们需要考虑当new失败时,库中的代码如何处理?
因此,在创建顶层父类的时候,需要考虑下面的问题了。
创建DTLib::Object类的意义
——遵循经典设计准则,所有数据结构都继承自Object类
——定义动态内存申请的行为,提高代码的移植性
这样的做的好处就是:
1)不使用编译器默认new的行为,自定义一个行为出来,这样就可以保证不同的编译器它表现出来的行为是一样的。不使用编译器默认new的行为,自定义一个行为出来,这样就可以保证不同的编译器它表现出来的行为是一样的。
2)创建了顶层的Object父类,就想尽量的保证在这个数据结构库中它是单一的继承树了。
顶层父类的接口定义
class Object { public: void* operator new(unsigned int size) throw(); void operator delete(void* p); void* operator new[] (unsigned int size) throw(); void operator delete[](void* p); ~Object() = 0 ;//使得顶层的父类是一个抽象类,保证该类的所有子类都有虚函数表的指针。这样做有什么好处?这样就可以去使用动态类型识别相关的技术了。
};
Object.h
#ifndef OBJECT_H
#define OBJECT_H
namespace DTLib
{
class Object
{
public:
void* operator new(unsigned int size) throw(); //在堆空间中创建单个对象时,就会调用这个new的重载实现了.throw表示当前这个函数不会抛出任何异常的。
void operator delete(void* p);
void* operator new[] (unsigned int size) throw(); //在堆空创建对象数组时
void operator delete[](void* p);
virtual ~Object() = 0 ;
};
}
#endif // OBJECT_H
Object.cpp
#include "Object.h"
#include <cstdlib>
namespace DTLib
{
void* Object::operator new(unsigned int size) throw()
{
return malloc(size);
}
void Object::operator delete(void* p)
{
free(p);
}
void* Object::operator new[] (unsigned int size) throw()
{
return malloc(size);
}
void Object::operator delete[](void* p)
{
free(p);
}
Object::~Object()
{
}
}
这样做真的有意义吗?
实验一:
在Object.cpp中打印一些语句,如下:
#include "Object.h"
#include <cstdlib>
#include <iostream>
using namespace std;
namespace DTLib
{
void* Object::operator new(unsigned int size) throw()
{
cout << "void* Object::operator new" << endl;
return malloc(size);
}
void Object::operator delete(void* p)
{
cout << "void Object::operator delete" << endl;
free(p);
}
void* Object::operator new[] (unsigned int size) throw()
{
cout << "void* Object::operator new[]" << endl;
return malloc(size);
}
void Object::operator delete[](void* p)
{
cout << "void Object::operator delete[]" << endl;
free(p);
}
Object::~Object()
{
}
}
在mian.cpp
#include <iostream>
#include "Object.h"
using namespace std;
using namespace DTLib;
class Test : public Object
{
public:
int i;
int j;
};
class Child : public Test
{
public:
int k;
};
int main()
{
Object* obj1 = new Test(); //在堆空间创建Test对象
Object* obj2 = new Child(); //在堆空间创建child对象
delete obj1;
delete obj2;
return 0;
}
打印结果:
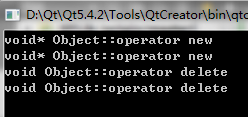
打印结果表明,new和delete使用的不是C++编译器的默认实现了,而是在顶层父类中自定义的实现。
实验二:
在Object.cpp中,再加入如下信息:
#include "Object.h"
#include <cstdlib>
#include <iostream>
using namespace std;
namespace DTLib
{
void* Object::operator new(unsigned int size) throw()
{
cout << "void* Object::operator new" << size << endl;
return malloc(size);
}
void Object::operator delete(void* p)
{
cout << "void Object::operator delete" << p << endl;
free(p);
}
void* Object::operator new[] (unsigned int size) throw()
{
cout << "void* Object::operator new[]" << endl;
return malloc(size);
}
void Object::operator delete[](void* p)
{
cout << "void Object::operator delete[]" << endl;
free(p);
}
Object::~Object()
{
}
}
main.cpp
#include <iostream>
#include "Object.h"
using namespace std;
using namespace DTLib;
class Test : public Object
{
public:
int i;
int j;
};
class Child : public Test
{
public:
int k;
};
int main()
{
Object* obj1 = new Test(); //在堆空间创建Test对象
Object* obj2 = new Child(); //在堆空间创建child对象
cout << "obj1 = " << obj1 << endl;
cout << "obj2 = " << obj2 << endl;
delete obj1;
delete obj2;
return 0;
}
打印结果:
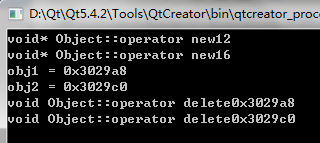
这个地方会有虚函数表指针,所以打印结果会是12和16
释放这两个指针所指向的对象空间的时候,使用的是我们自己提供的实现。这意味着,如果数据结构库中的所有类都继承于Object顶层父类,那我们就可以保证从堆空间创建数据对象的时候,必然使用的是我们自己提供的new和delete的实现了。这就是创建顶层父类的关键所在了。
小结:
Object类是DTLib中数据结构类的顶层父类
Object类用于统一动态内存申请的行为
在堆中创建Object子类的对象,失败时返回NULL
Object类为纯虚父类,所有子类都能进行动态类型识别