1、触发器
触发器是与表相关的数据对象,在满足条件时触发,可以协助应用在数据库端保证数据的完整性
触发器只能创建在永久表上,不能用于临时表(create temporary table )
create trigger 触发器名
触发时间[before 检查约束前触发 | after检查约束后触发]
触发事件 [insert | delete | update]
on 表名 for each row
delimiter @ drop trigger if exists tg_after_insert@ create trigger tg_after_insert after insert on db.lib for each row begin insert into db.flag (text) values('after insert'); end@ delimiter ;
查看所有的触发器:
show triggers;

insert into db.lib values(1,1,'aa') on duplicate key update book_name='aa';
当添加了duplicate key 后,执行insert into 操作插入一条相同主键的记录时,会调用3个触发器
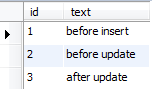
如果插入的数据在已有数据中没有相同数据时,只触发两个触发器
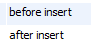
注:在使用duplicate 操作时,注意触发器的触发情况
删除触发器:drop trigger 触发器名
查看触发器:show triggers;
desc triggers;
select * from information_schema.traggers;
注:不能在触发器中显式或隐式开始或结束事务:start transaction commit rollback
当触发器触发前的任意一步发生错误时,都将不会继续执行后续的操作。
2、锁
不同存储引擎支持的锁不一样
myisam、memory存储引擎支持表级锁定(锁定某张表),innodb引擎支持行级锁定(锁定某一行)
表级锁不会出现死锁
行级锁和页级锁可能会出现死锁:死锁的发生一般是由于加锁的次序混乱引起的
表级锁更适合于以查询为主,只有少量按索引条件更新数据的应用,如WEB应用;行级锁更适合于有大量按索引条件并发更新少量不同数据,同时又有并发查询的应用,如 一些在线事务处理(OLTP)系统。//引用
粒度越精细,并发性越好
读锁(共享锁):共享锁,加锁后,其他用户只能读不能写。如果表中没有写锁,将一个读锁放在其上,否则将读锁放在读锁队列中。在其他查询中也只能加共享锁,不 能加排他锁。
写锁(排他锁):独占锁,加锁后,其他用户既不能读也不能写。如果表上没有锁,在其上放一个写锁,否则将写锁放在写锁队列中。当在表中的一行数据中加入了排他 锁后,其含义是其他事务不能再在其上加锁。而由于普通的select from 语句没有在数据中加任何锁,所以是能够直接查询加了排它锁的数据的。
mysql中 innodb引擎中,在使用insert、update、delete语句时会自动给所涉及到的行加上排它锁,而使用select语句时不会加锁,要在select语句中加锁有两种方式:select * from tb_name where ... lock in share mode 或者:select * from tb_name where ...for update. InnoDB
行锁是通过给索引项加锁来实现的,即只有通过索引条件检索数据,InnoDB才使用行级锁,否则将使用表锁!同时,当查询中使用到了子查询,即使加上了行锁,但实际执 行过程中是给表加上了表锁。
lock tables 和 unlock tables
lock tables可以用于锁定当前线程的表,如果表被其他线程锁定,需要等待
unlock 可以释放当前线程的任何锁,当前线程执行另外一个lock table 或当前与服务器的连接断开时,当前线程锁定的表自动解锁。
lock table table_name read/write;//当一个session加了读锁之后,其余的session只能读不能写 unlock tables;//释放锁
3、事务(transaction)MySQL的事务处理功能在MYSIAM存储引擎中是不支持的,在InnoDB存储引擎中是支持的
事务是单个逻辑工作单元执行的一系列操作。这些操作要么全做要么全不做,是一个不可分割的工作单元。
事务具有以下性质:
1)原子性:一个事务要么全做,要么全部不做;
2)一致性:事务的运行不改变数据库中数据的一致性;如完整性约束,a+b=10,当事务将a改变后,b的值也随之改变
3)独立性:两个以上事务不会出现交错执行的现象;
4)持久性:事务执行后,系统的更新是永久的。
开始一项新的事务:start transaction / begin
事务提交:commit [and [no] chain [no] release] ;chain 是事务在提交或回滚之后立即开启一个新的事务,release会断开和客户端的连接。
事务回滚:rollback [and [no] chain [no] release]
自动提交:autocommit
默认情况下是自动提交(autocommit)的,但是可以通过事务提交控制来进行控制。
在锁表期间,用start transaction 开始一个新的事务,会隐含执行一个unlock table。
start transaction; lock table tb_name write; /* 对数据的一系列操作 */ rollback;#以lock方式加的表锁,不能通过rollback进行回滚 start transaction;#在锁表期间开始一个新的start transaction,会导致隐含执行一个unlock table 操作
除了上述的以lock方式加的表锁,不能以rollback回滚外,所有的DDL语句都不能回滚,并且部分DDL语句还会导致隐式提交。
可以通过设置savepoint对事务部分回滚。
strat transaction;
/*
数据操作1;
*/
savepoint test;
/*
数据操作2;
*/
rollback to savepoint test;#回滚到test处
commit;
分布式事务
将一个大的事务由很多分布在不同资源管理器(服务器)上的小事务组成,每个资源管理器上的小事务都必须执行到事务可以提交或回滚的状态。根据每个资源管理器报告相关的执行情况,所有事务要么全部提交,要么全部回滚。管理一个分布式事务,必须要考虑任何一个组件和连接网络可能会出现故障。分布式事务就是为了保证不同数据库的数据一致性。
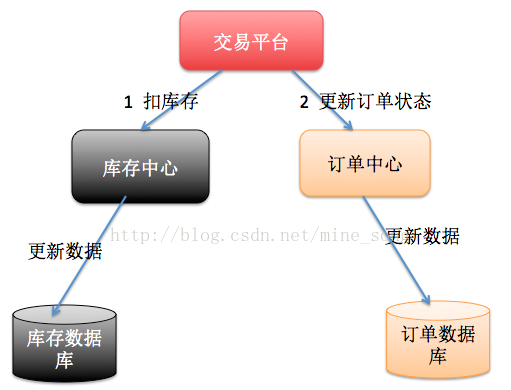
XA:分布式事务协议 主要包括两个阶段
①所有分支被预备好
②事务管理器根据每个资源管理器报告的情况告知所
有资源管理器是一起提交还是一起回滚。
xa start xid(gtrid , bqual , formateid )
xa end xid(gtrid , bqual , formateid )
xa prepare xid(gtrid , bqual , formateid )
xa recover;#返回当前数据库中处于prepare状态的分支事务的详细信息。
xa commit xid(gtrid , bqual , formateid )
xa start 'test','db1';
/*
对数据库的操作
*/
xa end 'test','db1';
xa prepare 'test','db1';
xa recover;#返回当前数据库中处于prepare状态的分支事务的详细信息。
xa commit 'test','db1';
由于mysql数据库中的XA实现,prepare阶段日志在binlog中没有进行记录,在数据库发生异常时,不能通过binlog进行恢复,如果这个事务的其他分支已经提交,而只有这个分支回滚,就会造成分布式事务不完整。