OO_JAVA_JML系列作业_单元总结
(1)梳理JML语言的理论基础、应用工具链情况
简单梳理
以下三者是jml规格里的核心,对一个方法功能和属性的限制:
- requires子句:规定方法的前置条件(precondition);
- assignable子句:方法的副作用范围限定;
- ensures子句:规定方法的后置条件(post condition)。
简单运用
采用OpenJML工具check第一次JML官方开源库代码得到如下结果:
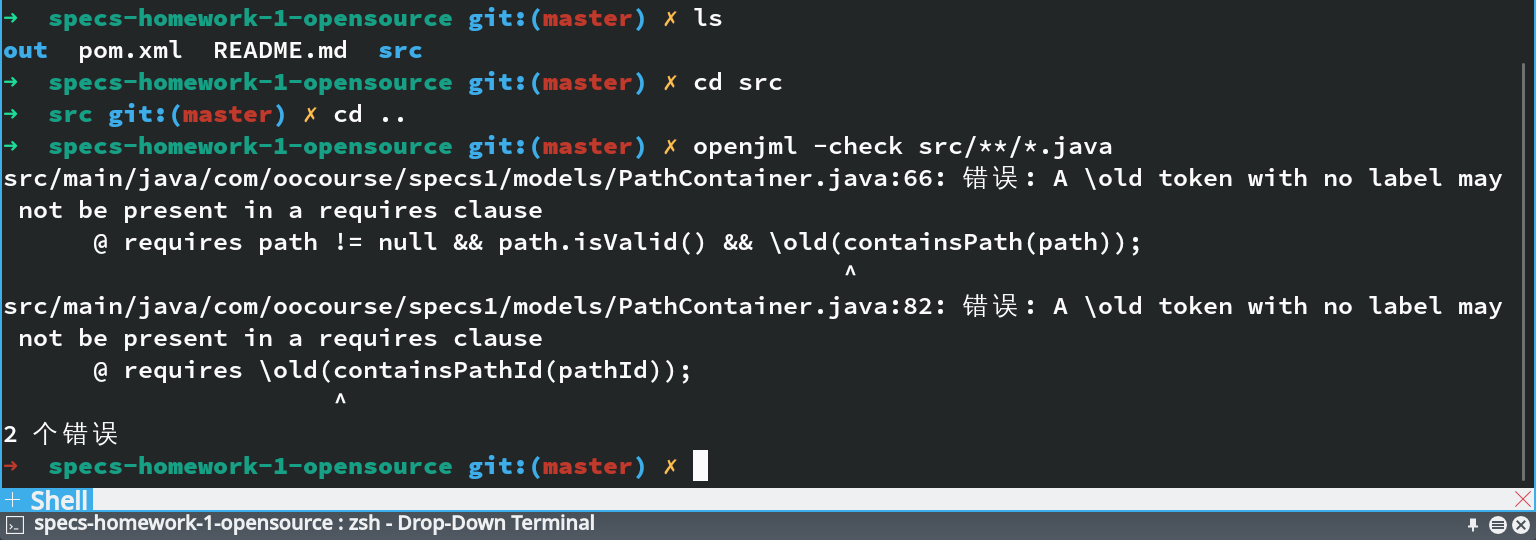
对比第一次和第二次JML规格官方源码:
第一次:
/*@ public normal_behavior
@ requires path != null && path.isValid() && old(containsPath(path));
@ assignable pList, pidList;
@ ensures containsPath(path) == false;
@ ensures (pidList.length == pList.length);
@ ensures (exists int i; 0 <= i && i < old(pList.length); old(pList[i].equals(path)) &&
@
esult == old(pidList[i]));
@ also
@ public exceptional_behavior
@ assignable
othing;
@ signals (PathNotFoundException e) path == null;
@ signals (PathNotFoundException e) path.isValid()==false;
@ signals (PathNotFoundException e) !containsPath(path);
@*/
public int removePath(Path path) throws PathNotFoundException;
第二次:
/*@ public normal_behavior
@ requires path != null && path.isValid() && containsPath(path);
@ assignable pList, pidList;
@ ensures containsPath(path) == false;
@ ensures (exists int i; 0 <= i && i < old(pList.length); old(pList[i].equals(path)) &&
@
esult == old(pidList[i]));
@ ensures (forall int i; 0 <= i && i < old(pList.length) && old(pList[i].equals(path) == false);
@ containsPath(old(pList[i])) && containsPathId(old(pidList[i])));
@ also
@ public exceptional_behavior
@ assignable
othing;
@ signals (PathNotFoundException e) path == null;
@ signals (PathNotFoundException e) path.isValid() == false;
@ signals (PathNotFoundException e) !containsPath(path);
@*/
public int removePath(Path path) throws PathNotFoundException;
发现问题根源在于requires判据本身就发生在该方法执行前,old条件无法在此应用,因为,requires执行时就已经是old的数据了。
(2)部署SMT Solver,至少选择3个主要方法来尝试进行验证,报告结果,有可能要补充JML规格
(3)部署JMLUnitNG/JMLUnit,针对Graph接口的实现自动生成测试用例, 并结合规格对生成的测试用例和数据进行简要分析
对自己编写的graph接口的实现类MyGraph运行JMLUnitNG结果是这样:
➜ src git:(master) ✗ jmlunitng -cp ~/javalib/specs-homework-2-1.2-raw-jar-with-dependencies.jar container/MyGraph.java
JMLUnitNG exited because of an irrecoverable error:
org.jmlspecs.jmlunitng.JMLUnitNGError: Encountered 100 compilation errors:
/home/relia/Projects/Java/OO/graph_management/src/container/MyGraph.java:21: 错误: 非法的类型开始
private HashMap<SymPair<Integer>, Integer> edges = new HashMap<>();
^
/home/relia/Projects/Java/OO/graph_management/src/container/MyGraph.java:24: 错误: 非法的类型开始
shortestRoutes = new HashMap<>();
^
/home/relia/Projects/Java/OO/graph_management/src/container/MyGraph.java:37: 错误: 非法的类型开始
return edges.containsKey(new SymPair<>(var1, var2));
^
/home/relia/Projects/Java/OO/graph_management/src/container/MyGraph.java:49: 错误: 非法的类型开始
if (!shortestRoutes.containsKey(new SymPair<>(var1, var2))) {
^
/home/relia/Projects/Java/OO/graph_management/src/container/MyGraph.java:52: 错误: 非法的类型开始
return shortestRoutes.containsKey(new SymPair<>(var1, var2));
^
/home/relia/Projects/Java/OO/graph_management/src/container/MyGraph.java:61: 错误: 非法的类型开始
return shortestRoutes.get(new SymPair<>(var1, var2));
^
/home/relia/Projects/Java/OO/graph_management/src/container/MyGraph.java:68: 错误: 需要')'
updateEdges(path, this::edgeAddingConsumer);
^
/home/relia/Projects/Java/OO/graph_management/src/container/MyGraph.java:68: 错误: 非法的表达式开始
updateEdges(path, this::edgeAddingConsumer);
^
/home/relia/Projects/Java/OO/graph_management/src/container/MyGraph.java:68: 错误: 需要';'
updateEdges(path, this::edgeAddingConsumer);
^
/home/relia/Projects/Java/OO/graph_management/src/container/MyGraph.java:76: 错误: 需要')'
updateEdges(path, this::edgeRemovingConsumer);
^
/home/relia/Projects/Java/OO/graph_management/src/container/MyGraph.java:76: 错误: 非法的表达式开始
updateEdges(path, this::edgeRemovingConsumer);
^
/home/relia/Projects/Java/OO/graph_management/src/container/MyGraph.java:76: 错误: 需要';'
updateEdges(path, this::edgeRemovingConsumer);
...
可见的是,JMLUnitNG至少不支持两种特性:
- 泛型的自动推断特性,在声明处已经声明的泛型,在new实例化时,不需要填充泛型类型,编译器可以自动推断,但是JMLUnitNG不支持;
- 函数式接口的两种形式都不支持,无论是方法引用的双冒号,还是lambda表达式。
不支持上述特性,难以想象其广泛运用。
(4)按照作业梳理自己的架构设计,并特别分析迭代中对架构的重构
第一次作业
说实话,跟大部分人相同,path container采用三个hash map莽到底,规格很简单,功能很简单,正确性容易达成。
第二次作业
这个也没有什么特色,就是BFS能用,便采用这个算法计算最短路径了,想必跟大部分人也是大同小异的设计。
正确性方面还是较为容易达成的,强测和互测都没有发现bug。
第三次作业
联通集计算
通过一个map来保留联通集的信息,其原理在于单个path内部的连通性是可以保障的,就可以在path ID的基础上建立联通集,我也是这么做的,一个pathID映射该path联通的pathID的集合,这样,就可以在线性时间内完成一次path的添加工作,其线性时间,主要依赖path本身的长度,由于我看见大家都是提到DFS能解决连通性的问题,就这么设计了,所以,我在这里大概说一下我的不一样的联通集的设计思路。
作业架构感想
说实话,没有算法,架构只是纸上谈兵,这是我第三次作业的感想,选择了最朴素的分离解耦的思维,但是在算法上,复杂度过高,没有充分考虑可缓存的,没有充分考虑遍历的控制,虽然降低了每个方法的复杂度,但这样的程序,是没有实际价值的,换言之,我大部分是做了无用功;
到现在,我也没设计出自己的完成第三次作业的思路,虽然学习别人的思路是必要的,我还是想弄清楚,怎样的原因导致了我的遍历无法达到想要的效果,然后深刻理解怎样设计遍历算法,这是我想探究的事物。
我对搜索本身有了更深刻的理解,所谓遍历,究其目的,就是寻找要寻找的目标,或者是在确定的线性集合里搜索,或者是在有更加特殊的结构的集合里搜索,为了完成这个任务,就要有无数优化加入其中,最朴素的,就是排序,排序可以极大的加快搜索的过程,放在单纯的线性集合里,排序可以将集合视为二分集,进行二叉树上的搜索,达到最高的静态集合的搜索效率,而在图结构里,搜索单源最短路径,也可以利用类似的方法,即dijkstra算法,每次根据基础集合从待选集合中搜索路径长度最小的一个,加入基础集合,变相地实现了排序的要求,排序的目的,就旨在滤除不需要的数据或数据集合,将其提前排除,加速搜索的过程。
总的来说,对集合的遍历操作十分依赖集合本身的结构,没有排序这样的优化,计算就永远是暴力计算,是不可取的。
(5)按照作业分析代码实现的bug和修复情况
这个。。第一次有一个bug但是比较隐蔽,强测和互测均未发现,最后是我在第二次作业编写中发现的,并且就排除掉了,是两个path compare的函数的错误,第二次作业最后通过了强测和互测,没有发现bug;
第三次作业,至今为止,我还是没有设计出遍历算法或者遍历同时计算的算法,保证计算的完全性的算法,没有这个,计算出的结果,就不能确定是最小值。
目前还在思考修复中,也许如果不采用讨论区大佬提的拆点算法了话,可能暂时修复不出来。
(6)阐述对规格撰写和理解上的心得体会
规格是对方法结果的一种约束,可以作为需求的一种清晰表述,利于针对其进行规范详尽的测试,因为结果都用可证明的形式描述出来,所以针对jml规格,可以采用更加针对性的测试,测试单个函数的功能正确性,并进一步提高junit的测试手段。
有了完善的规格,一定程度上,有利于我们写出更加正确的程序,当然,其作用主要还是测试方面,根据规格可以更加形式化地验证,乃至采用自动化地方法生成测试程序,甚至测试数据,这都是可能的。