前言
小小的吐槽一下,这篇论文实在是太难读了,细节太多,需要了解的背景知识不少(2PC,Quorum,数据库)。即使看了视频之后,仍然读的不是很懂,所以我用最笨的方法来读:按照论文的标题,逐节摘抄、翻译。我们开始吧。
ABSTRACT
Amazon Aurora 是 Amazon 提供的关系型数据库服务,用于 OLTP。这篇论文主要讲了 Aurora 的架构以及架构设计的出发点:我们相信高吞吐数据处理的瓶颈已经不再是计算和存储了,而是网络。因此 Aurora 带来了船新的架构来解决这个瓶颈,主要的方法是将重做处理下推到一个为 Aurora 专门设计的存储服务上。这个架构能够做到:减少网络流量,故障的快速恢复,Primary 失效时能够无损启用 replicas,容错和自愈的存储。这篇论文还讲了 Aurora 存储节点保持一致的策略。最后,分享了现在的云应用对数据库层的期望需求。
OLTP 中文译为“联机事务处理”。OLTP(OnLine Transaction Processing) 和 OLAP(OnLine Analytical Processing) 相对,前者的特点有,增删查改,ACID,大量用户,涉及数据量相对小,要求可用性,低延时[1]。后者需要对数据进行分析,需要涉及大量数据,甚至整个数据库。Aurora 用于 OLTP,所以要求要有高可用、低延时。因此,在看论文的时候,可以多关注可用性和延时。
1. INTRODUCTION
在现代的分布式云服务中,弹性和可扩展性通过“计算、存储分离”和“在多个节点复制存储”来实现。顺便说一下,弹性指的是云端的可用资源能够随着用户的需求而灵活变化[2]。
问题
在分布式环境下,数据库面临如下三个问题:
- IO 可以在多个节点负载均衡,所以 IO 不再是瓶颈。通过“计算、存储分离”,数据库层和存储层之间的网络通信成为瓶颈。此外,“在多个节点复制存储”,将会加剧这一瓶颈。网络成为新的瓶颈。
- 数据库的大部分操作可以并行,但是在某些情况下仍然需要同步操作。cache miss 的时候,线程需要等待硬盘读取完毕。cache miss 可能还需要弹出页面,将 dirty cache page(修改过的中间数据)写入存储。
- 事务的提交是另一个干扰源。一个事务 commit 延迟了,别的事务也会相应延迟。在分布式环境下,使用 multi-phase synchronization 协议(比如 2-phase commit)来提交事务是有挑战性的。这些协议不能容错,然而分布式系统环境下错误是常见的。
注意 Two-phase commit[3] 和 Two-phase locking[4],前者是一个特殊的分布式共识协议,后者是并发控制模型。2PC 的两阶段为,第一阶段为请求 commit 阶段,让所有的参与者执行一个事务,参与者执行过程没出问题,就返回 yes,否则 no。第二阶段,根据参与者返回的情况,决定是否 commit,如果全部都是 yes,那么 commit。不管 commit 还是 abort,都需要再次通知参与者,参与者根据 commit 还是 abort 来处理。2PL 的两阶段为:伸展阶段,获取锁;收缩阶段,释放锁。
解决
通过更加充分利用重做日志来解决这个问题。我们提出了一个船新的架构,将计算和存储分离。每个数据库实例仍然包含大部分传统数据库的组件,比如 query processor, transactions, locking, buffer cache, accsss methods, undo management。将部分函数下移到存储服务中,比如,redo logging, durable storage, crash recovery, backup/restore。
架构的优点:
- 通过构建独立的、容错自愈的存储服务,让数据库不受网络层、存储层的性能差异和错误的影响。
- 只写 redo log 到存储层,大大减少了网络通信。
- 将数据库中复杂关键的函数,从一次耗时的操作,变成连续异步的操作。因而,我们够做到故障的快速恢复,对前台处理影响小的备份操作。
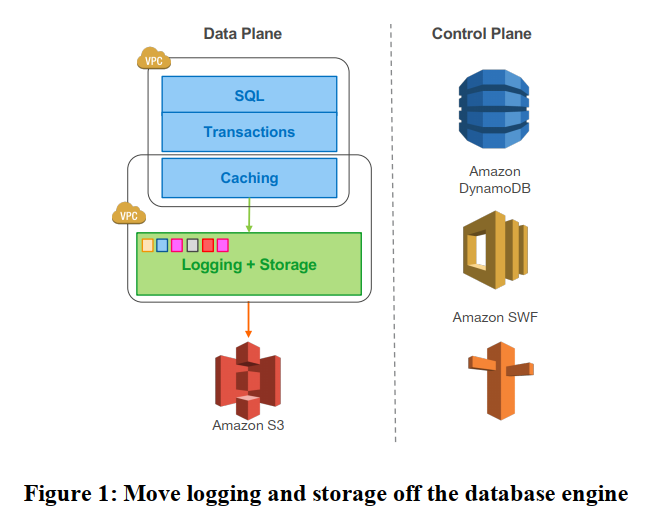
2. DURABILITY AT SCALE
2.1 Replication and Correlated Failures
“计算和存储”分离之后,存储节点也可能故障,因此复制存储节点来容错。Aurora 采用了 Quorum 协议,一般来说 Quorum 采用 3 个节点,读写都要得到两个节点的投票。
我们认为这个配置是不够的。首先先来讲讲 AZ(Availability Zone),AZ 是一个 region 的一个部分,和这个 region 的其他 AZ 通过低延时链路连接起来,你可以理解为一个 data center 就是一个 AZ。AZ 级别的一些 failures 是不相关的,比如断电、洪水。在一个 AZ 内部,硬盘或节点的 failures 是会扩散的。(原话: These failures may be spread independently across nodes in each of AZ A, B and C)。AZ 级别的 failures 是 uncorrelated,比如断电洪水;AZ 内部的 failures 是 correlated,比如硬盘节点的错误。在“一个 AZ 出问题了,同时有一个节点故障”的情况下,不再能读写,也不能确定第三个节点是否最新数据。一般来说,出现这种故障,我们可以通过复制第三个节点来恢复,但是现在的情况是丢失了两个节点,我们不能确定第三个节点是否最新,所以 3 个节点这个配置是不够的。
为此,Aurora 采用了 6 个节点,写入需要 4 个节点的投票,读取需要 3 个节点的投票,使用 3 个 AZ,每个 AZ 用两个节点。有了这样的配置,我们可以做到:
- 一个 AZ 的故障 + 一个节点的故障,还能读到最新数据,重新复制一个存储节点就能写了。
- 丢失任意两个节点,还能写。
Quorum 机制,这里我们来举例说明一下 Quorum 的一致性。Quorum 要求读操作需要读取 (V_r) 个节点,写操作需要写入到 (V_w) 个节点,集群一共有 (V) 个节点。此外还有两条规则:1, (V_r + V_w > V);2, (V_w > V/2)。假如现在有六个节点,我们有 (V=6),(V_w = 4),(V_r = 3),初始情况下数据为:((V_1, V_1, V_1, V_1, V_1, V_1))。现在要写入数据 (V_2),我们必须写入 4 个节点。数据更新为:((V_2, V_2, V_2, V_2, V_1, V_1))。当我们要读数据的时候,根据抽屉原理和第一条规则,我们一定可以读到最新的数据,所以读取 3 个节点之后,不管读取的数据是什么,总是包含最新数据,读取后返回最新的即可。第一条规则保证了总是可以读取到最新的数据[5],加上第二条规则就能保证一致性。此外,Quorum 能够容错。如果有两个节点奔溃了,还有四个节点,因而还是能够写入成功的。
2.2 Segmented Storage
为了保证 durability,需要在出现 uncorrelated failures(AZ 级别)的时候,不能同时有两个节点或硬盘的错误。这样我们就丢失了 4 个节点,因此导致了不能确保读取到最新数据。节点的 MTTF(Mean Time to Failure),要低于修复节点的 MTTR(Mean Time to Repair),否则将很有可能发生两个节点都出故障。如果 MTTF 低于 MTTR,那么一个节点故障了,去修理,还没修理完,有可能别的节点又出现故障。
为了解决这个问题,我们可以考虑降低 MTTF,或者降低 MTTR。但是,MTTF 降到一定程度之后,想要再降低的话是比较困难的,所以我们考虑降低 MTTR。将存储进行分片,每个分片 10GB,六个分片组成一个 PG(Protection Group)。Aurora 会监视分片是否出现故障,在出现故障的时候,会自动恢复分片。当有一个分片出现故障,可以通过高速网络快速复制一个分片进行恢复,这样就大大降低了 MTTR,使到连续两个节点发生故障的概率大大减少了。
2.3 Operational Advantages of Resilience
我们可以利用这个容错机制来做一些骚操作。比如,heat management(我的理解是温度管理),将热的硬盘和节点标注为故障,这样容错机制会自动复制存储节点。再比如,软件升级,我们可以逐一标注节点为故障节点,并进行升级。
3. THE LOG IS THE DATABASE
3.1 The Burden of Amplified Writes
一句话总结: 在分布式的配置下,需要将数据发送给其他节点,输入输出(IO)变得很多,导致了延时过大。
Aurora 使用 6 个节点做存储数据,3 个节点做数据库的实例。任何一个写操作需要进行的 IO 将被放大,IO 量随着节点大大增加。先来看看在传统数据库下,写操作需要做的事情;再来看看一个有镜像的 MySQL 的结构下,写操作如何放大了 IO。
传统数据库
一个写操作,一般需要将数据页写入到对应数据结构(比如B树)中,同时还要写入 log。
镜像 MySQL
看结构图,我们需要两个数据库实例,一个 Primary,一个 Replica,分别放在两个 AZ。我们将 MySQL 的数据存储到 EBS 中,这个 EBS 也需要搞一个镜像。
在这个结构下,一个写入操作,需要发送的数据由:LOG, BINLOG, DATA, DOUBLE-WRITE, FRMFILES。结构图中标注有顺序和需要发送的内容。Primary 需要等待所有的内容写入完毕之后,才能回复客户端,因此大大增加了延迟。此外,需要写入的数据这么多,对延迟也会有影响。下一节,讲 Aurora 如何解决这个问题。
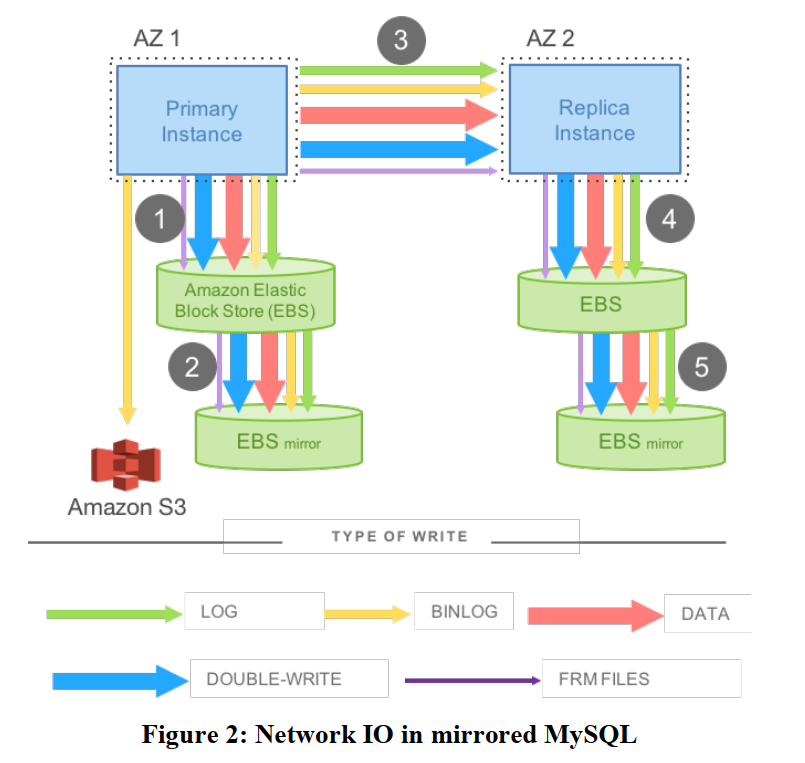
double write:在写入数据页之前,先将数据写入到 doublewrite buffer,确保在发生故障的时候,数据页能从 doublewrite buffer 中找到。官方文档的内容为[6],The doublewrite buffer is a storage area where InnoDB writes pages flushed from the buffer pool before writing the pages to their proper positions in the InnoDB data files. If there is an operating system, storage subsystem, or mysqld process crash in the middle of a page write, InnoDB can find a good copy of the page from the doublewrite buffer during crash recovery.
3.2 Offloading Redo Processing to Storage
一句话总结: 将重做处理下移到存储层。
在传统的数据库中,修改一个数据页,会产生一个 redo log。如果我们保存了前镜像(before-image),我们在上面应用 redo log,我们可以得到后镜像(after-image)。对于事务的提交,我们要求先写 log,数据页的写入可以推迟。
在 Aurora 中,我们采用如下的结构。将重做操作下移到存储层。首先,我们在存储层里面,在内存中维护一份数据库的数据,通过不断应用 redo log,我们可以得到最新的数据。为了避免从头应用 log,我们将数据页定期保存到硬盘。(这里 checkpoint 和 materialize 的区别在于,粒度不同。checkpoint 由整个 log 来控制,而 materialize 由一个特定数据页的 log 来控制)。在结构图中,采用了 3 个数据库实例,6 个存储节点。一个数据库实例挂了,我们可以启用实例的副本。Primary 发送 log 到 6 个存储节点,同时使用 chain replication 发送数据给数据库副本实例。(链式复制如何进行具体看 CRAQ 那个论文)

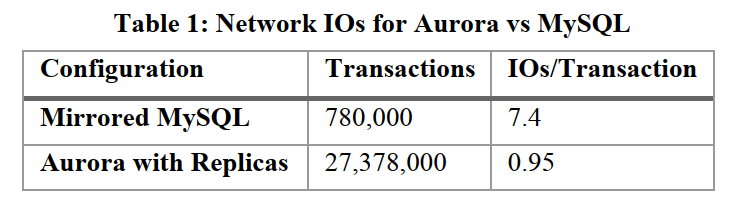
对比镜像 MySQL,在 30 分钟内,Aurora 比镜像 MySQL 能处理的事务多了 35 倍,并且每个事务的 IO 量少了 7.7 倍。
3.3 Storage Service Design Points
存储服务的核心设计原则是:尽可能减少前台写入请求的延时。
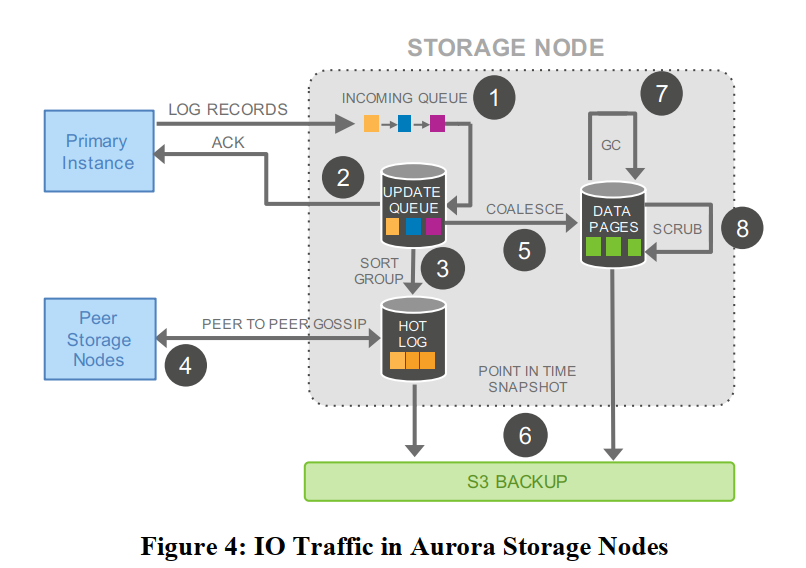
将存储节点上的操作分解成多个步骤的、异步进行的操作,如下图所示。
- 接收 log,加入到队列中
- 保存到硬盘上,并回复数据库实例。
- 整理 log,看看缺了哪些 log
- 和其他存储节点交互,填充丢失的日志
- 合并 log,应用到数据页上。
- 定期将 log 和新的数据页推送到 S3 备份
- 垃圾回收,处理旧数据页
- 定期 CRC 检测,看看数据页是否损坏。
所有的这些操作都能够异步进行,并且只有 1 和 2 会影响反应速度,我们可以让其他操作为 1 和 2 让步,在系统请求比较繁忙的时候,垃圾回收可以不进行或降低频率,除非到达了存储的极限。
4. THE LOG MARCHES FORWARD
在这节,我们描述了 log 是如何产生的,从而保证了持久化状态、运行时状态、副本状态三个状态总是一致 (durable state, runtime state, replica state)。
4.1 Solution sketch: Asynchronous Processing
每一条 log,我们可以标个号 LSN(Log Sequence Number),LSN 是单调递增的。有了标号之后,我们可以简化共识协议,不使用 2PC 这样的协议。存储节点可以检查缺少哪些 log,通过 LSN 向其他存储节点获取 log。
在正常情况下,数据库实例维护的运行时状态,让我们可以仅仅读取一个 segment(因为我们有了 LSN,所以我们可以确定最新的数据);在故障恢复的时候,我们才需要使用 Quorum 协议来读取 segment 来重建。
接下来,分数据库层和存储层来看故障处理。数据库层中可以有多个未完成的事务,当故障发生的时候,由数据库层来决定每个事务是否回滚,我们只是将 redo 下移到存储层,但是我们 undo 还是在数据库层的。在存储层恢复的时候,要保证数据库层看到的是同一个视图。不管数据库层决定回滚还是不回滚,存储层都是要一致的。
借助 LSN,我们可以定义几种日志点:VCL、CPL、VDL。
在 VCL 前所有的 log 都是有的;CPL 定义为某个特定的点,比如 100、200、300 这些整数节点;VDL 是最大的 CPL。VCL 保证了 log 的完整性,CPL 保证了 log 的一致性。在实践中, CPL 可以这样定义。对于数据库级别的事务,我们可以将它分解为 MTR(mini-transaction),MTR 是有次序的原子操作。每个 MTR 由多个连续的 log 构成,我们可以将一个 MTR 中最后的一个 log 标记为 CPL。
数据库层通过和多个节点通信,最终确定好 VDL,然后每个存储节点将 VDL 之后的 log 抛弃,由此存储层就统一了。
4.2 Normal Operation
4.2.1 Writes
写入的时候使用 Quorum,当达到要求(比如 4 个节点投票),数据库实例就推进 VDL 并且将事务标记为 committed。因为有可能数据库层太快了,所以我们分配 LSN 的时候,给它加一个限制:“LSN < VDL + LAL”,LAL 是 LSN Allocation Limit,给 LSN 分配加一个上限。从而让存储层能跟上数据库层。
注意到,在存储节点中,我们将数据分成了 segment,如果一个事务太长了,需要横跨多个 segment。此时,我们可以给 log 加一个 backlink,让它能够找到前一个 log,在我们需要补全 log 的时候,可以通过 backlink 来看需要哪些 log。这里有一个 SCL(Segment Complete LSN) 的概念,顾名思义就是到这个 LSN 为止, Segment 有所有的 log。在交换 log 的时候,可以使用 SCL 来确定是缺这个 log,还是有这个 log.
4.2.2 Commits
事务的提交异步完成,客户端提交一个事务的时候,专门有个线程处理,处理完毕之后,将这个事务放入等待队列,等待提交。在 VDL 推进的时候,如果在队列中有事务的 LSN 比当前 VDL 小,那么提交事务。这个事情专门由一个线程完成,提交之后还要回复客户端已经提交事务。
4.2.3 Reads
Aurora 和传统的数据库一样,从缓存中读取数据,如果缓存中没有才读取硬盘。
当缓存满了,传统的数据库使用页面置换算法来替换缓存页,如果缓存页是一个 dirty page,那么还需要将缓存结果写回到硬盘上。在 Aurora 中,直接丢弃页面,根据页面上的 LSN 决定丢弃哪些,Aurora 保证在缓存中的数据页总是最新的。[7] 中认为论文中有误,应该丢弃的是 page-LSN < VDL 的页面。我认为确实如此,假如我们长期运行 Aurora,如果每次都丢弃新的 page-LSN,那么最终留下来的不就是旧的数据页了吗?从而违反了 Aurora 的保证。
数据库在读取数据的时候,不用 Quorum 来读取。在发起读取的时候,Aurora 将当前的 VDL 作为 read-point,选择一个拥有 read-point 的存储节点来读取数据。因为将数据分段了,Aurora 保存了每个 Segment 的 SCL,所以可以根据 SCL 确定读取哪一个 Segment,读取那个 Segment 所在存储节点。
每一个 PG 可以计算一个最小可读的 LSN(Minimum Read Point LSN),所有的节点之间通过 gossip 来确定 PGMRPL。存储节点不允许读取 LSN 低于 PGMRPL,因此可以推进数据页的版本,对在 PGMRPL 之前的旧 log 进行垃圾回收。
4.2.4 Replicas
前面我们看到 Aurora 的架构,一个 Primary,两个 Replica,这些 Replica 除了容错之外还能做什么呢?答案是作为读副本。虽然 Replica 不能请求写入,但是可以请求读取,这样可以分担一些读请求。为了降低 lag,writer 向存储节点写数据的同时,也向 replica 写数据。replica 接收到 log 的时候,看 log 是否和自己缓存中的数据页相关,如果相关 apply;如果不相关 discard。之后想要读取,可以读取存储节点。
4.3 Recovery
传统数据库中的故障恢复使用检查点来完成。故障发生的时候,恢复到检查点,然后先 redo,再 undo。传统的数据库恢复的时候,数据库处于离线状态。
对于 Aurora,“计算和存储分离”,在存储故障恢复的时候,数据库仍然能在线进行服务。对于数据库挂掉的情况,需要恢复它的运行时状态,可以通过 Quorum 读取到最新的数据来恢复,重新计算 VDL,截取 VDL 之后的日志。
5. PUTTING IT ALL TOGETHER
为了安全使用 Amazon Virtual Private Cloud (VPC,论文里为自家打广告呢),有三类 VPC: Customer VPC,RDS VPC,Storage VPC。Aurora 数据库的控制台使用 Amzon Relational Database Service (RDS,又一波广告) 来提供服务。最后还需要用 Amazon Simple Storage Service (S3,再来一条广告!) 来做整个系统的备份和恢复。

总结
Performance 和 Lessons 这里就不写了。总的来说,Aurora 通过“计算和存储分离”提高了弹性和可扩展性,随之带来的网络瓶颈问题,Aurora 通过将 redo 处理过程下推到存储节点,不传数据页只传 log 解决了网络 IO 的问题。论文还讨论了在分布式的架构下,数据库的常规操作以及一致性问题。
参考链接
[1] https://database.guide/what-is-oltp/
[2] https://cloud.tencent.com/developer/article/1470169
[3] https://en.wikipedia.org/wiki/Two-phase_commit_protocol
[4] https://en.wikipedia.org/wiki/Two-phase_locking
[5] https://www.cnblogs.com/hapjin/p/5626889.html
[6] https://dev.mysql.com/doc/refman/5.7/en/innodb-doublewrite-buffer.html
[7] https://www.cnblogs.com/cchust/p/7476876.html