一.实验目的
通过语法制导或翻译模式生成中间代码。
二.实验环境
①开发语言:java
②开发环境:jdk1.8
三.功能描述
理解并应用课本的语法制导定义。
在自底向上语法分析基础上设计语义规则(语法制导翻译),将源程序翻译为四元式输出,若有错误将错误信息输出。
四.文法和分析表
文法:
program → block
block → { stmts }
stmts → stmt stmts | e
stmt → id= expr ;
| if ( bool ) stmt
| if ( bool) stmt else stmt
| while (bool) stmt
| do stmt while (bool ) ;
| break ;
| block
bool → expr < expr
| expr <= expr
| expr > expr
| expr >= expr
| expr
expr → expr + term
| expr - term
| term
term → term * factor
| term / factor
| factor
factor → ( expr ) | id| num
语义规则SDD
| 产生式 | 语义规则 |
|---|---|
| program → block | |
| block → { stmts } | block.addr=stmt.addr block.code=stmt.code |
| stmts → stmt stmts1 | stmts.addr=new Temp() stmts.code=stmt.code//stmts1.code |
| stmts → stmt | stmts.addr=stmt.addr stmts.code=stmt.code |
| stmt → id= expr ; | stmt.code=expr.code//gen(top.get(id.lexeme)'='id.addr) |
| stmt → if ( bool ) stmt1 | stmt.addr=new Temp() stmt.code=bool.code//label//L1//stmt1.code//Label//L2 |
| stmt → if ( bool) stmt1 else stmt2 | stmt.addr=new Temp() stmt.code=bool.code//label//L1//bool.code//label//L2//stmt1.code//goto L3//label//L2//stmt2.code//lable//L3 |
| stmt → while (bool) stmt1 | stmt.addr=new Temp() stmt.code=label//L1//bool.code//label//L2//stmt1.code |
| stmt → do stmt1 while (bool ); | stmt.addr=new Temp() stmt.code=label//L1//bool.code//label//L2 |
| stmt → break ; | goto next |
| stmt → block | stmt.addr=new Temp() stmt.code=block.code |
| bool → expr1 < expr2 | bool.addr=new Temp() bool.code=expr1.code//expr2.code//gen(bool.addr'='expr1.addr'<'expr2.addr) |
| bool → expr1 <= expr2 | bool.addr=new Temp() bool.code=expr1.code//expr2.code//gen(bool.addr'='expr1.addr'<='expr2.addr) |
| bool → expr1 > expr2 | bool.addr=new Temp() bool.code=expr1.code//expr2.code//gen(bool.addr'='expr1.addr'>'expr2.addr) |
| bool → expr1 >= expr2 | bool.addr=new Temp() bool.code=expr1.code//expr2.code//gen(bool.addr'='expr1.addr'>='expr2.addr) |
| bool → expr | bool.addr=expr.addr bool.code=expr.code |
| expr → expr1 + term | expr.addr=new Temp() expr.code=expr1.code//expr2.code//gen(expr.addr'='expr1.addr'+'term.addr) |
| expr → expr1 - term | expr.addr=new Temp() expr.code=expr1.code//expr2.code//gen(expr.addr'='expr1.addr'-'term.addr) |
| expr → term | expr.addr=term.addr expr.code=term.code |
| term → term1 * factor | term.addr= new Temp() term.code=term1.code//factor.code//gen(term.addr'='term1.addr'*'factor.addr |
| term → term1 / factor | term.addr= new Temp() term.code=term1.code |
| term → factor | term.addr=factor.addr term.code=factor.code |
| factor → ( expr ) | factor.addr=expr.addr factor.code=expr.code |
| factor → id | factor.addr=top.get(id.lexeme) factor.code='' |
| factor → num | factor.addr=top.get(num.lexeme) factor.code='' |
五.程序设计思路
规约式子标号(前项,后项,弹出数,标号)

在实验二的代码上改进,设计语义规则,在规约时执行相应的语义动作。因为该文法是S-SDD所以可以用自底向上的语法分析。
规约的思路具体见实验二
新增全局变量
int num:保存节点的数目
Stack<Integer> stacknum:数值栈
List<String> listop:临时保存四元式集合,用于后期合并
Stack<List> bool:保存各个模块的四元式
语义动作分为3种,一种是识别id,num,创建id,num节点,将他们压入数值栈中。

第二种是二操作符的操作。将数值栈中的节点两个弹出,计算后将新的节点压入数值栈。将语句保存起来,加入临时list中。

第三种是合并的操作。将list的语句合并成一个,放入模块栈中。

六.函数
程序结构描述:函数调用格式、参数含义、返回值描述、函数功能
一系列规约后操作函数如
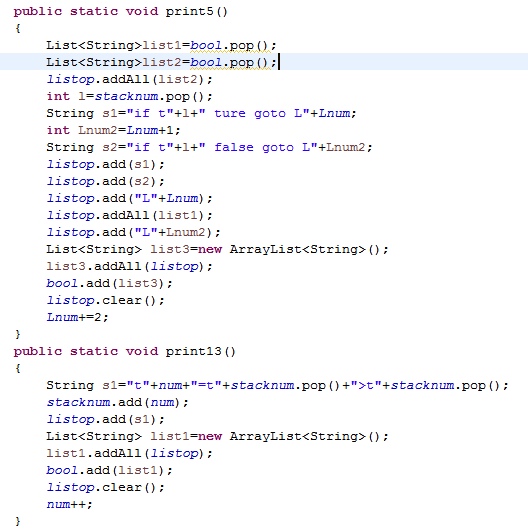
public static void print24()
参数:无
返回值:无
功能:使用24号式子规约时执行,初始化一个新num节点。(图在上面)
七.程序结构描写(部分,其他的在实验二)
就是规约的时候的操作,print后面的数字对应表达式



在规约时进行
if(s2.charAt(0)=='r')//规约
{
String s3=s2.substring(1);
int i=Integer.parseInt(s3);//按照第几条规则规约
if(i==24)print24();
if(i==19)print19();
if(i==15)print15();
if(i==5)print5();
if(i==4)print4();
if(i==7)print7();
if(i==13)print13();
if(i==11)print11();
if(i==12)print12();
if(i==14)print14();
if(i==16)print16();
if(i==17)print17();
if(i==20)print20();
if(i==23)print23();
if(i==9)print9();
if(i==8)print8();
type type=new type();
type=rule.get(i);
int popnum=type.pop;//要弹出几条
print(step,stack.toString(),stack1.toString(),s1,"按照"+type.right+"->"+type.left+"的规则进行规约",0);
for(int flag=0;flag<popnum;flag++)
{
stack.pop();//状态栈弹出
stack1.pop();//符号栈弹出
}
top=stack.peek();//顶端
stack1.push(type.right);
Map<String,String> map2=new HashMap<>();
map2=Mgoto.get(top);//非终结符用goto
if(map2.containsKey(type.right))
{
stack.push(Integer.parseInt(map2.get(type.right)));
top=Integer.parseInt(map2.get(type.right));
}
else
{
System.out.println("error sen!");
p.write(("
语法错误!
当前状态 :"+top+"
无法解析符号 :"+s1).getBytes());
break;
}
}
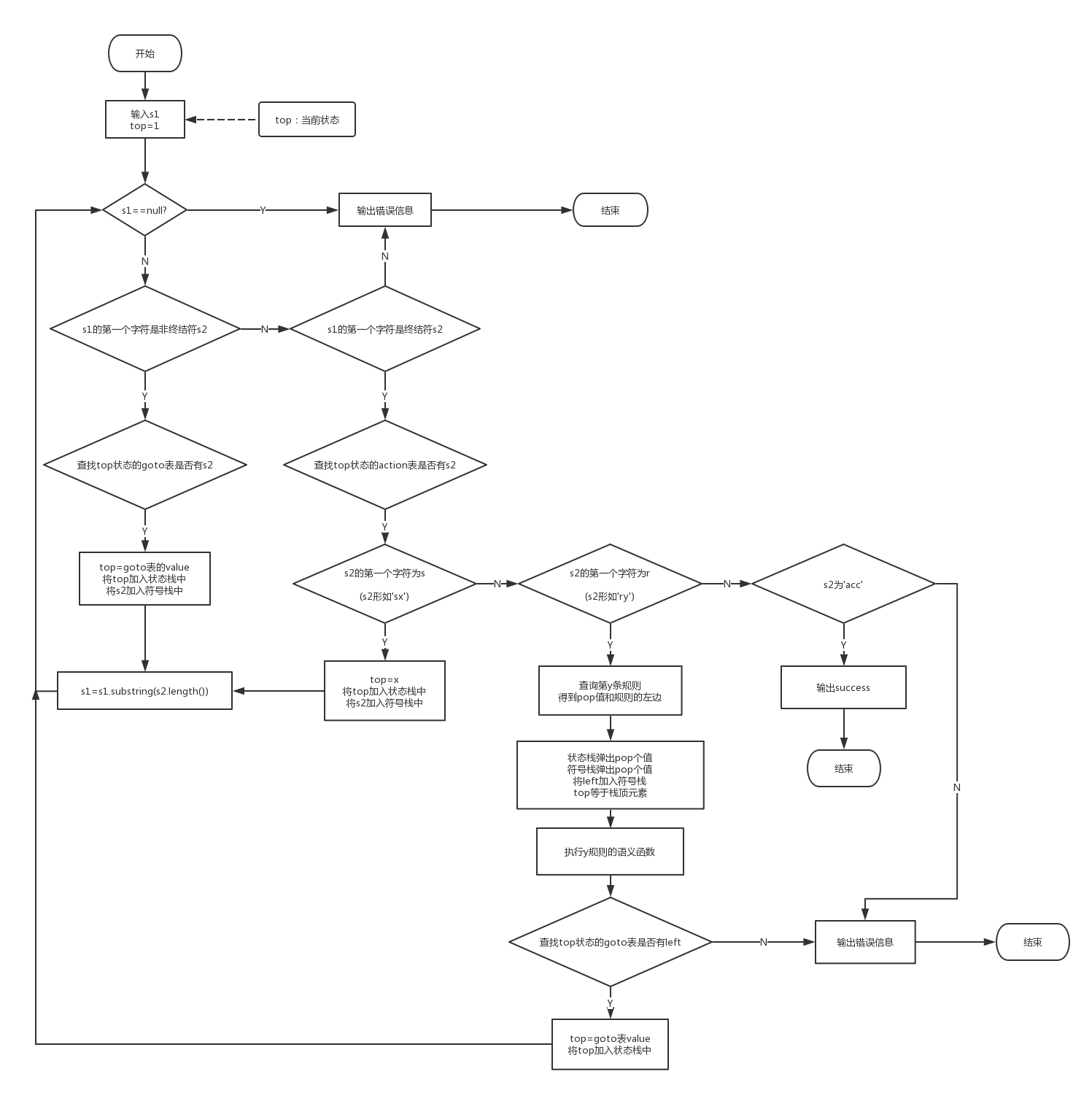
八.流程图(实验二上新增)
新增在规约时执行语义动作
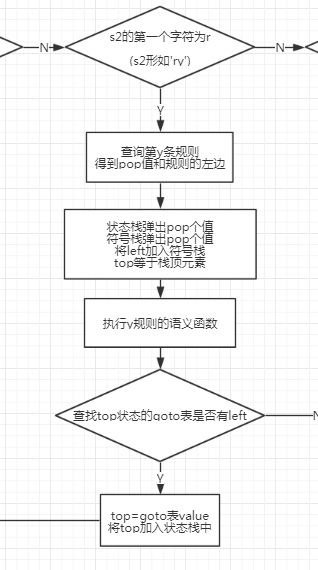
总流程图
九.函数调用(实验二上新增)

十.测试数据(同实验二)
(1)
- 输入

- 输出

(2) - 输入
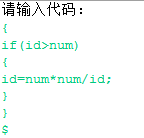
- 输出

(3) - 输入
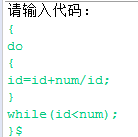
- 输出

(4)错误输入 - 输入

- 输出

十一.总结
这次实验因为是S-SDD的文法总体不算难,就是在实验二的基础上改下就可以了。但是如果是L-SDD的话就会很麻烦。通过这次实验,知道了如何进行语法翻译。通过三次实验下来,对于一个简易编译器的实现已经有了一个整体的构架了,相信在通过自己以后的深入学习,一定能写出属于自己的编译器。