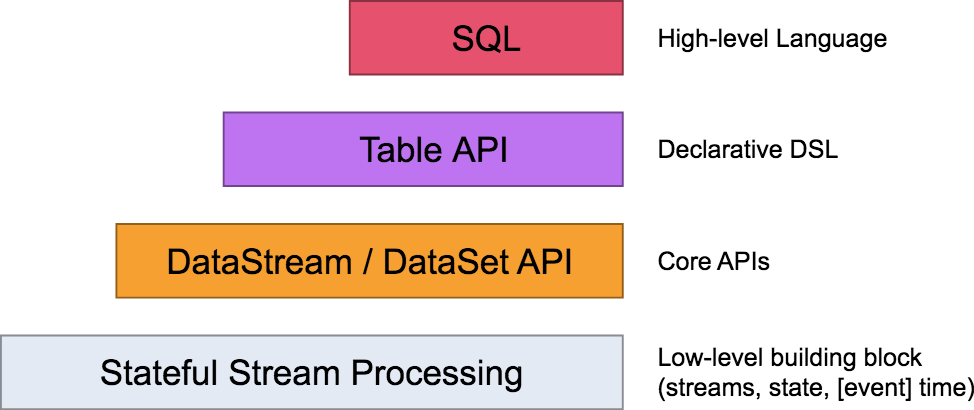
Flink 自身提供了不同级别的抽象来支持我们开发流式或者批量处理程序,下图描述了 Flink 支持的 4 种不同级别的抽象。
Please note that the Table API and SQL are not yet feature complete and are being actively developed. Not all operations are supported by every combination of [Table API, SQL] and [stream, batch] input.
Flink Table & SQL 功能一直处于完善开发中,且在不断进行迭代
Flink’s SQL support is based on Apache Calcite which implements the SQL standard
Flink把 SQL 的解析、优化和执行交给了 Apache Calcite。
Queries specified in either interface have the same semantics and specify the same result regardless whether the input is a batch input (DataSet) or a stream input (DataStream).
Flink 在编程模型上提供了 DataStream 和 DataSet 两套 API,并没有做到事实上的批流统一,因为用户和开发者还是开发了两套代码。正是因为 Flink Table & SQL 的加入,可以说 Flink 在某种程度上做到了事实上的批流一体。
Starting from Flink 1.9, Flink provides two different planner implementations for evaluating Table & SQL API programs: the Blink planner and the old planner that was available before Flink 1.9. Planners are responsible for translating relational operators into an executable, optimized Flink job. Both of the planners come with different optimization rules and runtime classes. They may also differ in the set of supported features. Attention For production use cases, we recommend the old planner that was present before Flink 1.9 for now.
从Flink 1.9开始,Flink提供了两种不同的planner实现来评估Table&SQL API程序,分别是:Blink planner 和Flink 1.9之前的旧planner 。planner负责将关系操作转换为可执行的,并且经过优化的任务。(参考spark catalyst理解)
注意 对于生产情况,建议使用Flink 1.9之前的旧planner。具体如下
<!-- Either... (for the old planner that was available before Flink 1.9) --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner_2.11</artifactId> <version>1.10.0</version> <scope>provided</scope> </dependency> <!-- or.. (for the new Blink planner) --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner-blink_2.11</artifactId> <version>1.10.0</version> <scope>provided</scope> </dependency>
无论是批查询 SQL 还是流式查询 SQL,都会经过对应的Planner Parser 转换成为SQL语法数SQLNode tree,然后生成逻辑执行计划 Logical Plan,逻辑执行计划在经过优化(optimized )后生成真正可以执行的物理执行计划,交给 DataSet(批查询 SQL) 或者 DataStream (流式查询 SQL)的 API 去执行。整体流程跟Spark、Hive也比较相似。
Table API and SQL的编程模型
对于批处理和流式处理, Table API and SQL 编程都遵从相同的模式。
// create a TableEnvironment for specific planner batch or streaming // 创建环境TableEnvironment TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section // create a Table // 获取输入表 tableEnv.connect(...).createTemporaryTable("table1"); // register an output Table // 注册一个输出表 tableEnv.connect(...).createTemporaryTable("outputTable"); // create a Table object from a Table API query // 通过Table API的方式生成表对象 Table tapiResult = tableEnv.from("table1").select(...); // create a Table object from a SQL query // 通过sql查询的方式生成表对象 Table sqlResult = tableEnv.sqlQuery("SELECT ... FROM table1 ... "); // emit a Table API result Table to a TableSink, same for SQL result // 将生成的表结果输出 tapiResult.insertInto("outputTable"); // execute tableEnv.execute("java_job");
有没有spark dataset编程和sql编程的感觉?
创建TableEnvironment
TableEnvironment主要负责以下:
Registering a Table in the internal catalog --在内部catalog中注册Table Registering catalogs --注册catalogs Loading pluggable modules --加载插件模块 Executing SQL queries --执行sql查询 Registering a user-defined (scalar, table, or aggregation) function --注册udf函数 Converting a DataStream or DataSet into a Table --将datastream或dataset转换为Table Holding a reference to an ExecutionEnvironment or StreamExecutionEnvironment --持有对ExecutionEnvironment或StreamExecutionEnvironment的引用
下面分别就Flink流式查询、Flink批次查询、Blink流式查询、Blink批次查询给出了示例
其中Flink和Blink的区别在于Planner的选择,我们在使用中也应当显示给出用哪种Planner
If both planner jars are on the classpath (the default behavior), you should explicitly set which planner to use in the current program.
// ********************** // FLINK STREAMING QUERY // ********************** import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.EnvironmentSettings; import org.apache.flink.table.api.java.StreamTableEnvironment; EnvironmentSettings fsSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build(); StreamExecutionEnvironment fsEnv = StreamExecutionEnvironment.getExecutionEnvironment(); StreamTableEnvironment fsTableEnv = StreamTableEnvironment.create(fsEnv, fsSettings); // or TableEnvironment fsTableEnv = TableEnvironment.create(fsSettings); // ****************** // FLINK BATCH QUERY // ****************** import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.table.api.java.BatchTableEnvironment; ExecutionEnvironment fbEnv = ExecutionEnvironment.getExecutionEnvironment(); BatchTableEnvironment fbTableEnv = BatchTableEnvironment.create(fbEnv); // ********************** // BLINK STREAMING QUERY // ********************** import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.EnvironmentSettings; import org.apache.flink.table.api.java.StreamTableEnvironment; StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment(); EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build(); StreamTableEnvironment bsTableEnv = StreamTableEnvironment.create(bsEnv, bsSettings); // or TableEnvironment bsTableEnv = TableEnvironment.create(bsSettings); // ****************** // BLINK BATCH QUERY // ****************** import org.apache.flink.table.api.EnvironmentSettings; import org.apache.flink.table.api.TableEnvironment; EnvironmentSettings bbSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build(); TableEnvironment bbTableEnv = TableEnvironment.create(bbSettings);
创建表(Create Tables in the Catalog)
表可以是虚拟表(VIEWS)或常规表(TABLES)。VIEWS可以从现有Table对象创建,通常是Table API或SQL查询的结果。TABLES一般为外部数据对应的表,比如文件,数据库表或消息队列。
临时表与永久表
临时表与单个Flink会话的生命周期相关,临时表始终存储在内存中。
永久表需要一个catalog来管理表对应的元数据,比如hive metastore,该表将一直存在,直到明确删除该表为止。
创建虚拟表
// get a TableEnvironment TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section // table is the result of a simple projection query Table projTable = tableEnv.from("X").select(...); // register the Table projTable as table "projectedTable" tableEnv.createTemporaryView("projectedTable", projTable);
通过Connector创建表
比如外部关系型数据库、kafka
tableEnvironment
.connect(...)
.withFormat(...)
.withSchema(...)
.inAppendMode()
.createTemporaryTable("MyTable")
查询表(Query a Table)
以Table API的方式查询表
// get a TableEnvironment TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section // register Orders table // scan registered Orders table Table orders = tableEnv.from("Orders"); // compute revenue for all customers from France Table revenue = orders .filter("cCountry === 'FRANCE'") .groupBy("cID, cName") .select("cID, cName, revenue.sum AS revSum"); // emit or convert Table // execute query
以SQL的方式查询表
// get a TableEnvironment TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section // register Orders table // compute revenue for all customers from France Table revenue = tableEnv.sqlQuery( "SELECT cID, cName, SUM(revenue) AS revSum " + "FROM Orders " + "WHERE cCountry = 'FRANCE' " + "GROUP BY cID, cName" ); // emit or convert Table // execute query
以SQL的方式更新表
// get a TableEnvironment TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section // register "Orders" table // register "RevenueFrance" output table // compute revenue for all customers from France and emit to "RevenueFrance" tableEnv.sqlUpdate( "INSERT INTO RevenueFrance " + "SELECT cID, cName, SUM(revenue) AS revSum " + "FROM Orders " + "WHERE cCountry = 'FRANCE' " + "GROUP BY cID, cName" ); // execute query
此外,也可以Table API和SQL两种方式混合使用。
生成表(Emit a Table / TableSink)
TableSink支持多种文件格式,比如CSV,Apache Parquet,Apache Avro;或者输出到其他存储系统,比如JDBC,Apache HBase,Apache Cassandra,Elasticsearch;也可以写到一些消息中间件,比如Apache Kafka,RabbitMQ
// get a TableEnvironment TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section // create an output Table final Schema schema = new Schema() .field("a", DataTypes.INT()) .field("b", DataTypes.STRING()) .field("c", DataTypes.LONG()); tableEnv.connect(new FileSystem("/path/to/file")) .withFormat(new Csv().fieldDelimiter('|').deriveSchema()) .withSchema(schema) .createTemporaryTable("CsvSinkTable"); // compute a result Table using Table API operators and/or SQL queries Table result = ... // emit the result Table to the registered TableSink result.insertInto("CsvSinkTable"); // execute the program
查看执行计划(Explaining a Table)
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); StreamTableEnvironment tEnv = StreamTableEnvironment.create(env); DataStream<Tuple2<Integer, String>> stream1 = env.fromElements(new Tuple2<>(1, "hello")); DataStream<Tuple2<Integer, String>> stream2 = env.fromElements(new Tuple2<>(1, "hello")); Table table1 = tEnv.fromDataStream(stream1, "count, word"); Table table2 = tEnv.fromDataStream(stream2, "count, word"); Table table = table1 .where("LIKE(word, 'F%')") .unionAll(table2); String explanation = tEnv.explain(table); System.out.println(explanation);
结果:
== Abstract Syntax Tree == LogicalUnion(all=[true]) LogicalFilter(condition=[LIKE($1, _UTF-16LE'F%')]) FlinkLogicalDataStreamScan(id=[1], fields=[count, word]) FlinkLogicalDataStreamScan(id=[2], fields=[count, word]) == Optimized Logical Plan == DataStreamUnion(all=[true], union all=[count, word]) DataStreamCalc(select=[count, word], where=[LIKE(word, _UTF-16LE'F%')]) DataStreamScan(id=[1], fields=[count, word]) DataStreamScan(id=[2], fields=[count, word]) == Physical Execution Plan == Stage 1 : Data Source content : collect elements with CollectionInputFormat Stage 2 : Data Source content : collect elements with CollectionInputFormat Stage 3 : Operator content : from: (count, word) ship_strategy : REBALANCE Stage 4 : Operator content : where: (LIKE(word, _UTF-16LE'F%')), select: (count, word) ship_strategy : FORWARD Stage 5 : Operator content : from: (count, word) ship_strategy : REBALANCE
动态表 (Dynamic Table)
与传统的表 SQL 查询相比,Flink Table & SQL 在处理流数据时会时时刻刻处于动态的数据变化中,所以便有了一个动态表的概念。
动态表的查询与静态表一样,但是,在查询动态表的时候,SQL 会做连续查询,不会终止。
下图显示了流、动态表和连续查询之间的关系:

-
数据流被转换成一个动态表。
-
连续查询动态表,生成新的动态表。
-
生成的动态表被转换回流。
举个例子吧,比如我们用户点击事件的实时数据流,如下
[ user: VARCHAR, // the name of the user cTime: TIMESTAMP, // the time when the URL was accessed url: VARCHAR // the URL that was accessed by the user ]
我们想使用sql查询,那么首先需要将用户点击事件流转换为表,数据流中的每一条数据都视为在表中插入一条数据,如下:

在任何时间点,连续查询的结果在语义上等价于以批处理模式在输入表快照上执行相同查询的结果,比如我们基于用户点击事件表clicks统计每个用户的点击次数:

可以看到 Flink SQL 和传统的 SQL 一样,支持了包含查询、连接、聚合等场景,另外还支持了包括窗口、排序等场景。
SQL操作
详细的看官网吧:https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/sql/queries.html#operations
目前 Flink SQL 支持的内置函数
Flink 中还有大量的内置函数,我们可以直接使用,比如:
-
比较函数
-
逻辑函数
-
算术函数
-
字符串处理函数
-
时间函数
具体的看官网吧,跟平时使用的差不多。
自定义UDF函数
自定义Scalar Functions
需要继承org.apache.flink.table.functions.ScalarFunction类,然后实现一个或多个eval方法(名字要求是eval并且需要是public方法),另外要定义其返回值类型。eval方法也支持变长参数,比如eval(String... strs)
例子:
public class HashCode extends ScalarFunction { private int factor = 12; public HashCode(int factor) { this.factor = factor; } public int eval(String s) { return s.hashCode() * factor; } } BatchTableEnvironment tableEnv = BatchTableEnvironment.create(env); // register the function // 注册函数 tableEnv.registerFunction("hashCode", new HashCode(10)); // use the function in Java Table API // 以Table API的方式使用我们注册的函数 myTable.select("string, string.hashCode(), hashCode(string)"); // use the function in SQL API // 在sql中使用我们定义的函数 tableEnv.sqlQuery("SELECT string, hashCode(string) FROM MyTable");
对于复杂的返回类型,比如我们自己自定义的类,可以通过重写ScalarFunction#getResultType()方法自己定义结果类型的类型信息。
public static class TimestampModifier extends ScalarFunction { public long eval(long t) { return t % 1000; } public TypeInformation<?> getResultType(Class<?>[] signature) { return Types.SQL_TIMESTAMP; } }
Flink 里有三种自定义函数:ScalarFunction,TableFunction 和 AggregateFunction。我们可以从输入和输出的维度对这些自定义函数进行分类。如下图所示,ScalarFunction 是输入一行,输出一行;TableFunction 是输入一行,输出多行;AggregateFunction 是输入多行输出一行。为了让语义更加完整,Table API 新加了 TableAggregateFunction,它可以接收和输出多行。TableAggregateFunction 添加后,Table API 的功能可以得到很大的扩展,某种程度上可以用它来实现自定义 operator。比如,我们可以用 TableAggregateFunction 来实现 TopN。
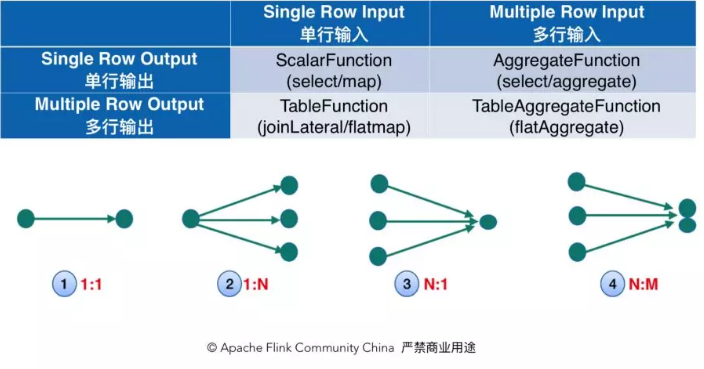
TableAggregateFunction 使用也很简单,方法签名和用法如下图所示:

用法上,我们只需要调用 table.flatAggregate(),然后传入一个 TableAggregateFunction 实例即可。用户可以继承 TableAggregateFunction 来实现自定义的函数。继承的时候,需要先定义一个 Accumulator,用来存取状态,此外自定义的 TableAggregateFunction 需要实现 accumulate 和 emitValue 方法。accumulate 方法用来处理输入的数据,而 emitValue 方法负责根据 accumulator 里的状态输出结果。