20162322 2017-2018-1 《程序设计与数据结构》第五、六周学习总结
教材学习内容总结
集合的介绍(总述)
- 集合是收集并组织其他对象的对象。主要分为线性集合(集合中的元素排成一行)和非线性集合(按不同于一行的方式来组织元素)。
- 决定因素:加入集合的次序、元素之间的固有关系。
抽象数据类型
- 抽象
- 封装
- 抽象数据类型(abstract data type, ADT)
- 数据结构
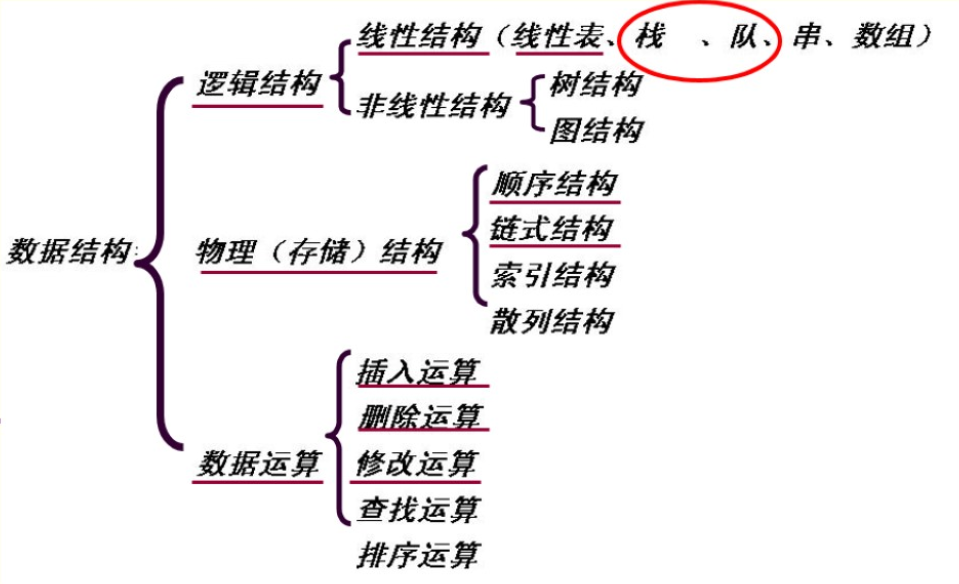
我们研究数据结构就是研究其逻辑结构、物理结构及数据运算。
逻辑结构:本周我们学习的栈和队列均属于线性结构。
物理结构:我们主要研究顺序结构和链式结构,本周我们分别用数组和链表来实现栈、队列。
数据运算:在实现栈和队列时,具体实现了插入、删除和修改运算(查找和排序)
Java Collection API
- Java Collection API(appilication programming interface):使用不同方式实现几类集合的一组类。
- 我们通过学习Java Collection API,学习集合的设计与实现,来深入理解所用的方法及数据结构,避免Java Collection API中的集合类过少,不能满足我们的需求的情况。
下面是具体内容:
第14章 栈
栈集合
栈(stack)是一个线性集合,后进先出(last in, first out, LIFO),反序。
栈中的操作
| 操作 | 描述 |
|---|---|
| push | 将元素添加到栈顶 |
| pop | 删除栈顶的元素 |
| peek | 查看栈顶元素 |
| isEmpty | 判定栈是否为空 |
| size | 判定栈中元素的个数 |
异常
- 入栈时栈满
- 出栈时栈空
- 扫描完表达式时栈中的值多于一个
抛出异常的方式:
if ( ! theStack.isEmpty())
element = theStack.pop();
或
try {
element = theStack.pop();
}
catch (EmptyCollectionException exception) {
System.out.println ("No elements avaliable.")
}
用数组实现栈
数组的容量是固定的,那么若出现“入栈时栈满”这种异常该怎么办呢?
教材中给出三种解决方式:
- 手动扩充容量
- 若满则抛出异常。
- 实现add操作时,让它返回一个状态指示符,来检查操作是否成功。 - 当需要时自动扩展基本数据结构的容量。
具体代码实现要点:
- 变量count既表示数组中用来保存入栈元素的下标位置,也表示栈中当前元素的个数。
- 泛型数组不能数理化,我们可以通过将Object数组强制类型转换为泛型数组的方式进行实例化:
stack = (T[ ])(Object [ DEFAULT_CAPACITY ]); - push操作:(1)确保栈不满(2)注意count
- pop操作:(1)确保栈不空(2)stack[count] = null (3)stack--
用链表实现栈
链式结构使用对象引用变量来建立对象之间联系的一种数据结构。
链表由对象组成,其中每个对象指向表中的下一个对象。
结点存储在链表中的对象。
- 访问元素:创建一个新引用变量非常重要,然后先将该引用指向表的第一个元素。对于一个链表,访问表中元素的唯一方法是从第一个元素开始,从前往后沿表前进。
- 插入结点:修改引用步骤的次序很重要。
- 删除结点
- 哨兵结点
- 没有链的元素:我们必须将链表的细节与表中保存的元素分开。我们可以定义一个独立的结点类,将元素连在一起。结点类包含两个引用:一个用来指向链表中的下一个结点,一个用来指向保存在表中的元素。
- 双向链表
具体代码实现要点:
- 需要一个引用指向表的第一个结点、维护表中的个数。
- 其余与用数组实现一样。
第15章 队列
队列是一个线性集合,在一端添加元素,在另一端删除元素,先进先出(first in , first out, FIFO),原序。
队列中的操作
| 操作 | 描述 |
|---|---|
| enqueue | 将元素添加到队尾 |
| dequeue | 从队头删除元素 |
| first | 检测队头的元素 |
| isEmpty | 判定队列是否为空 |
| size | 判定队列中元素的个数 |
用链表实现队列
队列与栈的区别在于,我们必须要操作链表的两端。因此,除了一个指向链表首元素的引用外,还需要跟踪另一个指向链表末元素的引用。再增加一个整形变量count来跟踪队列中的元素个数。
在课上,娄老师带领我们考虑了边界情况,即操作队头,操作队尾的情况,怎么能省去判断的这一环节呢?这一问题将在接下来的“教材学习中的问题和解决过程”环节具体讨论。
用数组实现队列
分析:
- 将队列的首元素总是存储在数组的索引0处,由于队列处理会影响到集合的两端,因此从队列中删除元素的时候,该策略要求移动元素,这样操作的效率就很低
- 如果将队列的末端总是存储在数组索引0处,当一个元素要入列时,是在末端进行操作的,这就意味着,每个enqueue操作都会使得队列中的所有元素在数组中移动一位,效率仍然很低。
- 如果不固定在哪一端,当元素出列时,队列的前端在数组中前移,当元素入列时,队列的末端也在数组中前移,当队列的末端到达了数组的末端将出现难题,此时加大数组容量是不切合实际的,因为这样将不能有效的利用数组的空闲空间。
因此我们的解决方法是将数组看作是环形(环形数组)的,这样就可以除去在队列的数组实现,环形数组并不是一种新的结构,它只是一种把数组用来存储队列的方法,环形数组即数组的最后一个索引后面跟的是第一个索引。
实现方案:用两个整数值来表示队列的前端和末端,当添加和删除元素时,这些值会改变。注意,front的值表示的是队列首元素存储的位置,rear的值表示的是数组的下一个可用单元(不是最后一个元素的存储位置),而由于rear的值不在表示队列的元素数目,因此我们需要使用一个单独的整数值来跟踪元素计数。
教材学习中的问题和解决过程
- 问题:在课上,娄老师:“为了操作的统一,去掉判断位置的环节我们可以应用头结点来解决问题”,并且在黑板上画了一个上空下空的一个结点(指的是元素和地址均指向空?)我存在以下疑问:
- 头结点究竟是什么?元素指向空,这个我理解,但是这个头结点不应该指向队列的第一个元素吗?为何指向也是空?
- 引入头结点之后该如何操作,使得操作统一,使我们可以不通过判断语句来操作队列?
- 问题解决方案:
- 针对头结点的概念问题我自然是百度的了:头结点是为了操作的统一与方便而设立的,放在第一个元素结点之前,其数据域一般无意义(当然有些情况下也可存放链表的长度、用做监视哨等等)。老师画得上空下空,应该是强调头结点的数据域可以不存储任何信息,而头结点的指针域存储指向第一个结点的指针(即第一个元素结点的存储位置)
- 对带头结点的链表,在表任何结点之间插入结点或删除表中任何结点,所要做的都是修改前一结点的指针域,因为任何元素结点都有前驱结点。若链表没有头结点,则首元素结点没有前驱结点,在其前插入结点或删除该结点时操作会复杂些。
具体代码对比( LinkedList1为“使用头结点实现链表”的情况,LinkedList2为“不使用头结点实现链表”的情况):
(1)在构造方法中:
public LinkedList1() {
//生成一个头结点,让头指针和尾指针都指向它
head = tail = new Entry<T>(null);
size = 0;
}
public LinkedList2() {
head = tail = null;
size = 0;
}
(2)在 isEmpty()方法中:
// LinkedList1
public boolean isEmpty() {
return head.next == null; //当头结点的next为空,表明整个链表为空
}
// LinkedList2
public boolean isEmpty() {
return head == null; //头指针为空,表示整个链表为空
}
(3)在 add方法中:
// LinkedList1
//默认在原链表尾部添加新的结点
public boolean add(T element) {
Entry<T> newEntry = new Entry<T>(element);
tail.next = newEntry;//原链表尾指针的next指向新的结点
tail = newEntry;//尾指针向后移动一位,指向新的结点
size++;
return true;
}
// LinkedList2
public boolean add(T element) {
Entry<T> newEntry = new Entry<T>(element);
if (head == null) //如果头指针为空,直接将新结点赋值给头指针和尾指针
head = tail = newEntry;
else {
tail.next = newEntry; //否则,尾指针的next指向新的结点,尾指针后移一位,指向新的结点
tail = newEntry;
}
size++;
return true;
}
(4)在remove方法中:
// LinkedList1
public T remove(int index) {
//得到索引index的前一个结点
Entry<T> preEntry = previous(index);
T oldVal = preEntry.next.element;
//如果preEntry的next刚好是最后一个结点,修改tail为preEntry
if (preEntry.next == tail)
tail = preEntry;
preEntry.next = preEntry.next.next;
size--;
return oldVal;
}
// LinkedList2
public T remove(int index) {
//获得索引值为index-1的结点
Entry<T> preEntry = previous(index);
T oldVal;
if (preEntry == null) {//index=0 直接操作头指针
oldVal = head.element;
head = head.next;
} else { //其他情况,用获得的前一个结点完成移除操作
oldVal = preEntry.next.element;
//如果preEntry的next刚好是最后一个结点,修改tail为preEntry
if (tail == preEntry.next)
tail = preEntry;
preEntry.next = preEntry.next.next;
}
size--;
return oldVal;
}
综上
最后,再来理一下我们使用头结点的逻辑:对于一个链表,我们在操作的时候只能从前到后,因此,在没有头结点时,我们在插入链表元素时,需要考虑链首、链中和链尾三种情况,三种情况处理方式都不同。(检讨:以前没有考虑全面)有没有什么方式能够省去判断处理位置的情况呢?—>设置一个元素为空的头结点指向链表的第一个元素,这样链表的每一个元素结点都被一个结点指向,在插入链表元素时,链首、链中和链尾三种情况的处理方式就一样啦~
进一步思考:在删除时,链尾的情况需要单独讨论,有没有什么办法能够也省去这一步的判断呢?我想,可以仿照头结点,设置一个“尾结点”,让链尾的元素指向这个尾结点?但是又想这其实并不太方便,头结点之所以方便是因为链表第一个元素是确定的,增加一个头结点又不会影响什么;而添加“尾结点”并不像头结点那么方便,由于链表元素的个数是不确定的,因此,还得先找到这个最后的元素,就感觉略麻烦,因此还是保留判断语句好些。
代码调试中的问题和解决过程
- 问题:
ArrayStack.java :第一行“public class ArrayStack
LinkedStack.java :24行“top = top.getNext(); ”中的“top.getNext();”,37行“current = current.getNext();”中的“current.getNext();”和46行“temp.setNext(top); ”中的“temp.setNext”下面有红线,没有出现红灯泡,将鼠标放在那行出现“Cannot access zylstack.LinearNode”的字样。
ArrayStack.java 能编译成功,
编译 LinkedStack.java 之后,显示的问题是:
“Error:(9, 40) java: 找不到符号
符号: 类 Stack”
- 问题解决方案:
我在网上百度很久都没有解决我的问题。问了张旭升、张师瑜、王老师,他们也都不知道。最后去找了娄老师,老师说代码没有问题。然后在IDEA中重新建了一个项目,就没有再出现此类问题了。
代码托管
结对及互评
- 博客中值得学习的或问题:
- 排版很漂亮,逻辑清晰,很有进步!
- 只是罗列知识点,希望能有更多自己的思考
- 图片较多
- 其他
- 楠楠很棒!加油加油!
本周结对学习情况
- 20162323
- 结对学习内容
- 一起讨论教材学习中的问题
其他(感悟、思考等,可选)
吾日三省吾身:
我究竟学会了什么?
我是否只是记忆住了知识,然后在考完试,就因时间的流逝而遗忘?
我是否理解那些难懂的概念,并能够对其进行迁移?
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 200/200 | 2/2 | 20/20 | |
| 第二周 | 300/500 | 2/4 | 18/38 | |
| 第三周 | 500/1000 | 3/7 | 22/60 | |
| 第四周 | 300/1300 | 2/9 | 30/90 |
-
计划学习时间:10小时
-
实际学习时间:12小时
-
改进情况:多独立动手编代码!