论文:
X-VECTORS: ROBUST DNN EMBEDDINGS FOR SPEAKER RECOGNITION
思想:
X-VECTORS是当前声纹识别领域主流的baseline模型框架,得益于其网络中的statistics pooling层,X-VECTORS可接受任意长度的输入,转化为固定长度的特征表达;此外,在训练中引入了包含噪声和混响在内的数据增强策略,使得模型对于噪声和混响等干扰更加鲁棒;
注: 该模型结构可参见作者17的论文[1]:Deep Neural Network Embeddings for Text-Independent Speaker Verification
模型:
X-VECTORS包含多层帧级别的TDNN层,一个统计池化层和两层句子级别的全连接层,以及一层softmax;损失函数为CE交叉熵

- TDNN:从结构上看TDNN每一层仍然是DNN,只是其每层的输入由历史、当前和未来的特征拼接而层,从而引入时序信息;TDNN结构的优势在于,其相对于LSTM可以并行化训练,又相对于DNN增加了时序上下文信息
- statistics pooling:该统计池化层将输入序列所有帧的TDNN输出取均值和标准差,再将二者拼接起来,得到句子级别的特征表达
- embedding层:X-VECTORS的两层embedding均具有较好的特征表达能力,在kaldi的SRE16、Voxceleb、SITW项目中均采用了embeding a作为说话人编码
- softmax:softmax的节点数为训练集说话人个数
训练:
- 数据集:
- SWBD:2.6k spekaers 28k recordings
- SRE:4.4k speakers 63k recordings
- voxceleb:1191 speakers 20k recordings
- 数据增强:
- 噪声[2]
babble(13-20dB SNR)
music(5-15dB SNR)
noise(0-15dN SNR)
- 混响[3]:RIRS
- 预处理:基于能量的SAD,去静音
- 输入特征:24维fbank
- apply-cmvn-slide,滑窗长度3s
- X-VECTORS结构参数:5*TDNN+1*stats pooling+2*DNN+softmax

- 相似度得分计算:每个输入序列输入到X-VECTORS,第6层输出的embedding作为其特征表达;计算test和enroll特征表达的PLDA[4]得分
实验:
- X-VECTORS取得较好结果的一个原因在于其数据增强策略,能够提升模型的鲁棒性
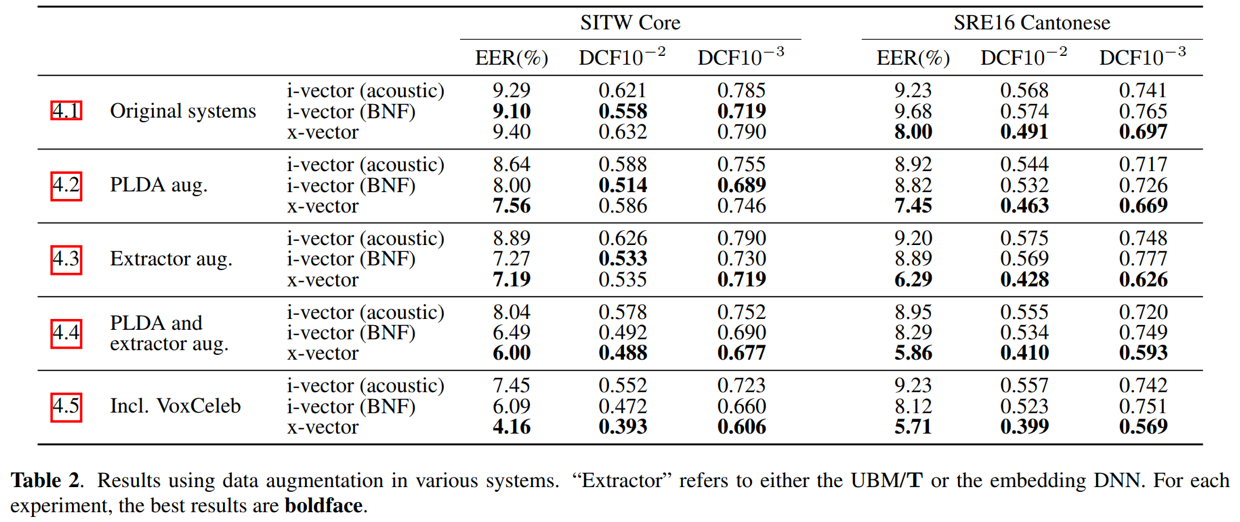
- X-VECTORS在SRE和SITW上的表现均优于传统框架i-vector,无论是错误拒绝率还是错误接受率方面,均具有明显的优势


结论:
本文提出了一种称为X-VECTORS的算法,该算法得益于多层TDNN结构和stats pooling层,能够将帧级别的输入特征转化为句子级别的特征表达embeddding;在计算相似度时,参照i-vector,也采用了人脸识别中的经典算法PLDA来计算相似度得分;此外,论文在训练时还引入了噪声和模拟混响数据增强,提升了模型对噪声和混响的鲁棒性
几个基于kaldi的x-vectors的项目开源模型,亲测泛化能力都不错,并作为了自己项目的初始化模型
Reference:
[2] musan(http://www.openslr.org/17/)
[3] RIRS_NOISES(http://www.openslr.org/28/)
[5] https://www.danielpovey.com/files/2018_icassp_xvectors.pdf(X-VECTORS)