一、截取字符串函数
mysql索引从1开始
1、left(str,length) 从左边截取length
select left('abcd4528',3);
结果为:abc
2、right(str,length)从右边截取length
select right('abcd4528',3);
结果为:528
3、substring(str,index)当index>0从左边开始截取直到结束 当index<0从右边开始截取直到结束 当index=0返回空
select substring('abcd4528',3);
结果为:cd4528
4、substring(str,index,len) 截取str,从index开始,截取len长度
select substring('abcd4528',3,4);
结果为:cd45
5、substring_index(str,delim,count),str是要截取的字符串,delim是截取的字段,count是从哪里开始截取(为0则是左边第0个开始,1位左边开始第一个选取左边的,-1从右边第一个开始选取右边的。找不到返回整个字符串。
例:截取第二个 '.' 之前的所有字符
select substring_index('www.sqlstudy.com.cn', '.', 2);
结果:www.sqlstudy
例:截取第二个 '.' (倒数)之后的所有字符
select substring_index('www.sqlstudy.com.cn', '.', -2);
结果:com.cn
6、subdate(date,day)截取时间,时间减去后面的day
7、subtime(expr1,expr2) 时分秒expr1-expr2
二、find_in_set()函数
语法:
FIND_IN_SET(str,strlist)
str 要查询的字符串,strlist 字段名 参数以”,”分隔 如 (1,2,6,8,10,22)
查询字段(strlist)中包含(str)的结果,返回结果为null或记录。
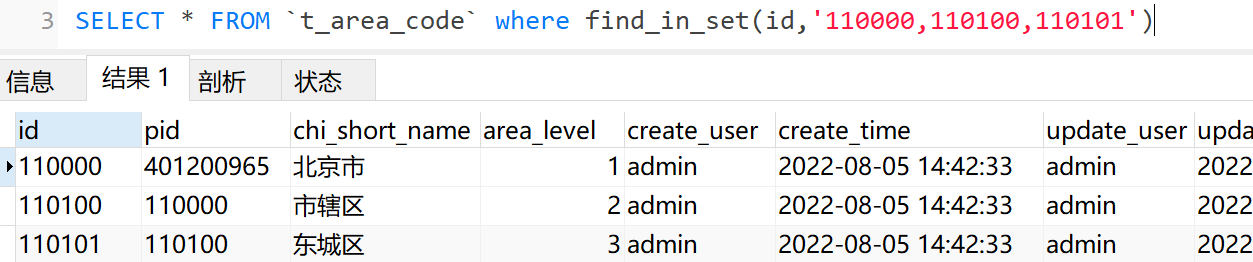
注意:上面的sql语句执行的结果和下面的相同
SELECT * FROM `t_area_code` where find_in_set(id,'110000,110100,110101')>0
例子
SELECT FIND_IN_SET('b', 'a,b,c,d');
结果为2,因为b 在strlist集合中放在2的位置 从1开始。
select FIND_IN_SET('6', '1');
返回0,strlist中不存在str,所以返回0。
find_in_set()和in的区别:
我们来创建表来说明两者的区别
CREATE TABLE `tb_test` ( `id` int NOT NULL auto_increment, `name` varchar(255) NOT NULL, `list` varchar(255) NOT NULL, PRIMARY KEY (`id`) );
插入数据
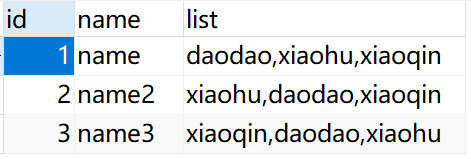
INSERT INTO `tb_test` VALUES (1, 'name', 'daodao,xiaohu,xiaoqin'); INSERT INTO `tb_test` VALUES (2, 'name2', 'xiaohu,daodao,xiaoqin'); INSERT INTO `tb_test` VALUES (3, 'name3', 'xiaoqin,daodao,xiaohu');
数据如下:
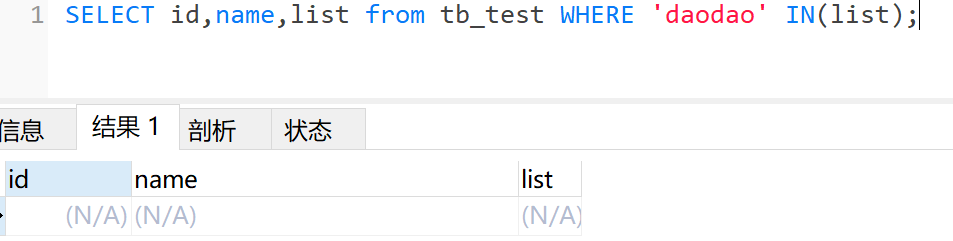
使用in查询list中的部分数据
SELECT id,name,list from tb_test WHERE 'daodao' IN(list);
结果: 发现查不到数据,因为使用in的话必须是完全匹配,否则查不到。
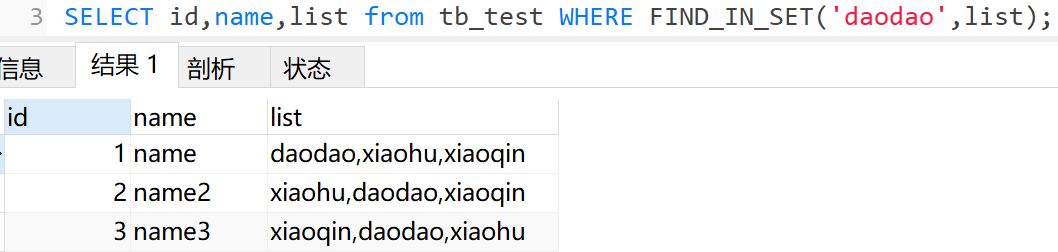
我们使用find_in_set()
SELECT id,name,list from tb_test WHERE FIND_IN_SET('daodao',list);
三、ISNULL(exp) 函数
用isnull判断是否为空:只有name 为null 的时候 ISNULL(exp) 函数的返回值为1 ,空字符串和有数据都为0;
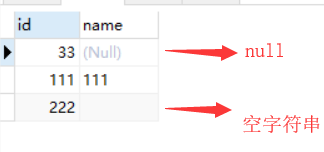
过滤到null的sql 语句:
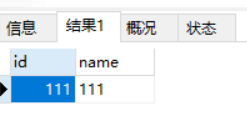
select * from user where name is not null;
或者
select * from user where ISNULL(name)=0;
结果:
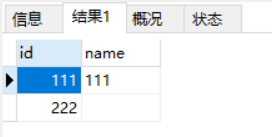
同时剔除null 和 空字符串
select * from user where ISNULL(name)=0 and LENGTH(trim(name))>0;
结果:
在函数或者存储过程中判断是否为null 或者 空字符串
ISNULL(NAME)=1) || (LENGTH(trim(NAME))=0
四、IFNULL函数
IFNULL(expr1,expr2):如果expr1不是NULL,IFNULL()返回expr1,否则它返回expr2。IFNULL()返回一个数字或字符串值,取决于它被使用的上下文环境。
select IFNULL(1,0); // 1 select IFNULL(0,10); // 0 select IFNULL(null,10); // 10 select IFNULL(null,'yes'); // yes
五、IF函数
IF(expr1,expr2,expr3) :如果expr1是TRUE(expr1<>0且expr1<>NULL),那么IF()返回expr2,否则它返回expr3。IF()返回一个数字或字符串值,取决于它被使用的上下文。
select IF(1>2,2,3); -- 3 select IF(1<2,'yes','no'); -- yes select IF(strcmp('test','test1'),'yes','no'); -- yes
六、strcmp函数
此函数比较两个给定的字符串,如果两个字符串相同,则此函数返回0,如果第一个字符串小于第二个字符串,则此函数返回-1,否则返回1
select strcmp('test','test1') -- -1
七、group_concat函数
语法:
group_concat( [DISTINCT] 要连接的字段 [Order BY 排序字段 ASC/DESC] [Separator ‘分隔符’] )
group_concat函数常用于select 语句中,下面我们通过一张表来讲解group_concat函数的用法。
首先来看下初始的select函数:
select * from exam;
上述sql执行结果为:
|id |subject |student|teacher|score| --------------------------------------- |1 |数学 |小红 |王老师 |80 | |2 |数学 |小李 |王老师 |80 | |3 |数学 |小王 |王老师 |70 | |4 |数学 |小张 |王老师 |90 | |5 |数学 |小赵 |王老师 |70 | |6 |数学 |小孙 |王老师 |80 | |7 |数学 |小钱 |王老师 |90 | |8 |数学 |小高 |王老师 |70 | |9 |数学 |小秦 |王老师 |80 | |10 |数学 |小马 |王老师 |90 | |11 |数学 |小朱 |王老师 |90 | |12 |语文 |小高 |李老师 |70 | |15 |语文 |小秦 |李老师 |70 | |18 |语文 |小马 |李老师 |80 | |21 |语文 |小朱 |李老师 |90 | |24 |语文 |小钱 |李老师 |90 |
如果我们希望按分数score进行分组,并将分组后的学生姓名打印下来,就可以用group_concat实现。执行sql:
select score,group_concat(student) from exam group by score;
执行结果为:
|score |group_concat(student) | ------------------------------------- |70 |小王,小赵,小高,小高,小秦 | |80 |小红,小李,小孙,小秦,小马 | |90 |小张,小钱,小马,小朱,小朱,小钱 |
不难看出,在70分这一行有两条小高的记录,90分这一行有两条小钱和小朱的记录,如果我们需要去重,则需要给函数中加一个distinct参数:
select score,group_concat(distinct student) from exam group by score;
执行结果为:
|score |group_concat(student) | --------------------------------- |70 |小王,小赵,小高,小秦 | |80 |小红,小李,小孙,小秦,小马 | |90 |小张,小钱,小马,小朱 |
这样group_concat每行数据的结果中就没有了重复值,但是在数据中的分隔符为默认的逗号',',如果想修改默认的分隔符,只需要在上述指令中稍作修改:
select score,group_concat(distinct student separator '%') from exam group by score;
执行结果:
|score |group_concat(student) | --------------------------------- |70 |小王%小秦%小赵%小高 | |80 |小孙%小李%小秦%小红%小马 | |90 |小张%小朱%小钱%小马 |
下面举例说明:
select id,price from goods;
结果如下:
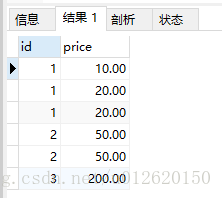
以id分组,把price字段的值在同一行打印出来,逗号分隔(默认)
select id, group_concat(price) from goods group by id;
结果如下:

以id分组,把去除重复冗余的price字段的值打印在一行,逗号分隔
select id,group_concat(distinct price) from goods group by id;
结果:
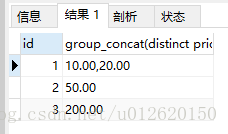
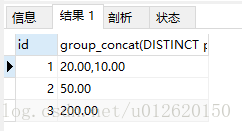
以id分组,把price字段的值去重打印在一行,逗号分隔,按照price倒序排列
select id,group_concat(DISTINCT price order by price desc) from goods group by id;
结果:
示例2:
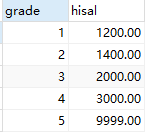
SELECT grade,hisal FROM `salgrade`
结果:
SELECT grade,group_concat(hisal) FROM `salgrade`
结果:

当使用|进行分割时,
SELECT grade,group_concat(hisal SEPARATOR '|') FROM `salgrade`
结果:

SELECT grade,group_concat(concat(grade,'.',hisal) SEPARATOR '|') FROM `salgrade`
结果:

八、substring_index()函数
按分隔符截取字符串
语法:
SUBSTRING_INDEX(str, delimiter, count)
返回一个 str 的子字符串,在 delimiter 出现 count 次的位置截取。如果 count > 0,从则左边数起,且返回位置前的子串;如果 count < 0,从则右边数起,且返回位置后的子串。
mysql> SELECT SUBSTRING_INDEX('www.mysql.com', '.', 2);
-> 'www.mysql'
mysql> SELECT SUBSTRING_INDEX('www.mysql.com', '.', -2);
-> 'mysql.com'
九、replace函数
语法:
REPLACE ( string_expression , string_pattern , string_replacement )
参数
string_expression 要搜索的字符串表达式。string_expression 可以是字符或二进制数据类型。
string_pattern 是要查找的子字符串。string_pattern 可以是字符或二进制数据类型。string_pattern 不能是空字符串 ('')。
string_replacement 替换字符串。string_replacement 可以是字符或二进制数据类型。
翻成白话:REPLACE(String,from_str,to_str) 即:将String中所有出现的from_str替换为to_str。