1 是什么?
海量、离线数据里批处理、分布式计算引擎
2 编程组件?
InputFormat类:分割成多个splits和每行怎么解析。
Mapper类:对输入的每对<key,value>生成中间结果。
Combiner类:在map端,对相同的key进行合并。
Partitioner类:在shuffle过程中,将按照key值将中间结果分为R份,每一份都由一个reduce去完成。
Reducer类:对所有的map中间结果,进行合并。
OutputFormat类:负责输出结果格式。
开发过程就是:拼装以上组件,创建Job,然后执行Job
3 计算过程?
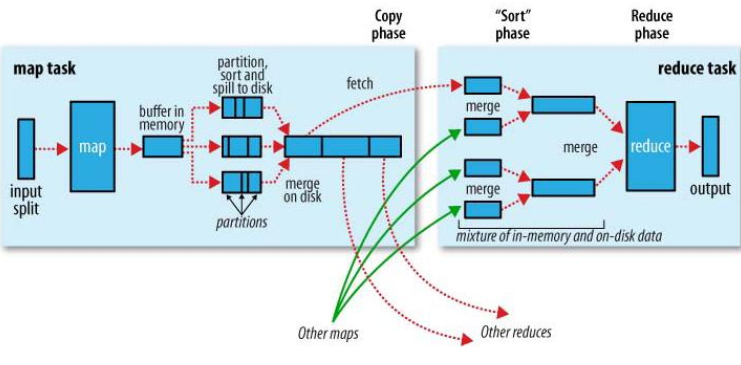
map阶段: input->split->map()->buffer in memory->partitions->merge in disk
输入分解task任务,调用map(先写内存,然后溢写磁盘)
reduce阶段:copy->merge->sort->reduce->output
复制map输出到reduce输入(排序、分组、合并),执行reduce逻辑,输出
图解:
4 优化点?
task个数(input split个数 :取决于单个task 对应文件大小)
map和reduce内存(Jvm参数)