这个是我工作中总结的一些当时不懂的问题,当初记在百度云笔记,觉得这个还是值得分享一下的,因为是给自己看的,可能比较乱一点,但还是很值得一看的,百度云里面还有其他的很多笔记,到时候可能也会看看再继续分享
数据库知识大概网址:
如下图那个就是可以直接回到登录界面的:连接对象资源管理器
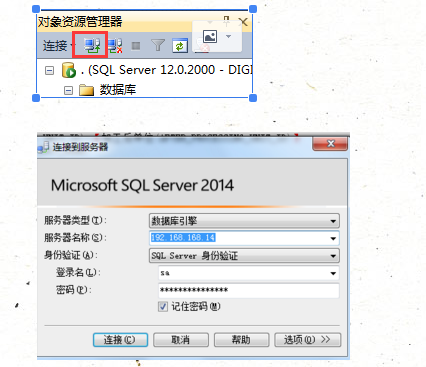
修改sa的密码:
可以先用window登进去之后安全性中的sa点属性就可以改密码,而且每一个网址对应的sa其实是不一样的,也就是说这些密码也是不一样的
而且可以同时连接好几个数据库的呢,点完这个之后就会又多一个数据库,也是可以相互切换操作的
SQL 对大小写不敏感!里面是不需要进行分号隔开的,里面分为DDL(数据库定义语言)和DML(数据库操作语言),数据库定义语言主要包括:创建数据库,表以及索引,修改这三个以及删除(create,drop,alter),数据库操作语言就是包括增删改查
create index:
增加索引的好处就是 首先明白为什么索引会增加速度,DB在执行一条Sql语句的时候,默认的方式是根据搜索条件进行全表扫描,遇到匹配条件的就加入搜索结果集合。如果我们对某一字段增加索引,查询时就会先去索引列表中一次定位到特定值的行数,大大减少遍历匹配的行数,所以能明显增加查询的速度。那么在任何时候都应该加索引么?这里有几个反例:1、如果每次都需要取到所有表记录,无论如何都必须进行全表扫描了,那么是否加索引也没有意义了。2、对非唯一的字段,例如“性别”这种大量重复值的字段,增加索引也没有什么意义。3、对于记录比较少的表,增加索引不会带来速度的优化反而浪费了存储空间,因为索引是需要存储空间的,而且有个致命缺点是对于update/insert/delete的每次执行,字段的索引都必须重新计算更新。 那么在什么时候适合加上索引呢?我们看一个Mysql手册中举的例子,这里有一条sql语句: SELECT c.companyID, c.companyName FROM Companies c, User u WHERE c.companyID = u.fk_companyID AND c.numEmployees >= 0 AND c.companyName LIKE '%i%' AND u.groupID IN (SELECT g.groupID FROM Groups g WHERE g.groupLabel = 'Executive') 这条语句涉及3个表的联接,并且包括了许多搜索条件比如大小比较,Like匹配等。在没有索引的情况下Mysql需要执行的扫描行数是77721876行。而我们通过在companyID和groupLabel两个字段上加上索引之后,扫描的行数只需要134行。在Mysql中可以通过Explain Select来查看扫描次数。可以看出来在这种联表和复杂搜索条件的情况下,索引带来的性能提升远比它所占据的磁盘空间要重要得多。
create table person(id int identity(1,1))或者id int primary key identity(1,1)
alter table person add id int identity(1,1) [表示从1开的之后每次都自增长1]
CASE WHEN:
SELECT SUM(population),
CASE country WHEN '中国' THEN '亚洲'
WHEN '印度' THEN '亚洲'
WHEN '日本' THEN '亚洲'
WHEN '美国' THEN '北美洲'
WHEN '加拿大' THEN '北美洲'
WHEN '墨西哥' THEN '北美洲'
ELSE '其他' END
CASE WHEN salary <= 500 THEN '1'
WHEN salary > 500 AND salary <= 600 THEN '2'
WHEN salary > 600 AND salary <= 800 THEN '3'
WHEN salary > 800 AND salary <= 1000 THEN '4'
ELSE NULL END;
UPDATE XPALLET SET STOCK_STATUS CASE When STOCK_STATUS<>'0' THEN '0' END
以后批量更新记得要直接在下面弄一个集合然后在上面应用,还有一个不要随便用static这个关键字要考虑写一个方法来进行查询
UPDATE [MO_ROUTING] SET [XREM_DATE1]='2017-08-24',[XC0LOR_WARNING]=N'4'
FROM (SELECT [MO_ROUTING].[MO_ROUTING_ID]
FROM [MO_ROUTING] AS [MO_ROUTING]
WHERE [MO_ROUTING].[MO_ROUTING_ID] IN ('0794EBE8-DA28-477A-3DA5- 11919AC17B9E','59119A86-743B-4996-83CD-11919AC1E20C','715BFA76-1F3A-4712-612C-11919AC218D6')) AS subNode
WHERE [MO_ROUTING].[MO_ROUTING_ID] = [subNode].[MO_ROUTING_ID]
一定要记得写别名,这样的会简洁很多:
SELECT A.ITEM_ID ,
A.ITEM_FEATURE_ID ,
A.WAREHOUSE_ID ,
A.BIN_ID ,
A.ITEM_LOT_ID ,
A.INVENTORY_QTY ,
A.SECOND_QTY
FROM ITEM_WAREHOUSE_BIN AS A
LEFT JOIN ISSUE_RECEIPT_D AS B ON A.ITEM_ID = B.ITEM_ID
AND A.ITEM_FEATURE_ID = B.ITEM_FEATURE_ID
AND A.WAREHOUSE_ID = B.WAREHOUSE_ID
AND A.BIN_ID = B.BIN_ID
AND A.ITEM_LOT_ID = B.ITEM_LOT_ID
AND A.INVENTORY_QTY > 0
AND A.SECOND_QTY > 0
LEFT JOIN ISSUE_RECEIPT AS C ON A.Owner_Org_ROid = C.Owner_Org_ROid;
拦截的地址:
就是说在拦截数据库的时候就是当你用的是哪个地址的时候就用哪一个地址,比如说你用的是公司的就是公司的地址,你用本地就本地的地址
以后代码的修改一定要修改一个类之后就立马调试一下,不然返回修改会特别难受
一定要记得前面如果关联的时候有给表取别名的话一定要记得在后面一样也要用别名
上面那个是界面上的字段,下面是更新数据库里面的

SUM(字段)表示查到的所有的这个字段的总和
当所有的逻辑都没错的时候就要想想是不是因为没有这个字段的原因
如果快捷键不行的时候就要记得自己去操作里面的按钮,还有就是ON在数据库中是没有.(点)之类的东西,记得代码中和数据库中的字段可能不是一样的,一定要相信自己,百度之后自己写
SQL逻辑一定要搞清楚,怎么去查的(比如下面这段逻辑)
一段select之外取别名,就像临时表一样,一定要弄清楚这些东西和逻辑
SELECT SUM(CASE CAST([A].[DENOMINATOR] AS INT)
WHEN 0 THEN 0
ELSE ( ( CAST([A].[QTY_PER] AS DECIMAL)
/ CASE CAST([A].[DENOMINATOR] AS INT)
WHEN 0 THEN 1
WHEN N' ' THEN 1
ELSE CAST([A].[DENOMINATOR] AS INT)
END )
* CAST([XPR].[PRICE] AS DECIMAL) )
END) AS [COST1]
FROM [#BomExtract1] AS [A]
LEFT OUTER JOIN ( SELECT
[PR].[ITEM_ID] AS ITEM_ID,
[PR].[ITEM_FEATURE_ID] AS ITEM_FEATURE_ID,
[PR].[PRICE] AS PRICE
FROM
( SELECT
CASE
WHEN [ITEM_SUPPLIER_PRICE].[COMPONENT_PRICE] = 0
THEN [ITEM_SUPPLIER_PRICE].[PRICE]
ELSE [ITEM_SUPPLIER_PRICE_D].[PRICE]
END AS [PRICE] ,
[ITEM_SUPPLIER_PRICE].[ITEM_ID] ,
[ITEM_SUPPLIER_PRICE].[ITEM_FEATURE_ID] ,
[ITEM_SUPPLIER_PRICE_D].[ITEM_SUPPLIER_PRICE_D_ID] ,
ROW_NUMBER() OVER ( ORDER BY CASE
WHEN [ITEM_SUPPLIER_PRICE].[COMPONENT_PRICE] = 0
THEN [ITEM_SUPPLIER_PRICE].[PRICE]
ELSE [ITEM_SUPPLIER_PRICE_D].[PRICE]
END DESC ) AS new_index
FROM
[ITEM_SUPPLIER_PRICE]
AS [ITEM_SUPPLIER_PRICE]
LEFT OUTER JOIN [ITEM_SUPPLIER_PRICE_D]
AS [ITEM_SUPPLIER_PRICE_D] ON [ITEM_SUPPLIER_PRICE].[ITEM_SUPPLIER_PRICE_ID] = [ITEM_SUPPLIER_PRICE_D].[ITEM_SUPPLIER_PRICE_D_ID]
WHERE
( [ITEM_SUPPLIER_PRICE].[APPROVAL_DATE] >= '2014-09-05'
--AND [ITEM_SUPPLIER_PRICE].[ITEM_ID] = [A].[ITEM_ID]
--)
--AND [ITEM_SUPPLIER_PRICE].[ITEM_FEATURE_ID] = [A].[ITEM_FEATURE_ID]
)) AS [PR]
WHERE
[PR].[new_index] = 1
) AS [XPR] ON ( [A].[ITEM_ID] = [XPR].[ITEM_ID]
AND [A].[ITEM_FEATURE_ID] = [XPR].[ITEM_FEATURE_ID]
);
记得及时整理
这个需要将集合插入到临时表或者说要把那个XPR ,Select查出来一个集合,然后用linq语句进行集合之间的操作(就是说需要去查询集合里面的东西然后和其他的表进行关联(就是上面那段代码(那个BomExtract_DATASET集合这样写是错误的写法)))
公司关于SQL语句中将查出来表别名字段进行运算时候的规范:
Formulas.Cast(OOQL.CreateProperty("XPR.PRICE"),GeneralDBType.Decimal), "COST1")
OOQL.CreateConstants(obj["FIXED_LOSS_RATE"], GeneralDBType.Decimal)//公司插临时表
下面必须是OOQL.Creat这种形式才可以,在OOQL语句中(在一个地方就要遵循一个地方的规范):

记得以后的时候要引用一个标准的类的时候并不需要将其弄进来,直接引用dll就行了
自增长:
identity(1,1);//前面是初始值,后面是自增长的值,而且你自增长之后你如果将其中一条数据删掉之后后面还会紧接着加,就比如说你删掉最后一个5,再加一个值就是6,而不会智能地加成5
关联查询:(我的资源文件夹里面的关联查询有详细的)
只要是涉及到Join的都要记得后来那个字段一般情况下都是一样的名称(数据库不区分大小写)

而且一般都是主外键的关系,不然的话也没有什么意义(主外键就是外键的值必须是主键里面有的,不然就加不进去)
inner join和join是一样的:内连接
left join和left outer join是一样的:左(外)连接
right join和right outer join是一样的:左(外)连接
full join和full outer join是一样的:全(外)连接
一般用的最多的就是Left Join,基本上只用这个
记住里面的SQL文件.sql只能将其保存在数据库指定的文件夹之中,就是点完保存之后的那个文件夹,不然的话是保存不下来的:D:我的文档SQL Server Management Studio(eg:我的电脑上路径是这样的)
linq的关联查询(linq多个条件的联合查询在这个文件夹中专门的一个文件说明)
Sum()函数里面是需要写个匿名方法的,用Linq写(查一下,回忆一下这个关联查询,还有linq 里面的一些方法,分析一下下面的linq)
linq必须使用于实现了IEnumerable<T>接口的对象,也就是说必须是泛型集合
下面一段代码的解释:http://www.cnblogs.com/wangfuyou/p/6180557.html 1(AsEnumerable(),里面有连接SQL Server的代码)
http://blog.csdn.net/zzzili/article/details/52085424 2(linq的左连接,右连接以及内连接)
var query1 = from temp1 in table1.AsEnumerable()
join temp2 in table2.AsEnumerable()
on new { PLANT_CODE=temp1.Field<string>("PLANT_CODE"),ITEM_CODE_02=temp1.Field<string>("ITEM_CODE_02"),ITEM_FEATURE_CODE_02=temp1.Field<string>("ITEM_FEATURE_CODE_02") } equals new {PLANT_CODE= temp2.Field<string>("XPLANT_NAME"), ITEM_CODE_02=temp2.Field<string>("XITEM_CODE"),ITEM_FEATURE_CODE_02=temp2.Field<string>("XITEM_FEATURE_CODE") }
into joinEmpDept
from temp2 in joinEmpDept.DefaultIfEmpty()
select new
{
ITEM_CODE = temp1.Field<object>("ITEM_CODE"),
ITEM_FEATURE_CODE = temp1.Field<object>("ITEM_FEATURE_CODE"),
PLANT_CODE = temp1.Field<object>("PLANT_CODE"),
PLANT_CODE_02 = temp1.Field<object>("PLANT_CODE_02"),
STANDARD_BATCH_QTY = temp1.Field<object>("STANDARD_BATCH_QTY"),
SEQ = temp1.Field<object>("SEQ"),
ITEM_CATEGORY = temp1.Field<object>("ITEM_CATEGORY"),
ITEM_CODE_02 = temp1.Field<object>("ITEM_CODE_02"),
ITEM_FEATURE_CODE_02 = temp1.Field<object>("ITEM_FEATURE_CODE_02"),
//...
XPLANT_NAME = b == null ? "" : b.Field<object>("XPLANT_NAME"),
XWAREHOUSE_CODE = b == null ? "" : b.Field<object>("WAREHOUSE_CODE"),
XWAREHOUSE_NAME = b == null ? "" : b.Field<object>("WAREHOUSE_NAME"),
DefaultIfEmpty():
int[] arr1 = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };//构造带元素的数组
int[] arr2 = { }; //构造一个空数组
var query1 = arr1.DefaultIfEmpty(); //DefaultIfEmpty方法判断元素是否为空
var query2 = arr2.DefaultIfEmpty(-1); //DefaultIfEmpty方法判断如果元素为空返回-1
//显示查询结果
foreach (var item in query1)
{
Response.Write(item + " , ");//结果query1={1,2,3,4,5,6,7,8,9}
}
Response.Write("<br/>");
foreach (var item in query2)
{
Response.Write(item + " , ");// 结果query2={-1}
}
临时表(事务?)
一定要记得最好是把一个临时表放在一个using中,之后就可以将临时表释放掉
在本文件夹中的临时表的文件
ROW_NUMBER() OVER (PARTITION by 字段)
http://www.studyofnet.com/news/180.html(开心学习的网址,里面有很多很好的内容,讲的很清楚)
学会使用case
这个为0时候就可以直接把其case一下,如果为0就让整个值赋值0,不能将其设置成if条件
起别名的时候
对于数据库很多一定要起别名,尤其外面用到自己内嵌的select语句查出来的Temp,还有就是像这些函数的求和以及平均值什么的还有运算必须要有别名,不然就会报错
查询表字段以及from表的时候一定要记得取别名,而且要和PR别名不一样,可能是同一个查询里面不能去相同名称的别名,就算表不一样的时候

throw new BusinessRuleException("传票:mSPLIT_DOC_NO 对应的此道工序转移总量不可大于拆分数量!");(代码里面报错 )
审核时,单头和单身都会审核,所以e取得的实体可能是单头也可能是单身
if (string.IsNullOrEmpty(e.Path))
{所以要加上这个

SELECT * FROM (SELECT TOP 1000 SALES_ISSUE.DOC_NO+'-'+CAST(SALES_ISSUE_D.SequenceNumber AS NVARCHAR(20)) AS DOC_NO
FROM SALES_ISSUE_D AS SALES_ISSUE_D
INNER JOIN SALES_ISSUE ON SALES_ISSUE_D.SALES_ISSUE_ID=SALES_ISSUE.SALES_ISSUE_ID
WHERE
--SALES_ISSUE_D.SOURCE_ID_ROid=''
--AND
SALES_ISSUE.ApproveStatus<>'V'
ORDER BY SALES_ISSUE.DOC_NO,SALES_ISSUE_D.SequenceNumber) AS A
UNION ALL
SELECT * FROM (SELECT TOP 1000 SALES_RETURN_RECEIPT.DOC_NO+'-'+CAST(SALES_RETURN_RECEIPT_D.SequenceNumber AS NVARCHAR(20)) AS DOC_NO
FROM SALES_RETURN_RECEIPT_D AS SALES_RETURN_RECEIPT_D
INNER JOIN SALES_RETURN_RECEIPT ON SALES_RETURN_RECEIPT_D.SALES_RETURN_RECEIPT_ID=SALES_RETURN_RECEIPT.SALES_RETURN_RECEIPT_ID
INNER JOIN SALES_RETURN_D ON SALES_RETURN_RECEIPT_D.SOURCE_ID_ROid=SALES_RETURN_D.SALES_RETURN_D_ID
WHERE
--SALES_RETURN_D.SOURCE_ID.ROid=''
-- AND
SALES_RETURN_RECEIPT.ApproveStatus<>'V'
ORDER BY DOC_NO) AS B
必须放在子查询中,还有就是相加的时候需要将int转换成varchar
而且里面必须是有top或者for XML,否则,ORDER BY 子句在视图、内联函数、派生表、子查询和公用表表达式中无效。
还有就是记得在后面等于界面上的值的时候要将其注释掉,以后跟代码的时候再测试,不然的话就无法检验自己写的是对是错
还有就是只有是内嵌select的时候才可以将其别名。字段,不然的话本来就有的表取别名,就像上面的SALES_RETURN_RECEIPT_D ,就可以直接在最下面用别名来排序,不能用别名点字段,因为这个表里是没有这个字段的,但是你查询(这个相当于是总的查询的字段是可以写的)
还有就是像这种的一但全部选择发现有错误的时候就需要将其分开来测试,就比如像union前面和后面分别进行测试就可以了
GUID赋值就是下面那样赋值:
'00000000-0000-0000-0000-000000000000'
'CDCAB790-A674-8BD3-F817-C04C90B7CACD' ,
linq集合
var ValidSN2 = (from vsn in ValidSN1
select new
{
itemId=vsn["ITEM_ID"],
itemFeId=vsn["ITEM_FEATURE_ID"]
}).Distinct();
没有那些Sum以及Count等函数的时候就需要把那个Group by给mark掉了