1. innodb的核心特性
1.1 Innodb的事务的ACID特性:
● Atomic(原子性):所有语句作为一个单元全部成功执行或全部取消,不能出现中间状态
● Consistent(一致性):如果数据库在事务开始时处于一致状态,则在执行该事务期间将保留一致状态
● Isolated(隔离性):事务之间不相互影响
● Durable(持久性):事务成功完成后,所做的所有更改准确地记录在数据库中,所做的更改不会丢失
1.2 事务的声明周期
begin:
sql 语句
commit或者rollback :提交或者回滚
1.3 自动提交机制(autocommit)
mysql> select @@autocommit; +--------------+ | @@autocommit | +--------------+ | 1 | +--------------+ 1 row in set (0.00 sec)
注意:
在线修改参数
set autocommit=0; # 会话级别 ,及时生效
set global autocommit=0; #全局级别 ,断开窗口重连后生效,影响到所有新开的会话
(3)永久生效 vim /etc/my.cnf
autocommit=0;
1.4 事务的acid 特性如何保证?
1.4.1 一些概念名词
脏页:内存脏页,内存中发生了修改,没写入到磁盘之前,我们把内存页称为脏页
redolog : 重做日志,一般会存储在磁盘上(ib_logfile0,ib_logfile1) ,一般大小为50M
xx.ibd :这个是存储数据和索引的文件
buffer_poll: 缓冲区域
LSN: 日志序列号 ,一般存储磁盘数据页,redo文件,buffer pool,redo buffer ,作用:mysql 每次数据库启动,都会比较磁盘数据页和redolog的LSN,必须要求两者LSN一致数据才能正常启动
WAL::日志优先写的方式实现持久化
CKPT:checkpoint,检查点,就是将脏页刷写到磁盘的动作
TXID:事务号,innodb会为每一个事务生成一个事务号,伴随着整个事务周期。
1.4.2 事务日志redolog
作用:主要功能 保证“D", A C 也有一定的作用
●记录了内存数据页的变化
●提供快速的持久化功能(WAL)
●CSR过程中实现前滚的操作(保证磁盘数据页和redo日志LSN一致)
redo日志位置: iblogfile0 ib_logfile1
情况一:
我们做了一个事务,begin;update;commit;
1.在begin时,会立即分配一个TXID=tx_01.
2.update时,会将需要修改的数据页(dp_01,LSN),加载到data_buffer中,
3.DBWR线程,会进行dp_01数据页修改更新,并更新LSN=102.
4.LogBWR日志写线程,会将dp_01数据页的变化+LSN+TXID存储到redobuffer中
5.执行commit时,LGWR日志写线程会将redobuffer信息写入redolog日志文件中,基于WAL原则在日志完全写入磁盘后,commit命令才执行成功,(会将此日志打上commit标记)
6.假如此时宕机,内存脏页没有来的及写入磁盘,内存数据全部丢失
7.mysql再次重启时,必须要redlog和磁盘数据页的LSN是一致的,但是,这时是不一致的
8.于是mysql此时无法正常启动,那么就是触发CSR机制,在内存中追平LSN号,触发CKPT,将内存数据页更新到磁盘中,从而保证磁盘数据页和redolog LSN一致,
这是mysql正常启动
以上过程我们称之基于redo的’前滚操作'
2. undo?
undo日志用户存放数据被修改前的值,简单的说如果修改某表中的某个值的话,例如将tba表中的id=2这行数据的name='a' 修改成为name='a2',那么undo日志就会用来存放name='a'的记录,如果这个修改出现异常,可以使用undo日志来实现回滚操作,来保证事务的一致性。
关于undo的一系列参数:
▲innodb_max_undo_log_size :控制最大undo tablespace文件的大小,当启动了innodb_undo_log_truncate 时,undo tablespace 超过innodb_max_undo_log_size 阀值时才会去尝试truncate该值默认大小为1G,truncate后的大小默认为10M
▲innodb_undo_tablespaces:设置undo独立表空间个数,范围为0-128, 默认为0,0表示表示不开启独立undo表空间 且 undo日志存储在ibdata文件中。该参数只能在最开始初始化MySQL实例的时候指定,如果实例已创建,这个参数是不能变动的,如果在数据库配置文 件 .cnf 中指定innodb_undo_tablespaces 的个数大于实例创建时的指定个数,则会启动失败,提示该参数设置有误,如果设置了该参数为n(n>0),那么就会在undo目录下创建n个undo文件(undo001,undo002 …… undo n),每个文件默认大小为10M.
我们什么时候需要设置这个参数呢?
当DB写压力较大时,可以设置独立UNDO表空间,把UNDO LOG从ibdata文件中分离开来,指定 innodb_undo_directory目录存放,可以制定到高速磁盘上,加快UNDO LOG 的读写性能。
▲innodb_undo_log_truncate:InnoDB的purge线程,根据innodb_undo_log_truncate设置开启或关闭、innodb_max_undo_log_size的参数值,以及truncate的频率来进行空间回收和 undo file 的重新初始化,该参数生效的前提是,已设置独立表空间且独立表空间个数大于等于2个
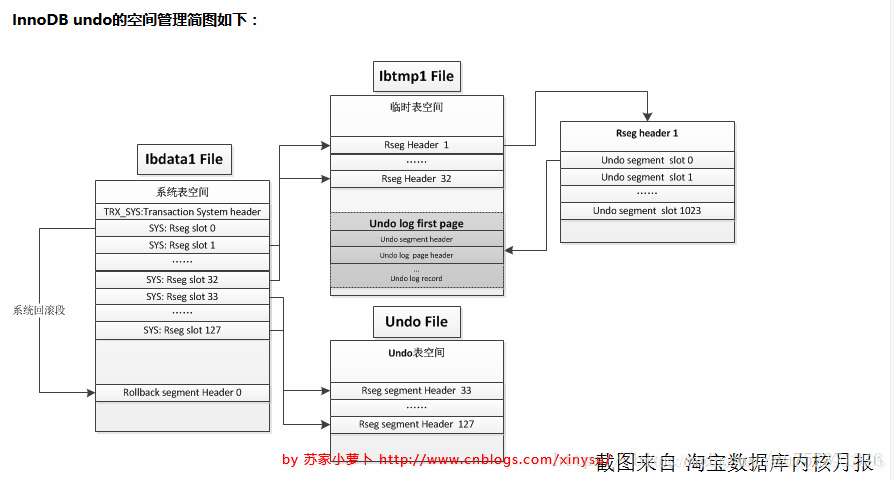
3. undo空间管理
如果需要设置独立表空间,需要在初始化数据库实例的时候,指定独立表空间的数量、UNDO内部由多个回滚段组成,即 Rollback segment,一共有128个,保存在ibdata系统表空间中,分别从resg slot0 - resg slot127,每一个resg slot,也就是每一个回滚段,内部由1024个undo segment 组成。
回滚段(rollback segment)分配如下:
slot 0 ,预留给系统表空间;
slot 1- 32,预留给临时表空间,每次数据库重启的时候,都会重建临时表空间;
slot33-127,如果有独立表空间,则预留给UNDO独立表空间;如果没有,则预留给系统表空间;
回滚段中除去32个提供给临时表事务使用,剩下的 128-32=96个回滚段,可执行 96*1024 个并发事务操作,每个事务占用一个 undo segment slot,注意,如果事务中有临时表事务,还会在临时表空间中的 undo segment slot 再占用一个 undo segment slot,即占用2个undo segment slot。如果错误日志中有:Cannot find a free slot for an undo log。则说明并发的事务太多了,需要考虑下是否要分流业务。
回滚段(rollback segment )采用 轮询调度的方式来分配使用,如果设置了独立表空间,那么就不会使用系统表空间回滚段中undo segment,而是使用独立表空间的,同时,如果回顾段正在 Truncate操作,则不分配
4.redo?
当数据库对数据做修改的时候,需要把数据页从磁盘读到buffer pool中,然后在buffer pool中进行修改,那么这个时候buffer pool中的数据页就与磁盘上的数据页内容不一致,称buffer pool的数据页为dirty page 脏数据,如果这个时候发生非正常的DB服务重启,那么这些数据还在内存,并没有同步到磁盘文件中(注意,同步到磁盘文件是个随机IO),也就是会发生数据丢失,如果这个时候,能够在有一个文件,当buffer pool 中的data page变更结束后,把相应修改记录记录到这个文件(注意,记录日志是顺序IO),那么当DB服务发生crash的情况,恢复DB的时候,也可以根据这个文件的记录内容,重新应用到磁盘文件,数据保持一致。这个文件就是redo log ,用于记录 数据修改后的记录,顺序记录.
4.1 redo 参数
▲innodb_log_files_in_group:每一组redo log 文件的个数,命名方式如:ib_logfile0,iblogfile1… iblogfilen。默认2个,最大100个。
▲innodb_log_file_size:文件设置大小,默认值为 48M,最大值为512G,注意最大值指的是整个 redo log系列文件之和,即(innodb_log_files_in_group * innodb_log_file_size )不能大于最大值512G。
▲innodb_log_group_home_dir:文件存放路径
▲innodb_log_buffer_size:Redo Log 缓存区,默认8M,可设置1-8M。延迟事务日志写入磁盘,把redo log 放到该缓冲区,然后根据 innodb_flush_log_at_trx_commit参数的设置,再把日志从buffer 中flush 到磁盘中
█ innodb_flush_log_at_trx_commit:作用如下图所示:

补充一下:这里有一个fsync来刷新I/O缓存
==0 ###表示事务提交时,Innodb不会立即触发将缓存日志写到磁盘,而是每秒触发一次缓存日志先回写文件系统缓存中,然后立即调用操作系统fsync刷新IO缓存到磁盘文件
==1 ### 表示当事务提交时,Innodb立即触发将缓存日志写到磁盘的文件系统缓存中,然后立即调用操作系统fsync刷新io缓存到磁盘文件
==2 ### 表示当事务提交时,Innodb立即触发将缓存日志写到磁盘的文件系统缓存中,然后不会立即触发刷新缓存,而是每秒触发刷新缓存的。
4.2 redo空间管理
Redo log文件以ib_logfile[number]命名,Redo log 以顺序的方式写入文件文件,写满时则回溯到第一个文件,进行覆盖写。(但在做redo checkpoint时,也会更新第一个日志文件的头部checkpoint标记,所以严格来讲也不算顺序写)。
实际上redo log有两部分组成:redo log buffer 跟redo log file。buffer pool中把数据修改情况记录到redo log buffer,出现以下情况,再把redo log buffer刷下到redo log file:
Redo log buffer空间不足
事务提交(依赖innodb_flush_log_at_trx_commit参数设置)
后台线程
做checkpoint
实例shutdown
binlog切换
5.锁
锁的主要作用是实现了事务之间的隔离性,Innodb存储引擎的下的是行级锁,MyISM存储引擎下的是表级锁
事务的的四种隔离级别:
▲RU(readuncommit):读未提交,这种隔离会出现脏读
▲RC(readcommit):读已提交,这种隔离会出现幻读,但是可以防止脏读
▲RR(repeatread):可重复性读,它可以防止幻读,主要利用的是undo的快照技术+GAP(间隙锁)+nextLock(下一键锁)
▲SR:可串行化,可以防止死锁,但是并发事务性能较差
配置:
transaction_isolation=read-uncommitted transaction_isolation=read-committed transaction_isolation=REPEATABLE-READ
说明:脏读不用解释,幻读其实是在插入数据时容易出现的一个问题,如果在RC模式下,我们在范围插入数据时,会出现和想象结果不一致的情况,具体看应用场景,一般的我们需要在RR模式下才能防止幻读,其实在RR下是添加了两把锁(gap:间隙锁 next-lock锁)这两把锁是防止我们在并发操作数据库时,当我们在两个窗口同时插入数据时,会先给其中一个加上锁,只有第一个事务提交之后,在释放锁,由第一个事务加上,这样就不会发生同一条记录被多人修改时出现幻读现象。