模型结构
code :https://github.com/YichenGong/Densely-Interactive-Inference-Network
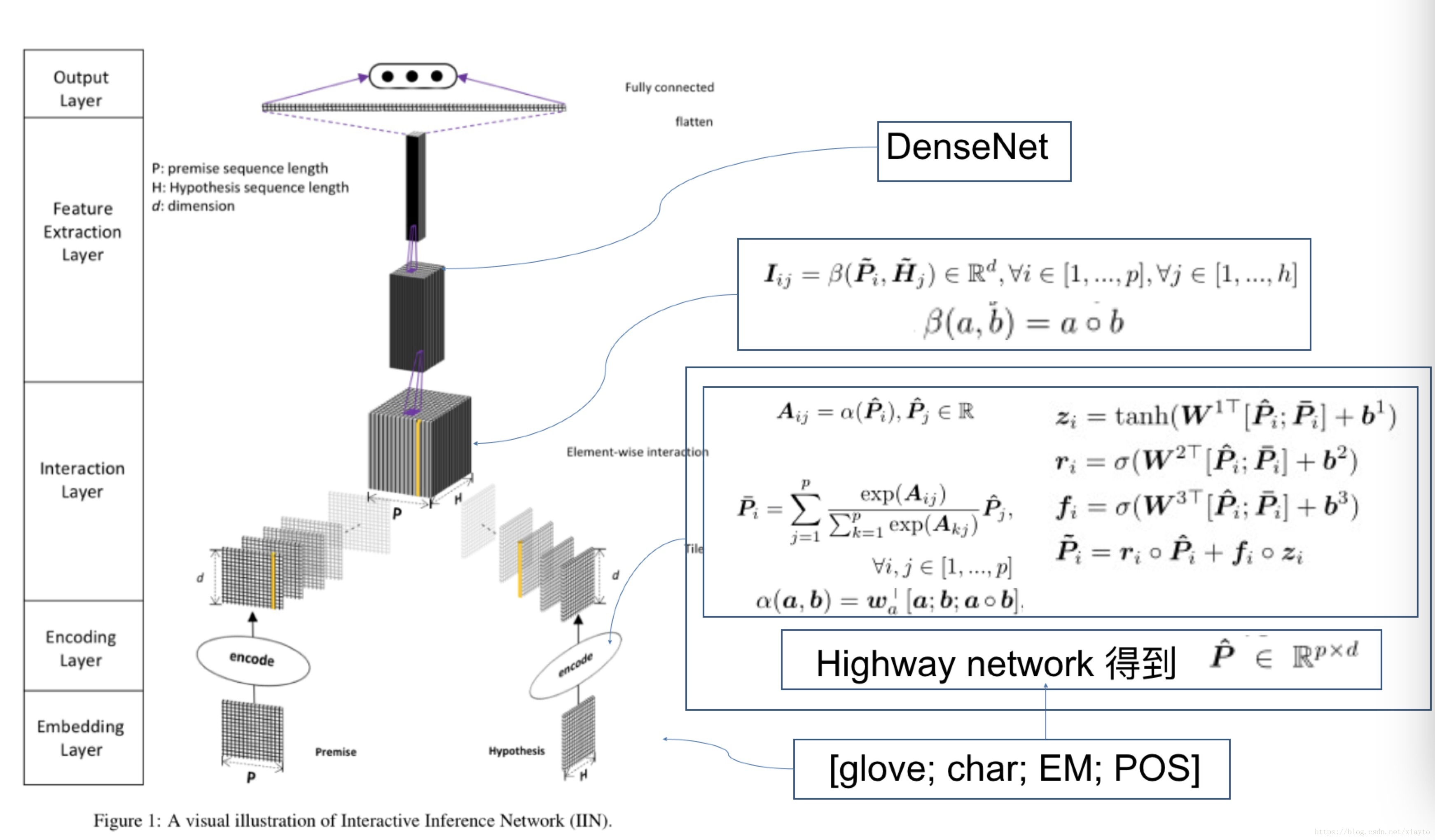
首先是模型图:
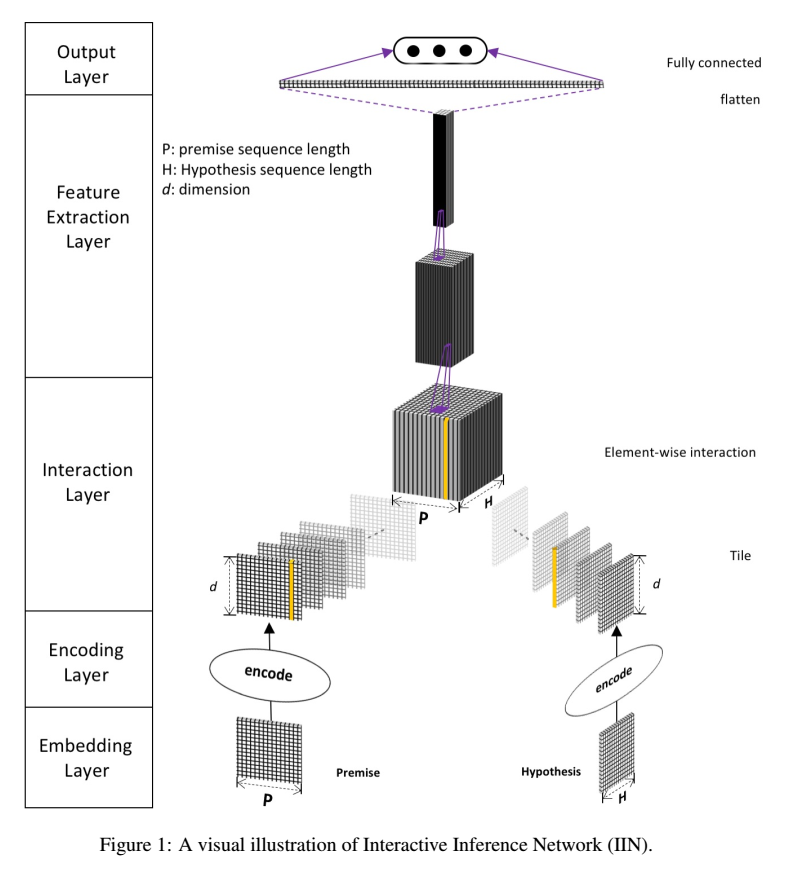
Embedding Layer
词嵌入+字嵌入+syntactical features (句法特征) 拼接。
词嵌入:glove pre-trained, 可训练
字嵌入:conv1d +maxpoling ,解决oov问题,(P,H公用同一个卷积参数)
syntactical features: pos tagging+binary exact match (EM) feature 的onehot
Encoding Layer
P H经过2层highway network 得到 p*d 、h*d维的矩阵,再经过self-attention,self-att公式如下:
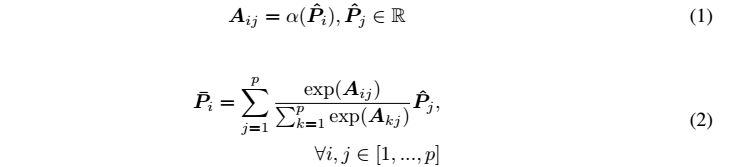
 ~P跟P同时经过fuse-gate,fuse-gate可以看做是skip connection .公式如下
~P跟P同时经过fuse-gate,fuse-gate可以看做是skip connection .公式如下
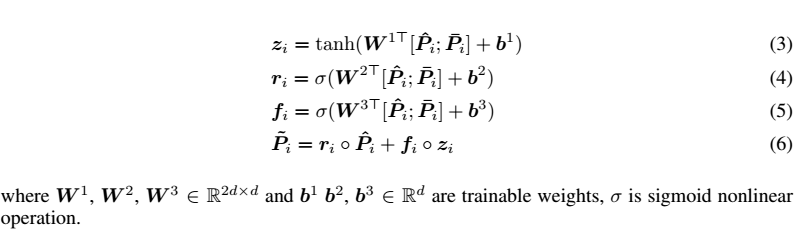
intra-attention and fuse gate 时 ,P H的参数不共享。但是参数权重的差异会加惩罚,为了保证PH可以平行的学习相似性。

Interation Layer
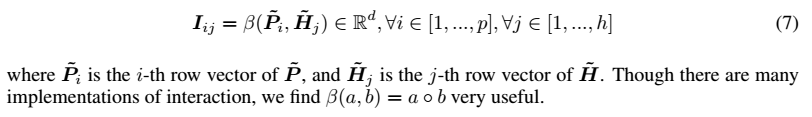
Feature Extraction Layer
利用denseNet进行特征提取,resNet 也可以,但是参数太多。
没有用BN,
激活函数relu。具体细节看代码。
Output Layer
uses a linear layer and flattened 进行分类、
感想
0、词向量的表示上,
1、DenseNet,
2、fuse-gate,
参考:
https://blog.csdn.net/xiayto/article/details/81247461