大数据是一般的数据库无法进行处理,只能用hadoop来处理
1 IT历史
1.1mysql的单机版
app-->jdbc-->mysql
90年代
web页面都是静态网页,服务器没有太大 的压力,
但是web有瓶颈
1.1.1Mysql数据量太大,一个机器存不下
1.1.2数据超过300W,一定要加上索引,一个机器的索引放不下
1.1.3服务器的访问量太大,一个服务器承受不了
1.2memcached(缓存)+mysql+垂直拆分(读写分离)

1.3分库分表+水平拆分(集群)
数据库的实质是在解决读写操作
物理优化
早期的数据库Mysam:表锁 ,十分麻烦,为了查一条数据,将一个表锁起来
转站 行锁Inodb:行锁
慢慢使用分库分表解决读写压力,mysql推出了表分区,还推出了mysql的集群,很好解决了部分需求

1.4如今的年代
2010-2020 十年之间发生了翻天覆地的变化
mysql的关系型数据库不够用,数据量大,变化很块,效率低
图形数据库(Oss)
Bosn(json的二进制)
灰度发布
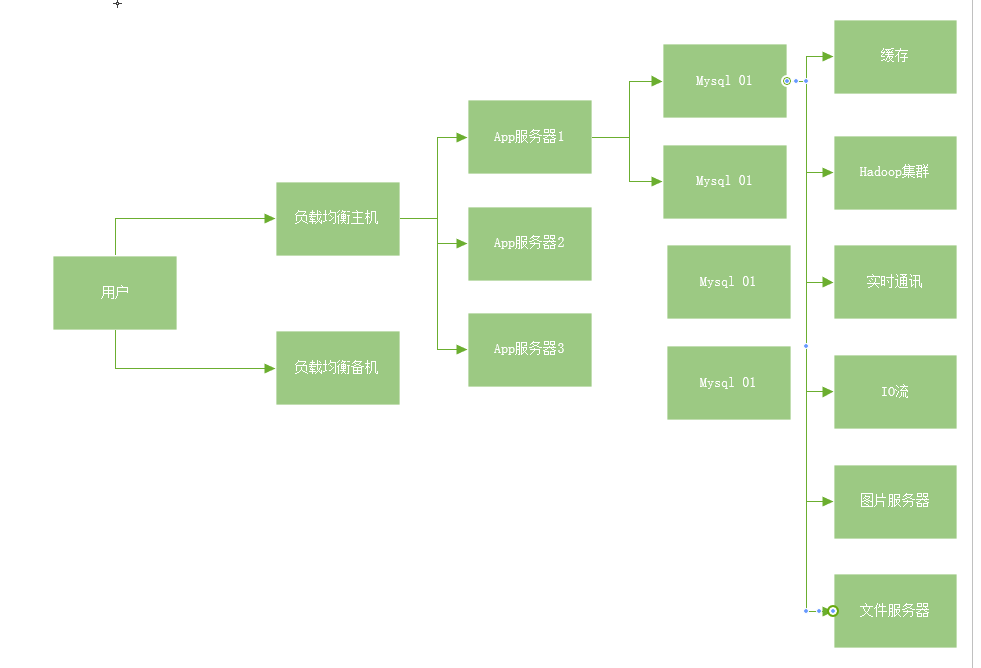
目前基本的互联网项目架构