Selenium库是一个自动化测试工具,能够驱动浏览器模拟人的操作,如鼠标单击、键盘输入等。通过Selenium库能够比较容易地获取到网页的源代码,还可以进行网络内容的批量下载。特别对于一些动态网页很实用。
本次内容以巨潮网为例,进行pdf文件的下载操作。
以Chrome浏览器为例,需要下载并安装模拟浏览器ChromeDriver,这部分也很重要,网上有教程可以学习。
第一步:打开网站
以中国银行的相关内容为例。
# 使用selenium进行爬虫 # 爬取巨潮咨询网上关于中国银行的相关材料 from selenium import webdriver import time import re browser = webdriver.Chrome() url = 'http://www.cninfo.com.cn/new/fulltextSearch?notautosubmit=&keyWord=中国银行' browser.get(url) time.sleep(10)
会自动打开一个网页:
第二步:点击更多
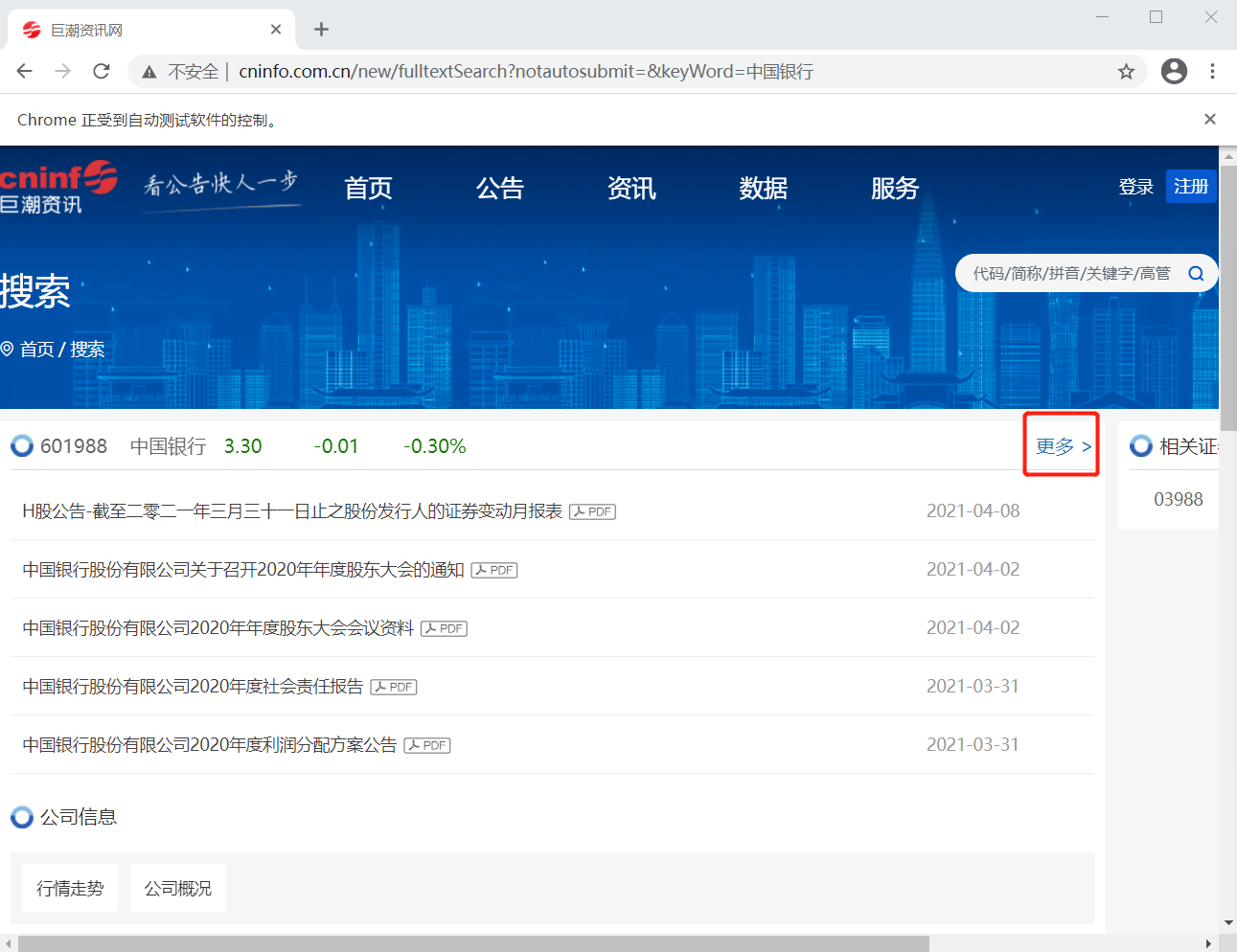
这里需要用xpath
# 使用爬虫来点击“更多”按钮
browser.find_element_by_xpath('//*[@id="fulltext-search"]/div/div[1]/div[1]/div[1]/span/a').click()
data = browser.page_source
之后页面发生跳转

第三步:查看共有多少页
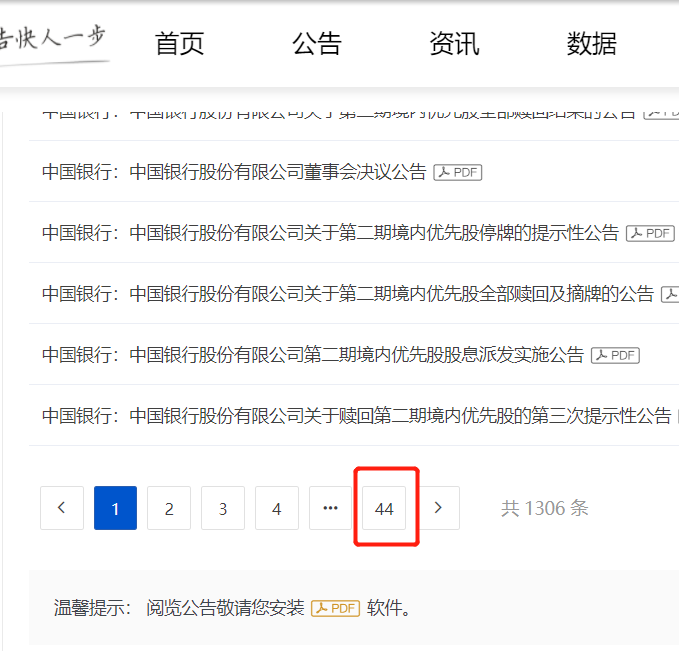
p_count = '<ul class="el-pager"><li class="number active">.*?</li><!----><li class="number">.*?</li><li class="number">.*?</li><li class="number">.*?</li><li class="el-icon more btn-quicknext el-icon-more"></li><li class="number">(.*?)</li></ul>'
count = re.findall(p_count,data)
print("共有的页数为:")
print(count[0])
结果:

第四步:点击下一步获取数据
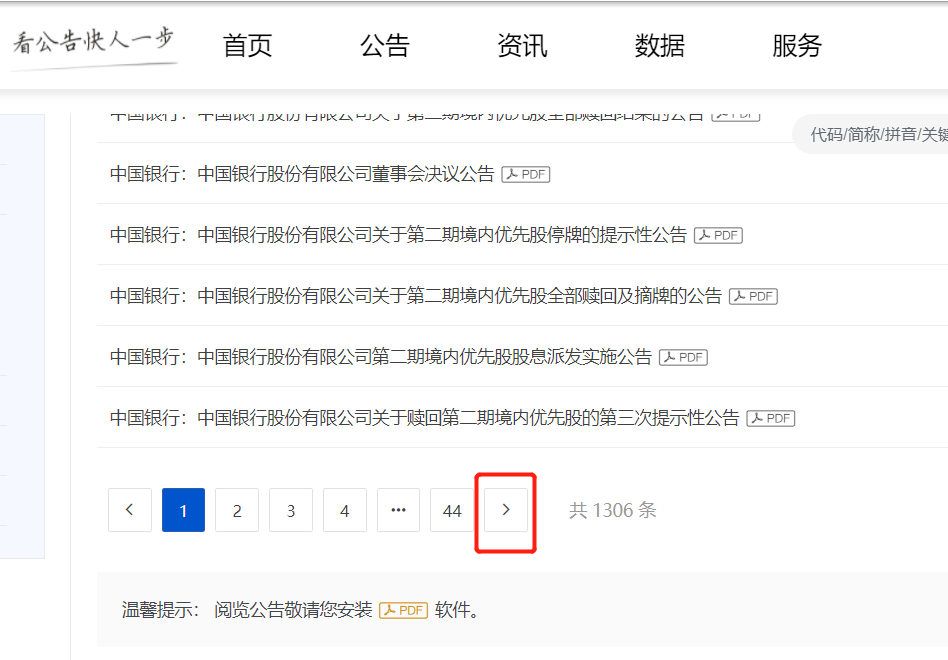
# 使用爬虫来点击“下一页”按钮
datas = []
datas.append(data)
for index in range(int(int(count[0])/10)):
browser.find_element_by_xpath('//*[@id="main"]/div[3]/div/div[2]/div/div/div[2]/div[1]/div[3]/div/div/button[2]').click()
time.sleep(3)
data = browser.page_source
datas.append(data)
time.sleep(3)
alldata = ''.join(datas)
页面会自动跳转。
第五步:提取关键信息
# 获取标题、网址、页数和时间信息数据 p_title = '<div class="cell"><a target="_blank" href=".*?" data-id=".*?" data-orgid=".*?" data-seccode=".*?" class="ahover"><span class="r-title">(.*?)</span> <span class="icon-f"><i class="iconfont iconnotice-PDF1"></i></span></a></div>' p_href = '<div class="cell"><a target="_blank" href="(.*?)" data-id=".*?" data-orgid=".*?" data-seccode=".*?" class="ahover"><span class="r-title">.*?</span> <span class="icon-f"><i class="iconfont iconnotice-PDF1"></i></span></a></div>' p_date = '<div class="cell"><a target="_blank" href=".*?&announcementTime=(.*?)" data-id=".*?" data-orgid=".*?" data-seccode=".*?" class="ahover"><span class="r-title">.*?</span> <span class="icon-f"><i class="iconfont iconnotice-PDF1"></i></span></a></div>' title = re.findall(p_title,alldata) href = re.findall(p_href,alldata) date = re.findall(p_date,alldata)
第六步:数据清洗
# 标题、网址、时间信息数据清洗
for index in range(len(title)):
title[index] = title[index]
href[index] = 'http://www.cninfo.com.cn' + href[index]
href[index] = re.sub('amp;','',href[index])
date[index] = date[index]
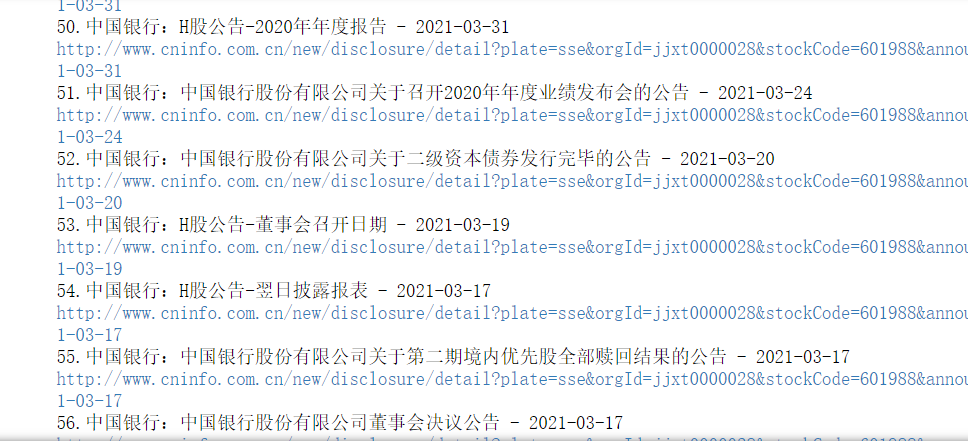
print(str(index + 1) + '.' + title[index] + ' - ' + date[index])
print(href[index])
第七步:下载文件
# 点击并下载文件
# 以第一个为例
browser.get(href[0])
time.sleep(10)
browser.find_element_by_xpath('//*[@id="noticeDetail"]/div/div[1]/div[3]/div[1]/button').click()
下载好了。