主要内容:
- 了解Flume
- Flume安装部署
- HDFS Sink
5.1 了解Flume
1) Flume概述
Flume是Cloudera提供的一个高可用,高可靠的,分布式的海量日志采集、聚合和传输的软件。
Flume的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,Flume再删除自己缓存的数据。
Flume支持定制各类数据发送方,用于收集各类型数据,同时,Flume支持定制各种数据接受方,用于最终存储数据。一般的采集需求,通过对Flume的简单配置即可实现。针对特殊场景也具备良好的自定义扩展能力。因此,Flume可以适用于大部分的日常数据采集场景。
当前Flume有两个版本。Flume的初始发行版本统称Flume OG(original generation),Flume1.X版本的统称Flume NG(next generation)。版本改动的原因是随着 Flume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.94中,日志传输不稳定的现象尤为严重。
Flume NG经过核心组件、核心配置以及代码架构重构,与Flume OG有很大不同,使用时请注意区分。改动的另一个原因是将Flume纳入Apache旗下,Cloudera Flume改名为Apache Flume。
2) Flume运行机制
Flume日志采集传输系统中核心的角色是agent,agent本身是一个Java进程,一般运行在日志收集节点,当然也可以运行在数据下沉的节点。 Source、Sink、Channel三个组件是Flume运行的核心。
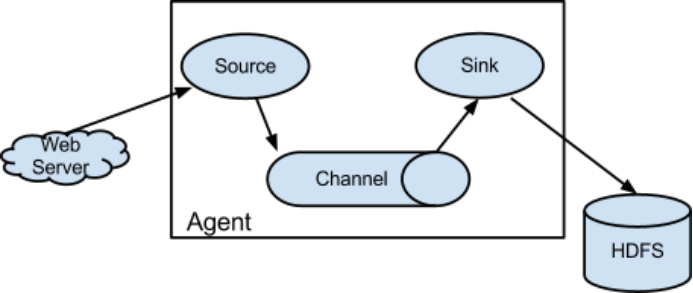
agent组件介绍:
每一个agent相当于一个数据传递员,内部三个组件的介绍:
Source:采集源,用于跟数据源对接,以获取数据;
Sink:下沉地,采集数据的传送目的地,用于往下一级agent传递数据或者往最终存储系统传递数据;
Channel:agent内部的数据传输通道,用于从source将数据传递到sink;
event介绍:
在整个数据的传输的过程中,流动的是event,它是Flume内部数据传输的最基本的单元。event将传输的数据进行封装。如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
一个完整的event包括:event headers、event body、event信息,其中event信息就是Flume收集到的日志记录。
3) Flume采集系统结构图
单个agent采集数据:
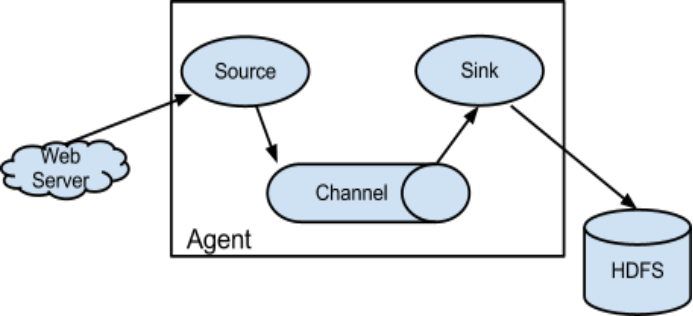
我们知道Flume一个很重要的功能就是应用于大数据环境中采集日志信息,那么对于分布式系统上面所讲的简单结构满足不了。所以有了复杂结构,比如在每一台服务器上都部署一个agent进程进行数据采集,再通过一个agent进程对所有采集到的数据进行汇总,并下沉到数据存储系统。这样使得Flume系统可以很方便地扩展。
多级agent之间串联:
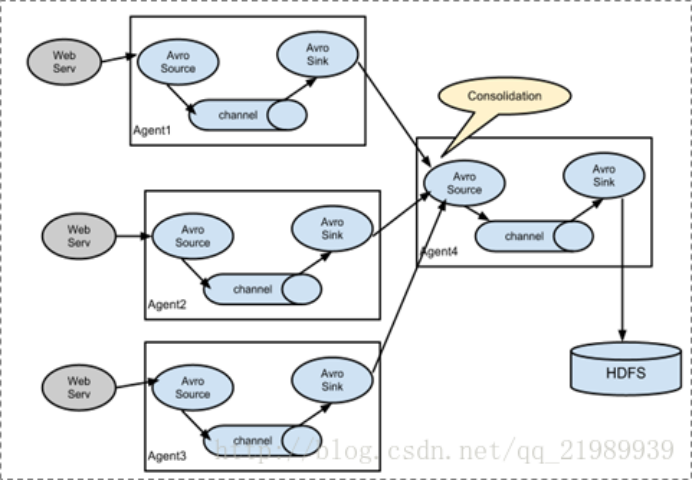
4) 官网介绍
http://flume.apache.org/
官网左边的菜单栏的documentation-> Flume User Guide,在页面左边菜单的Configuration下面我们可以看到Flume Sources、Flume Sinks、Flume Channels。这里所列举的数据源、下沉地和传输通道,基本上包含了大数据领域常用的软件,能满足大部分的需求(特殊情况下Flume也支持自定义)。
由此我们也可以知道,Flume使用的时候重点在于采集方案的配置。针对采集需求使用的是什么样的source、sink和channel,把服务配置好并启动起来,就可以进行数据采集、数据的传输和数据的下沉。
5.2 Flume安装和部署步骤介绍
5.2.1 Flume的安装
1) 上传安装包到数据源所在节点上,实际上不是数据源节点也是可以的,只要运行Flume的这台机器与数据源节点的这台机器能够通过某种协议进行通信即可。
2) 然后解压tar -zxvf apache-flume-1.8.0-bin.tar.gz,并修改(mv)文件名为flume
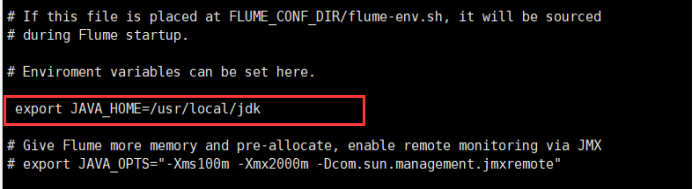
3) 然后进入flume的目录,修改conf下的flume-env.sh(没有的话复制(cp)flume-env.sh.template),在里面配置JAVA_HOME为jdk的根目录。
4) 根据数据采集需求配置采集方案,描述在配置文件中(文件名可任意自定义)
5) 指定采集方案配置文件,在相应的节点上启动flume agent
先用一个最简单的例子来测试一下程序环境是否正常。重点是体会一下Flume三个组件之间该怎么配置。
5.2.2 需求
往一个网络端口上发送数据,Flume监听该端口,将接收到的数据收集起来,并下沉到终端上以日志的形式打印出来。
5.2.3 配置采集方案
在flume的conf目录下新建一个文件:vi netcat-logger.conf (命名规则建议:source-sink.conf)
配置文件netcat-logger.conf参考内容:
#从网络端口接受数据,下沉到logger
#采集配置文件,netcat-logger.conf
#定义这个agent中各组件的名字
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#描述和配置source组件:r1
a1.sources.r1.type=netcat
a1.sources.r1.bind=localhost
a1.sources.r1.port=44444
#描述和配置sink组件:k1
a1.sinks.k1.type=logger
#描述和配置channel组件,此处使用是内存缓存的方式
a1.channels.c1.type=memory
# The maximum number of events stored in the channel
a1.channels.c1.capacity=1000
# The maximum number of events the channel will take from a source or give to a sink per transaction
a1.channels.c1.transactionCapacity=100
#描述和配置source channel sink之间的连接关系
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
5.2.4 启动agent采集数据
命令格式:
$ bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template
示例:
bin/flume-ng agent --conf conf --conf-file conf/netcat-logger.conf --name a1 -Dflume.root.logger=INFO,console
命令解释:
-c (或--conf) : flume自身所需的conf文件路径
-f (--conf-file) : 自定义的flume配置文件,也就是采集方案文件
-n (--name): 自定义的flume配置文件中agent的name
5.2.5 测试
先要往agent采集监听的端口上发送数据,让agent有数据可采。
随便在一个能跟agent节点联网的机器上,也可以在本机:
telnet agent-hostname port (如:telnet localhost 44444)
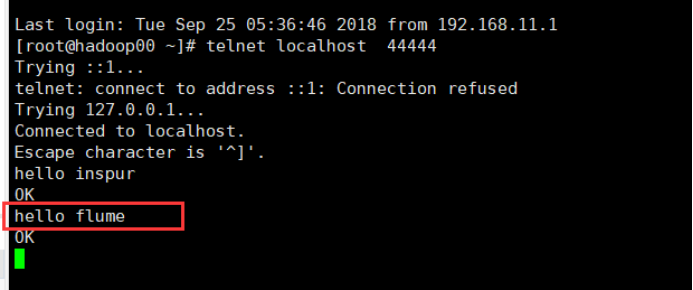

注意1:如果telnet还没有安装,则需要执行yum install -y telnet进行安装
telnet安装过程记录:
执行之前:
- 设置里面网络连接更改为vmnet8
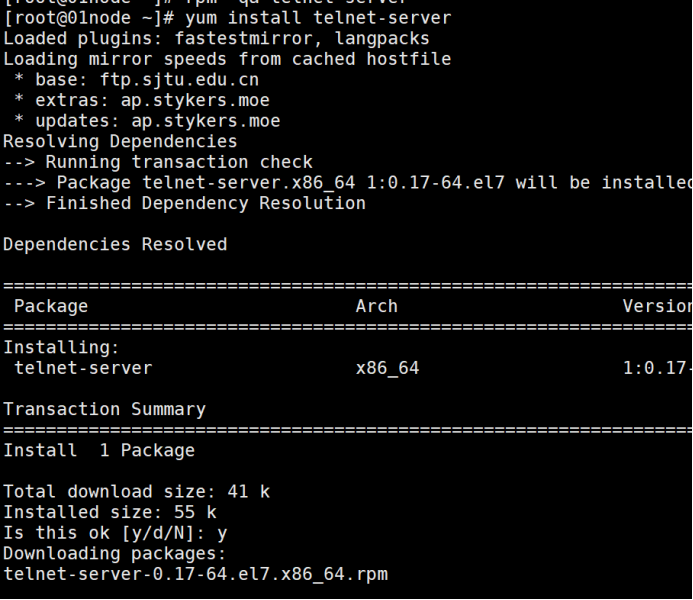
1、检测telnet-server的rpm包是否安装
# rpm -qa telnet-server
若无输出内容,则表示没有安装。如:

2、若未安装,则安装telnet-server,否则忽略此步骤
#yum install telnet-server
3、检测telnet的rpm包是否安装
# rpm -qa telnet
telnet-0.17-47.el6_3.1.x86_64

4、若未安装,则安装telnet,否则忽略此步骤
# yum install telnet
5、启动telnet服务
# systemctl start telnet.socket
6、设置开机启动
#chkconfig telnet on
注意2:如果telnet 127.0.0.1 44444能成功,而telnet localhost 44444不能成功,说明hosts文件内容需要补充。参考样式如下:
#vi /etc/hosts

5.3 HDFS Sink
This sink writes events into the Hadoop Distributed File System (HDFS). It currently supports creating text and sequence files. It supports compression in both file types. The files can be rolled (close current file and create a new one) periodically based on the elapsed time or size of data or number of events. It also buckets/partitions data by attributes like timestamp or machine where the event originated. The HDFS directory path may contain formatting escape sequences that will replaced by the HDFS sink to generate a directory/file name to store the events. Using this sink requires hadoop to be installed so that Flume can use the Hadoop jars to communicate with the HDFS cluster. Note that a version of Hadoop that supports the sync() call is required.
Example for agent named a1:
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
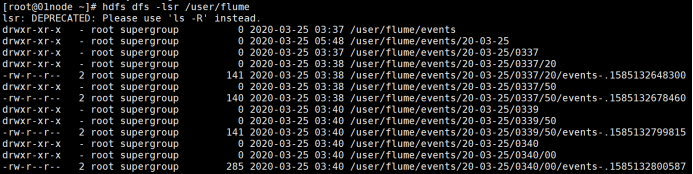
在hdfs中创建文件夹用于采集日志的存放:
hdfs查看文件目录:
#hdfs dfs -lsr /
创建文件夹:
hdfs dfs -mkdir /user/flume
创建配置文件netcat-hdfs.conf,参考内容如下:
#从网络端口接受数据,下沉到hdfs
#采集配置文件,netcat- hdfs.conf
#定义这个agent中各组件的名字
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#描述和配置source组件:r1
a1.sources.r1.type=netcat
a1.sources.r1.bind=localhost
a1.sources.r1.port=44444
#描述和配置sink组件:k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /user/flume/events/%y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = second
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#描述和配置channel组件,此处使用是内存缓存的方式
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#描述和配置source channel sink之间的连接关系
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
flume文件夹下启动:
bin/flume-ng agent --conf conf --conf-file conf/netcat-hdfs.conf --name a1
另开一个窗口:
#telnet localhost 44444
随便输入一些信息
查看对应hdfs文件信息:
#hdfs dfs -lsr /user/flume