下载与安装
分pivotal greenplum版本与开源版本。
6.x版本基于postgresql 9.4.24,相比9.6、10、12,在PG本身易管理性、自治能力方面差异还是非常大的。
mydb=# select name,setting from pg_settings where name like '%version%'; name | setting ------------------------------------+-------------------------------------------------------------- gp_server_version | 6.14.1 build commit:5ef30dd4c9878abadc0124e0761e4b988455a4bd gp_server_version_num | 60000 gpcc.metrics_collector_pkt_version | 10 server_version | 9.4.24 server_version_num | 90424 (5 rows)
安装可以参考https://www.jianshu.com/p/513935550350。
源码安装后修改密码、gp也必须:alter role gpadmin with password 'bigdata2018';gpstart #正常启动
gpstop #正常关闭
gpstop -M fast #快速关闭
gpstop –r #重启
gpstop –u #重新加载配置 注意事项
- 内核参数修改。kernel.sem是一定要修改足够大的,如果安装了oracle的话,需要更大。例如kernel.sem=250 512000 100 2048,否则会初始化失败。
- SSH设置。LZ在第二台机器安装的时候,出现“localhost: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).",网上搜索,有个hadoop的也遇到该问题,解释是“原因是秘钥没有给自己,运行ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@localhost即可解决。”,但是LZ发现不生效,说明不是该原因。该问题还得后面看下,不过不影响安装,只是会后面不停的提示输入gpadmin的密码。
- NTP服务安装。
初始化失败后重新初始化
只要删除/home/gpdata目录下的master/gpX/gpAdminLogs三个文件夹,然后重新执行即可。
数据导入与导出
一、数据导入
greenplum数据导入有五种方式:
1. insert:通过sql直接插入数据
2. copy:通过master节点加载,无法实现并行高效数据加载
copy tablename from '/home/../test.cvs' with delimiter ',';
copy tablename from '/home/../test.cvs' with CSV; # 比前者更好用
export PGPASSWORD=postgres
./psql -h localhost -p 5432 -d postgres -U postgres -c "\\copy ta_tsharecurrents FROM '/disk01/sharecurrents.csv' with CSV"
./psql -h localhost -p 5432 -d postgres -U postgres -c "\\copy ta_tcustomerinfo FROM '/disk01/TA_TCUSTOMERINFO.csv' with CSV"
./psql -h localhost -p 5432 -d postgres -U postgres -c "\\copy ta_tnetvalueday FROM '/disk01/TA_TNETVALUEDAY.csv' with CSV"
./psql -h localhost -p 5432 -d postgres -U postgres -c "\\copy ta_tnetinfo FROM '/disk01/TA_TNETINFO.csv' with CSV"
./psql -h localhost -p 5432 -d postgres -U postgres -c "\\copy ta_tagencyinfo FROM '/disk01/TA_TAGENCYINFO.csv' with CSV"
./psql -h localhost -p 5432 -d postgres -U postgres -c "\\copy ta_tfundinfo FROM '/disk01/ta_tfundinfo.csv' with CSV"
./psql -h localhost -p 5432 -d postgres -U postgres -c "\\copy ta_taccoinfo FROM '/disk01/TA_TACCOINFO.csv' with CSV"
3. 外部表:
创建外部表,然后插入数据。这种还可以依赖gpfdist服务更快导入。
4. gpload:外部表的封装
通过编辑gpload控制文件test.yml完成导入
gpload -f test.yml
5. 可执行外部表:不需要启动gpfdist服务
create external web table test1(..)
execute 'cat /home/../test.dat' on master
format 'text' (delimiter ',' null as '' escape 'off')
encoding '';
insert into test select * from test1;
数据导出:
1、copy命令导出
2、可写外部表导出数据:
create writable external table test1
(like test)
location ('gpfdist://localhost:8888/test.dat')
format 'text' (delimiter ',')
distribute by ..;
insert into test1 select * from test;
3、通过 pg_dump导出
pg_dump -f basicmod.sql -h hostname -U username -s -n schema_name db_name # -s 代表只导出schema元信息,不包括数据
参数优化
show all或show 参数名 查询当前设置。
既可以通过命令,也可以直接修改conf的方式进行。
gpconfig -c shared_buffers -v 1536MB
vim /home/gpdata/master/gpseg-1/postgresql.conf
有些需要重启(shared_buffers),有些则只要执行gpstop -u重新加载配置()即可(跟nginx类似)。
场景测试
a,b表的c_fundacco、f_lastshares都创建了b树索引,但是gp几乎不会选择索引。
-- 3.3秒(LightDB-X不带索引 1.5秒,带索引0.00x秒)
select * from ta_tsharecurrents a where a.f_lastshares > 100
order by a.f_lastshares desc
limit 100;
-- 13秒(LightDB-X不带索引 2秒,带索引0.3秒)
select * from ta_tsharecurrents a where a.f_lastshares > 100
order by a.f_lastshares desc
limit 100 offset 1000000;
-- 0.0x秒
select * from ta_tsharecurrents a where a.f_lastshares > 100
order by a.f_lastshares
limit 100;
-- 1.2秒
select * from ta_tsharecurrents a where a.f_lastshares > 100
order by a.f_lastshares
limit 100 offset 1000000;
-- 75秒(LightDB-X从0.00x-10秒,无论offset从哪里开始,见下文) select * from ta_tsharecurrents a,ta_tcustomerinfo b where a.c_fundacco = b.c_fundacco and a.f_lastshares > 100 order by a.f_lastshares desc limit 100; -- 75秒 select * from ta_tsharecurrents a,ta_tcustomerinfo b where a.c_fundacco = b.c_fundacco and a.f_lastshares > 100 order by a.c_fundacco limit 100;
-- 原生pg offset 15%以下走nestloop, 15%以上走hash join,性能最优化,0.00x-10秒之间,需要AOP动态判断 select * from ta_tsharecurrents a,ta_tcustomerinfo b where a.c_fundacco = b.c_fundacco and a.f_lastshares > 100 order by a.f_lastshares desc LIMIT 100 offset 500000;
-- 15秒(LightDB-X 10.10 14秒, 11.5 12.5秒,oracle 9秒) SELECT a.c_fundcode, SUM(a.f_lastshares) AS f_lastshares, COUNT(*) fundaccoCount, a.c_tacode, a.c_tenantid FROM (SELECT -- a.c_fundacco, -- a.c_tradeacco, a.c_fundcode, -- a.c_sharetype, -- a.c_agencyno, -- a.c_netno, a.c_tacode, a.c_tenantid, a.f_lastshares -- a.c_shrcrtserailno FROM ta_tsharecurrents a, (SELECT CAST(SUBSTR(MAX(CONCAT(d_cdate, c_shrcrtserailno)), 9) AS BIGINT) c_shrcrtserailno FROM ta_tsharecurrents a WHERE a.d_cdate <= 20190103 AND a.c_tacode = 'F6' AND a.c_tenantid = '*' GROUP BY c_fundacco, c_tradeacco, c_fundcode, c_sharetype, c_agencyno, c_netno) b WHERE a.d_cdate <= 20190103 AND a.c_tacode = 'F6' AND a.c_tenantid = '*' AND a.c_shrcrtserailno = b.c_shrcrtserailno AND a.f_lastshares > 0) a LEFT JOIN (SELECT a.* FROM (SELECT c_fundcode, c_gradefund, c_tacode, c_tenantid FROM (SELECT a.c_fundcode, COALESCE(mc.c_gradefund, COALESCE(sc.c_gradefund, COALESCE(ss.c_fundcode, NULL))) c_gradefund, a.c_managercode, a.c_tacode, a.c_tenantid FROM ta_tfundinfo a LEFT JOIN ta_tmergercontrol mc ON mc.c_fundcode = a.c_fundcode AND mc.c_type = '0' AND mc.c_tenantid = a.c_tenantid LEFT JOIN ta_tshareclass sc ON sc.c_fundcode = a.c_fundcode AND sc.c_tenantid = a.c_tenantid LEFT JOIN (SELECT a.c_projectid, fi.c_fundcode, a.c_tenantid, a.c_tacode FROM ta_tstructuredschema a, ta_tfundinfo fi WHERE POSITION(fi.c_fundcode in a.c_fundcodelist) > 0 AND fi.c_tenantid = a.c_tenantid AND a.c_tacode = 'F6' AND a.c_tenantid = '*') ss ON ss.c_projectid = a.c_fundcode AND ss.c_tenantid = a.c_tenantid WHERE 1 = 1 AND a.c_tacode = 'F6' AND a.c_tenantid = '*' UNION ALL SELECT c_fundcode, c_fundcode c_gradefund, c_managercode, c_tacode, c_tenantid FROM ta_tfundinfo a WHERE 1 = 1 AND a.c_tacode = 'F6' AND a.c_tenantid = '*') a WHERE a.c_gradefund IS NOT NULL GROUP BY c_fundcode, c_gradefund, c_tacode, c_tenantid) a, (SELECT fundcode FROM role_fundcode WHERE role_id IN (1) GROUP BY fundcode) rf WHERE a.c_fundcode = rf.fundcode) b ON b.c_gradefund = a.c_fundcode AND b.c_tenantid = a.c_tenantid GROUP BY a.c_fundcode, a.c_tacode, a.c_tenantid;
-- 56秒(LightDB-X 10.10可以稳定在40秒,11.5 35秒内,oracle非并行40秒,并行30秒) SELECT tsc.c_fundacco, tsc.c_tradeacco, tsc.c_fundcode, g.c_fundname fundname, tsc.c_sharetype, CASE WHEN ai.c_agencyname IS NULL THEN tsc.c_agencyno WHEN ai.c_agencyname = '' THEN tsc.c_agencyno ELSE ai.c_agencyname END AS c_agencyno, CASE WHEN ni.c_netname IS NULL THEN tsc.c_netno WHEN ni.c_netname = '' THEN tsc.c_netno ELSE ni.c_netname END AS c_netno, tsc.c_tacode, tsc.d_cdate, tsc.c_bonustype, tsc.d_cdate d_lastmodify, tsc.c_custtype, tsc.c_custtype old_c_custtype, COALESCE(tsc.f_lastshares, 0) f_realshares, ROUND( COALESCE(tsc.f_lastshares, 0) * COALESCE(E.f_netvalue, 1), 2 ) f_realvalue, COALESCE(tsc.f_lastfreezeshares, 0) f_frozenshares, ROUND( COALESCE(tsc.f_lastfreezeshares, 0) * COALESCE(E.f_netvalue, 1), 2 ) + 0 f_frozenvalue, 0 f_income, 0 f_frozenincome, 0 f_protectbalance, 0 f_newincome, '' c_invested, tai.c_custname, tai.c_identitype, tai.c_identityno, tai.c_accostatus, tci.c_sex, tci.c_contact, tci.c_address, tci.c_zipcode, tci.c_phone, tci.c_mobileno, tci.c_faxno, tci.c_email, tci.c_vocation FROM (SELECT a.c_fundacco, a.c_tradeacco, a.c_fundcode, a.c_sharetype, a.c_agencyno, a.c_netno, a.c_tacode, a.c_tenantid, CAST(a.c_shrcrtserailno AS INT) c_shrcrtserailno, a.d_cdate, a.f_lastshares, a.f_lastfreezeshares, a.c_bonustype, a.c_custtype FROM ta_tsharecurrents a, (SELECT CAST(SUBSTR( MAX(CONCAT(d_cdate, c_shrcrtserailno)), 9 ) AS int) c_shrcrtserailno /* c_fundacco, c_tradeacco, c_fundcode, c_sharetype, c_agencyno, c_netno */ FROM ta_tsharecurrents a WHERE a.d_cdate <= 20200212 AND a.c_tacode = 'F6' -- AND a.c_tenantid = '*' GROUP BY c_fundacco, c_tradeacco, c_fundcode, c_sharetype, c_agencyno, c_netno) b WHERE /*a.c_fundacco = b.c_fundacco AND a.c_tradeacco = b.c_tradeacco AND a.c_fundcode = b.c_fundcode AND a.c_sharetype = b.c_sharetype AND a.c_agencyno = b.c_agencyno AND a.c_netno = b.c_netno AND*/ a.d_cdate <= 20200212 AND a.c_tacode = 'F6' -- AND a.c_tenantid = '*' AND a.c_shrcrtserailno = b.c_shrcrtserailno) tsc LEFT JOIN ta_tagencyinfo ai ON ai.c_agencyno = tsc.c_agencyno AND ai.c_tenantid = tsc.c_tenantid AND ai.c_tacode = tsc.c_tacode LEFT JOIN ta_tnetinfo ni ON ni.c_netno = tsc.c_netno AND ni.c_agencyno = tsc.c_agencyno AND ni.c_tenantid = tsc.c_tenantid AND ni.c_tacode = tsc.c_tacode, (SELECT a.f_netvalue, a.c_fundcode, a.c_tacode, a.c_tenantid FROM ta_tnetvalueday a, (SELECT MAX(a.d_cdate) d_cdate, c_fundcode FROM ta_tnetvalueday a WHERE a.d_netvaluedate <= 20200212 AND a.c_tacode = 'F6' -- AND a.c_tenantid = '*' GROUP BY c_fundcode) b WHERE a.c_fundcode = b.c_fundcode AND a.d_cdate = b.d_cdate AND a.c_tacode = 'F6' -- AND a.c_tenantid = '*' ) E, ta_taccoinfo tai, ta_tcustomerinfo tci, ta_tfundinfo g WHERE tsc.c_fundacco = tai.c_fundacco -- AND tsc.c_tenantid = tai.c_tenantid AND tsc.c_fundacco = tci.c_fundacco -- AND tsc.c_tenantid = tci.c_tenantid AND tsc.c_fundcode = g.c_fundcode -- AND tsc.c_tenantid = g.c_tenantid AND tsc.c_fundcode = E.c_fundcode AND tsc.c_tacode = E.c_tacode -- AND tsc.c_tenantid = E.c_tenantid AND tsc.c_tacode = 'F6' -- AND tsc.c_tenantid = '*' ORDER BY d_cdate LIMIT 100 OFFSET 1000000;
查看所有gp参数
b=# select name,setting from pg_settings where name like 'gp%' or name like 'optimizer%'; name | setting ------------------------------------------------------+---------------------------------------------------------------------------------- gp_adjust_selectivity_for_outerjoins | on gp_appendonly_compaction_threshold | 10 gp_autostats_mode | on_no_stats gp_autostats_mode_in_functions | none gp_autostats_on_change_threshold | 2147483647 gp_cached_segworkers_threshold | 5 gp_command_count | 45 gp_connection_send_timeout | 3600 gp_contentid | -1 gp_create_table_random_default_distribution | off gp_dbid | 1 gp_debug_linger | 0 gp_default_storage_options | appendonly=false,blocksize=32768,compresstype=none,checksum=true,orientation=row gp_dtx_recovery_interval | 60 gp_dtx_recovery_prepared_period | 120 gp_dynamic_partition_pruning | on gp_enable_agg_distinct | on gp_enable_agg_distinct_pruning | on gp_enable_direct_dispatch | on gp_enable_exchange_default_partition | off gp_enable_fast_sri | on gp_enable_global_deadlock_detector | off gp_enable_gpperfmon | off gp_enable_groupext_distinct_gather | on gp_enable_groupext_distinct_pruning | on gp_enable_minmax_optimization | on gp_enable_multiphase_agg | on gp_enable_predicate_propagation | on gp_enable_preunique | on gp_enable_query_metrics | on gp_enable_relsize_collection | off gp_enable_sort_distinct | on gp_enable_sort_limit | on gp_external_enable_exec | on gp_external_enable_filter_pushdown | on gp_external_max_segs | 64 gp_fts_mark_mirror_down_grace_period | 30 gp_fts_probe_interval | 60 gp_fts_probe_retries | 5 gp_fts_probe_timeout | 20 gp_fts_replication_attempt_count | 10 gp_global_deadlock_detector_period | 120 gp_gpperfmon_send_interval | 1 gp_hashjoin_tuples_per_bucket | 5 gp_initial_bad_row_limit | 1000 gp_instrument_shmem_size | 5120 gp_interconnect_cache_future_packets | on gp_interconnect_debug_retry_interval | 10 gp_interconnect_default_rtt | 20 gp_interconnect_fc_method | loss gp_interconnect_min_retries_before_timeout | 100 gp_interconnect_min_rto | 20 gp_interconnect_queue_depth | 4 gp_interconnect_setup_timeout | 7200 gp_interconnect_snd_queue_depth | 2 gp_interconnect_tcp_listener_backlog | 128 gp_interconnect_timer_checking_period | 20 gp_interconnect_timer_period | 5 gp_interconnect_transmit_timeout | 3600 gp_interconnect_type | udpifc gp_log_format | csv gp_max_local_distributed_cache | 1024 gp_max_packet_size | 8192 gp_max_partition_level | 0 gp_max_plan_size | 0 gp_max_slices | 0 gp_motion_cost_per_row | 0 gp_reject_percent_threshold | 300 gp_reraise_signal | on gp_resgroup_memory_policy | eager_free gp_resource_group_bypass | off gp_resource_group_cpu_limit | 0.9 gp_resource_group_cpu_priority | 10 gp_resource_group_memory_limit | 0.7 gp_resource_group_queuing_timeout | 0 gp_resource_manager | queue gp_resqueue_memory_policy | eager_free gp_resqueue_priority | on gp_resqueue_priority_cpucores_per_segment | 4 gp_resqueue_priority_sweeper_interval | 1000 gp_role | dispatch gp_safefswritesize | 0 gp_segment_connect_timeout | 600 gp_segments_for_planner | 0 gp_server_version | 6.14.1 build commit:5ef30dd4c9878abadc0124e0761e4b988455a4bd gp_server_version_num | 60000 gp_session_id | 689404 gp_set_proc_affinity | off gp_statistics_pullup_from_child_partition | on gp_statistics_use_fkeys | on gp_subtrans_warn_limit | 16777216 gp_udp_bufsize_k | 0 gp_vmem_idle_resource_timeout | 18000 gp_vmem_protect_limit | 8192 gp_vmem_protect_segworker_cache_limit | 500 gp_workfile_compression | off gp_workfile_limit_files_per_query | 100000 gp_workfile_limit_per_query | 0 gp_workfile_limit_per_segment | 0 gpcc.enable_query_profiling | off gpcc.enable_send_query_info | on gpcc.metrics_collector_pkt_version | 10 gpperfmon_log_alert_level | none gpperfmon_port | 8888 optimizer | on optimizer_analyze_root_partition | on optimizer_control | on optimizer_enable_associativity | off optimizer_join_arity_for_associativity_commutativity | 18 optimizer_join_order | exhaustive2 optimizer_join_order_threshold | 10 optimizer_mdcache_size | 16384 optimizer_metadata_caching | on optimizer_minidump | onerror optimizer_parallel_union | off (115 rows)
相关的问题
如帖子https://bbs.csdn.net/topics/392336025?page=1所述,greenplum在一简单查询语句上性能远低于postgrelSQL或LightDB-X。实际在于它没有走索引,以至于最简单的select * from table order by index_col limit 100都要20秒。
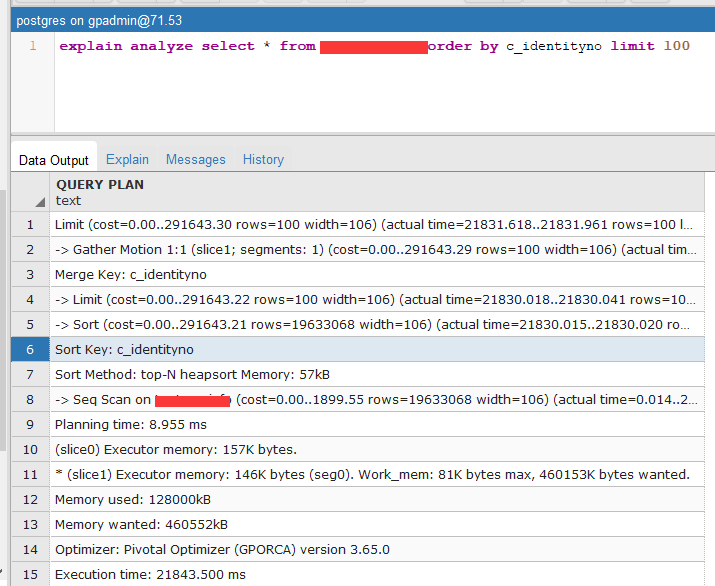
于是搜索了pg相关的分页查询机制,如下:
GP的limit offset子句对查询的作用 当offset很大时,不管有没有order by子句,都需要将数据传输到master进行处理 观察发现,语句开始执行时,segment的cpu使用率冲高,随后net输出冲高,master的net输入冲高 然后master的cpu冲高,此时segment的cpu复原 说明这个处理过程是: segment准备数据-》发送给master-》master获取数据并丢弃offset部分-》返回limit部分 而且即便offset大于全表数据量仍执行以上过程 当offset过亿(当然数据量也过亿了)处理时间就要达到百秒量级了 按照我的想法,GP完全可以考虑更优化的算法充分发挥segment的资源,让offset更多的在segment完成 目前只有避免这种超大的offset子句,期待GP以后优化该算法
执行计划分析
explain
explain analyze
TPC-H测试
https://blog.csdn.net/xfg0218/article/details/82785187
TPC-DS测试
待补充。
结论
综上所述,对于即席查询(即TPC-DS、分页查询),LightDB Enterprise Postgres比Greenplum更合适。Greenplum列存更适合作为报表查询。