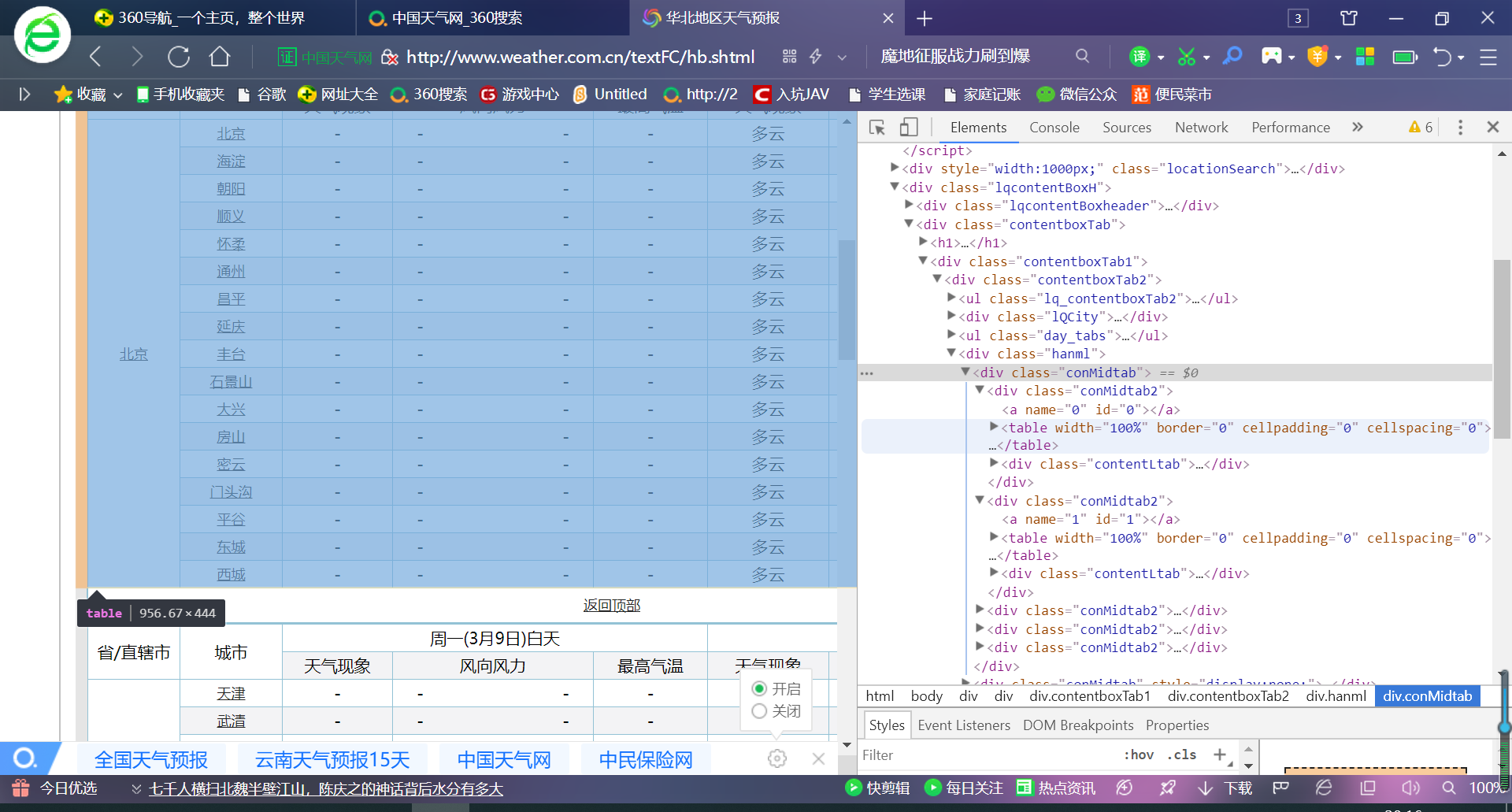
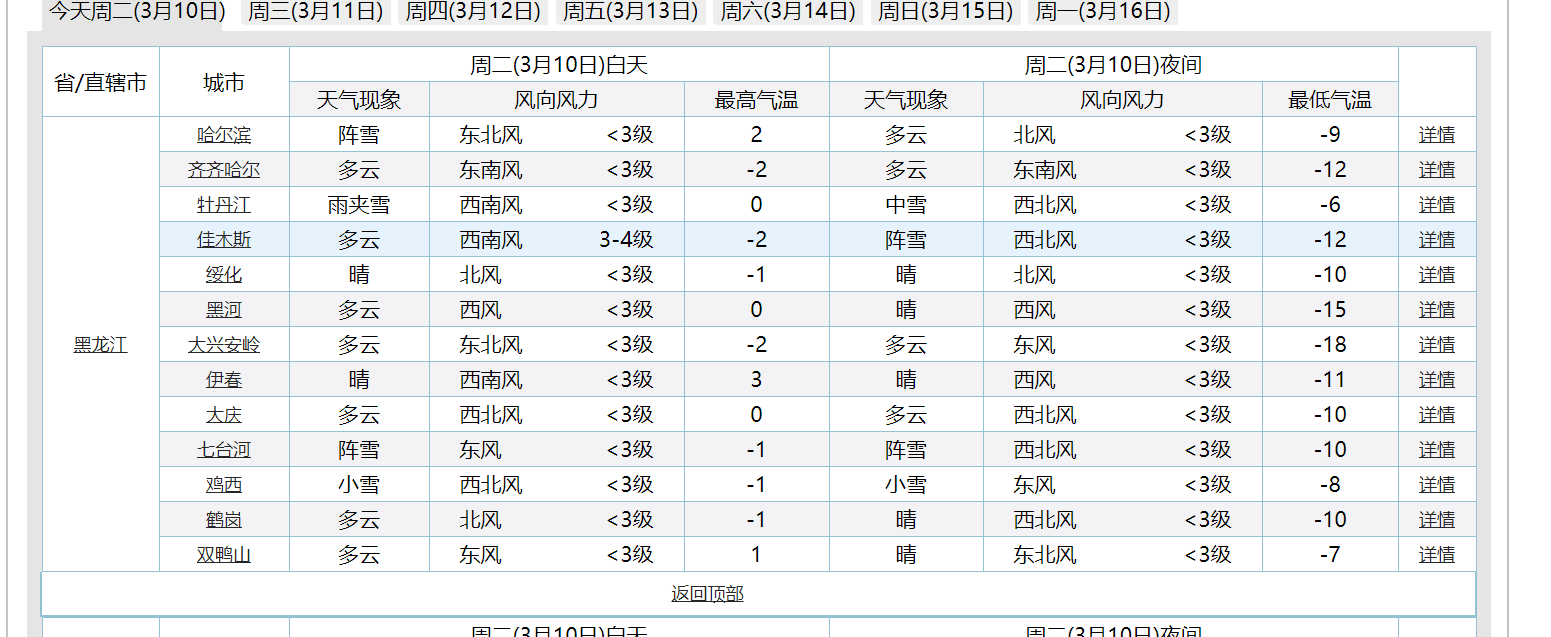
网页如图所示
1、页面分析

首先爬取华北地区
华北得url:http://www.weather.com.cn/textFC/hb.shtml
东北得url:http://www.weather.com.cn/textFC/db.shtml
依次很容易得到各个地区得url
一个城市得情况在一个table里

table里得第三个tr标签开始为这个城市得天气情况
2、华北城市数据爬取
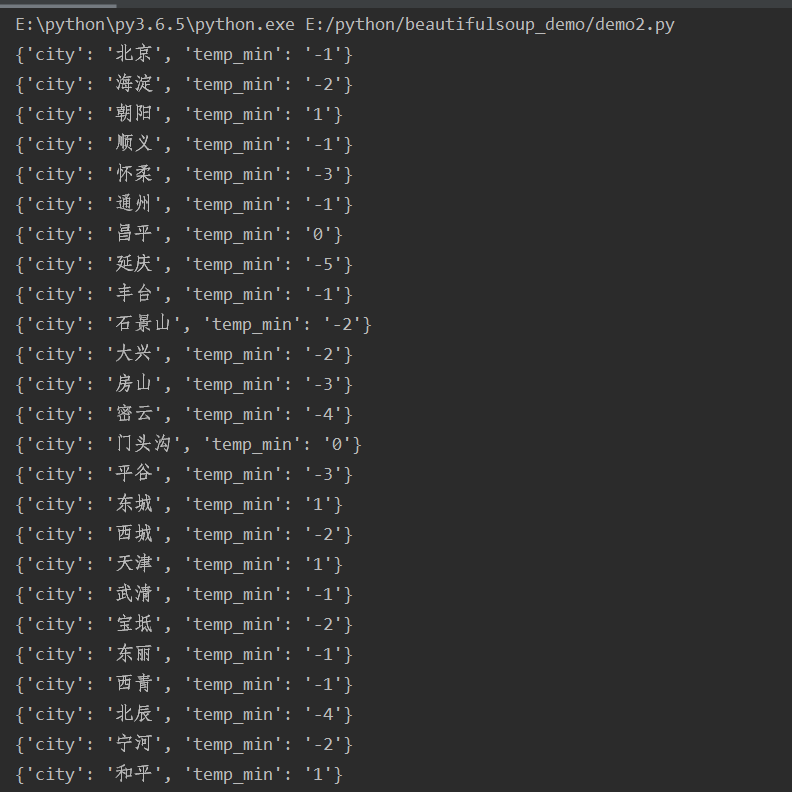
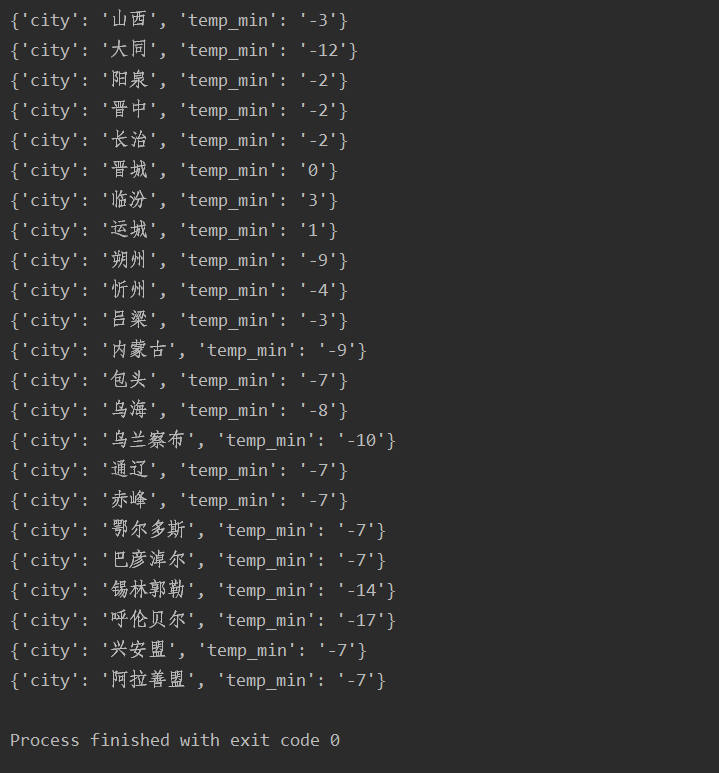
import requests from bs4 import BeautifulSoup def parse_page(url): headers={ 'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36" } response=requests.get(url,headers=headers) text=response.content.decode('utf-8') soup=BeautifulSoup(text,'lxml') conMidtab=soup.find('div',class_='conMidtab') tables=conMidtab.find_all('table') for table in tables: trs=table.find_all('tr')[2:] for tr in trs: tds=tr.find_all('td') city_td=tds[0] city=list(city_td.stripped_strings)[0] temp_td=tds[-2] temp_min=list(temp_td.stripped_strings)[0] print({"city":city,"temp_min":temp_min}) def main(): url="http://www.weather.com.cn/textFC/hb.shtml" parse_page(url) if __name__ == '__main__': main()
华北地区的所有最低气温:
3、所有城市最低气温爬取
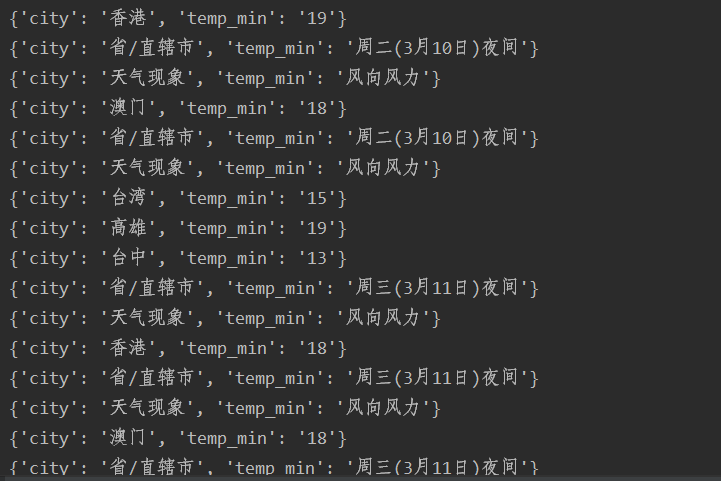
在测试时可以发现,除了华北和港澳台地区,其他地区的城市信息例如:
在华北地区的时候,第一个城市在第三个tr标签,城市的名字在tr标签下的第一个td标签,但是在这几个地区,第一个城市在第三个tr标签,而城市的名字在tr标签下的第二个td标签
这时需要加上几行代码
city_td=tds[0] # 如果是第0个tr标签,城市就是第二个td标签,其余得都选第0个td标签 if index==0: city_td = tds[1]
然后是港澳台,通过查看源代码可以看出来,港澳台里面是不规范的html代码,即有开始标签没有结束标签,如果按照上面的方式写,得到的是不正确的
这时就不能用lxml解析器,需要用html5lib解析器
soup=BeautifulSoup(text,'html5lib')
如果没有安装,通过命令 pip install html5lib 安装
import requests from bs4 import BeautifulSoup def parse_page(url): headers={ 'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36" } response=requests.get(url,headers=headers) text=response.content.decode('utf-8') soup=BeautifulSoup(text,'html5lib') conMidtab=soup.find('div',class_='conMidtab') tables=conMidtab.find_all('table') for table in tables: trs=table.find_all('tr')[2:] for index,tr in enumerate(trs): tds=tr.find_all('td') city_td=tds[0] # 如果是第0个tr标签,城市就是第二个td标签,其余得都选第0个td标签 if index==0: city_td = tds[1] city=list(city_td.stripped_strings)[0] temp_td=tds[-2] temp_min=list(temp_td.stripped_strings)[0] print({"city":city,"temp_min":temp_min}) def main(): urls={ 'http://www.weather.com.cn/textFC/hb.shtml', 'http://www.weather.com.cn/textFC/db.shtml', 'http://www.weather.com.cn/textFC/hd.shtml', 'http://www.weather.com.cn/textFC/hz.shtml', 'http://www.weather.com.cn/textFC/hn.shtml', 'http://www.weather.com.cn/textFC/xb.shtml', 'http://www.weather.com.cn/textFC/xn.shtml', 'http://www.weather.com.cn/textFC/gat.shtml' } for url in urls: parse_page(url) if __name__ == '__main__': main()
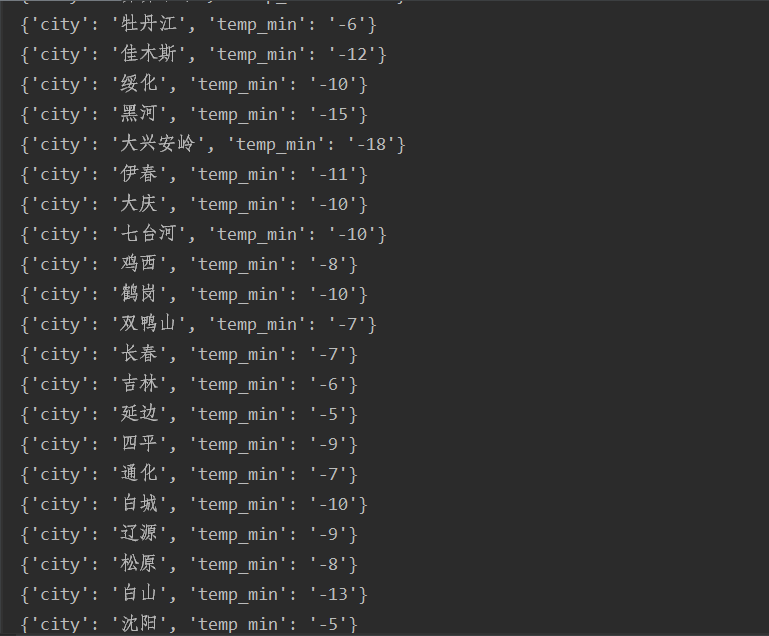
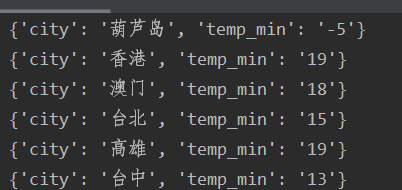
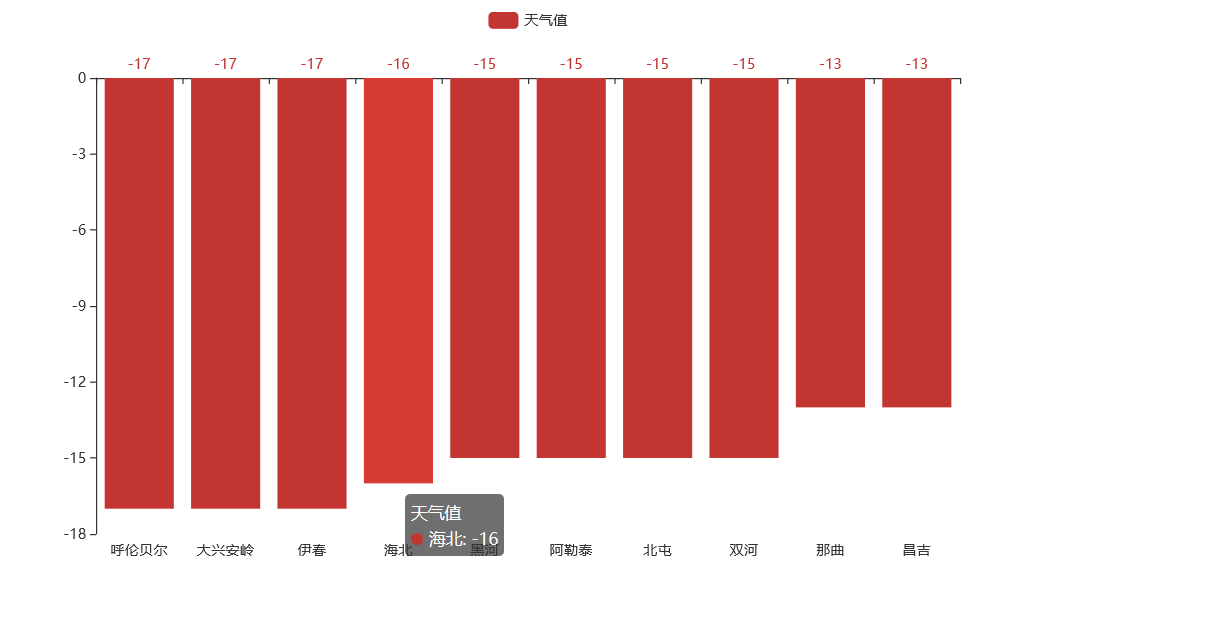
4、全国前十最低气温可视化
import requests from bs4 import BeautifulSoup from pyecharts.charts import Bar ALL_DATA=[] def parse_page(url): headers={ 'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36" } response=requests.get(url,headers=headers) text=response.content.decode('utf-8') soup=BeautifulSoup(text,'html5lib') conMidtab=soup.find('div',class_='conMidtab') tables=conMidtab.find_all('table') for table in tables: trs=table.find_all('tr')[2:] for index,tr in enumerate(trs): tds=tr.find_all('td') city_td=tds[0] # 如果是第0个tr标签,城市就是第二个td标签,其余得都选第0个td标签 if index==0: city_td = tds[1] city=list(city_td.stripped_strings)[0] temp_td=tds[-2] temp_min=list(temp_td.stripped_strings)[0] ALL_DATA.append({"city":city,"temp_min":int(temp_min)}) # print({"city":city,"temp_min":int(temp_min)}) def main(): urls={ 'http://www.weather.com.cn/textFC/hb.shtml', 'http://www.weather.com.cn/textFC/db.shtml', 'http://www.weather.com.cn/textFC/hd.shtml', 'http://www.weather.com.cn/textFC/hz.shtml', 'http://www.weather.com.cn/textFC/hn.shtml', 'http://www.weather.com.cn/textFC/xb.shtml', 'http://www.weather.com.cn/textFC/xn.shtml', 'http://www.weather.com.cn/textFC/gat.shtml' } for url in urls: parse_page(url) ALL_DATA.sort(key=lambda data:data['temp_min']) data=ALL_DATA[0:10] # 需要使用pyecharts cities=list(map(lambda x:x['city'],data)) temps=list(map(lambda x:x['temp_min'],data)) chart=Bar("中国气温排行榜") chart.add('',cities,temps) chart.render('temperature.html') if __name__ == '__main__': main()