什么是进程?
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。
第一,进程是一个实体。每一个进程都有它自己的地址空间,一般情况下,包括文本区域(text region)、数据区域(data region)
和堆栈(stack region)。文本区域存储处理器执行的代码;数据区域存储变量和进程执行期间使用的动态分配的内存;堆栈区域存储着活动过程调用的指令和本地变量。 第二,进程是一个“执行中的程序”。程序是一个没有生命的实体,只有处理器赋予程序生命时(操作系统执行之),它才能成为一个活动的实体,我们称其为进程。[3] 进程是操作系统中最基本、重要的概念。是多道程序系统出现后,为了刻画系统内部出现的动态情况,描述系统内部各道程序的活动规律引进的一个概念,
所有多道程序设计操作系统都建立在进程的基础上。
从理论角度看,是对正在运行的程序过程的抽象; 从实现角度看,是一种数据结构,目的在于清晰地刻画动态系统的内在规律,有效管理和调度进入计算机系统主存储器运行的程序。
动态性:进程的实质是程序在多道程序系统中的一次执行过程,进程是动态产生,动态消亡的。 并发性:任何进程都可以同其他进程一起并发执行 独立性:进程是一个能独立运行的基本单位,同时也是系统分配资源和调度的独立单位; 异步性:由于进程间的相互制约,使进程具有执行的间断性,即进程按各自独立的、不可预知的速度向前推进 结构特征:进程由程序、数据和进程控制块三部分组成。 多个不同的进程可以包含相同的程序:一个程序在不同的数据集里就构成不同的进程,能得到不同的结果;但是执行过程中,程序不能发生改变。
程序是指令和数据的有序集合,其本身没有任何运行的含义,是一个静态的概念。 而进程是程序在处理机上的一次执行过程,它是一个动态的概念。 程序可以作为一种软件资料长期存在,而进程是有一定生命期的。 程序是永久的,进程是暂时的。
注意:同一个程序执行两次,就会在操作系统中出现两个进程,所以我们可以同时运行一个软件,分别做不同的事情也不会混乱。
在采用多级反馈队列调度算法的系统中,调度算法的实施过程如下所述。
(1) 应设置多个就绪队列,并为各个队列赋予不同的优先级。第一个队列的优先级最高,第二个队列次之,
其余各队列的优先权逐个降低。该算法赋予各个队列中进程执行时间片的大小也各不相同,在优先权愈高的队列中,
为每个进程所规定的执行时间片就愈小。例如,第二个队列的时间片要比第一个队列的时间片长一倍,……,第i+1个
队列的时间片要比第i个队列的时间片长一倍。 (2) 当一个新进程进入内存后,首先将它放入第一队列的末尾,按FCFS原则排队等待调度。当轮到该进程执行时,
如它能在该时间片内完成,便可准备撤离系统;如果它在一个时间片结束时尚未完成,调度程序便将该进程转入第二队
列的末尾,再同样地按FCFS原则等待调度执行;如果它在第二队列中运行一个时间片后仍未完成,再依次将它放入第三
队列,……,如此下去,当一个长作业(进程)从第一队列依次降到第n队列后,在第n 队列便采取按时间片轮转的方式运
行。 (3) 仅当第一队列空闲时,调度程序才调度第二队列中的进程运行;仅当第1~(i-1)队列均空时,才会调度第i队列中
的进程运行。如果处理机正在第i队列中为某进程服务时,又有新进程进入优先权较高的队列(第1~(i-1)中的任何一个
队列),则此时新进程将抢占正在运行进程的处理机,即由调度程序把正在运行的进程放回到第i队列的末尾,把处理机分
配给新到的高优先权进程。
进程的并行与并发
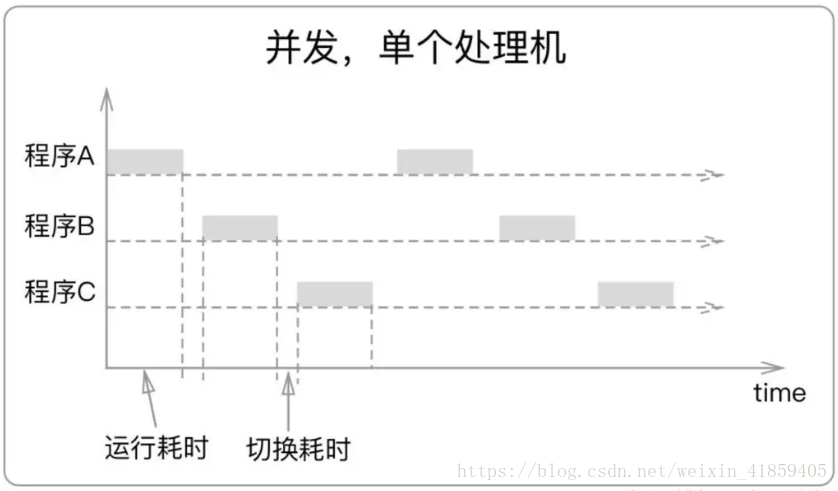
并行 :是指一个时间段内,有几个程序都在几个CPU上运行,任意一个时刻点上,有多个程序在同时运行,并且多道程序之间互不干扰。(资源够用,比如三个线程,四核的CPU )

并发 : 是指一个时间段内,有几个程序都在同一个CPU上运行,但任意一个时刻点上只有一个程序在处理机上运行,并发是指资源有限的情况下,两者交替轮流使用资源。
区别:
并行是从微观上,也就是在一个精确的时间片刻,有不同的程序在执行,这就要求必须有多个处理器。
并发是从宏观上,在一个时间段上可以看出是同时执行的,比如一个服务器同时处理多个session。
同步阻塞与非阻塞

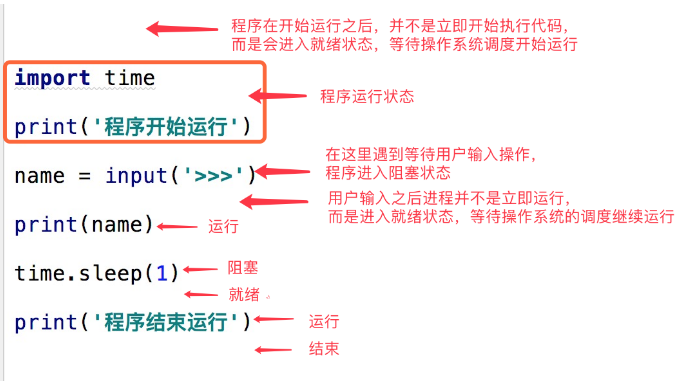
在了解其他概念之前,我们首先要了解进程的几个状态。在程序运行的过程中,由于被操作系统的调度算法控制,程序会进入几个状态:就绪,运行和阻塞。
(1)就绪(Ready)状态
当进程已分配到除CPU以外的所有必要的资源,只要获得处理机便可立即执行,这时的进程状态称为就绪状态。
(2)执行/运行(Running)状态当进程已获得处理机,其程序正在处理机上执行,此时的进程状态称为执行状态。
(3)阻塞(Blocked)状态正在执行的进程,由于等待某个事件发生而无法执行时,便放弃处理机而处于阻塞状态。引起进程阻塞的事件可有多种,例如,等待I/O完成、申请缓冲区不能满足、等待信件(信号)等。
process模块介绍
process模块是一个创建进程的模块,借助这个模块,就可以完成进程的创建。
Process([group [, target [, name [, args [, kwargs]]]]]),由该类实例化得到的对象,表示一个子进程中的任务(尚未启动)
强调:
1. 需要使用关键字的方式来指定参数
2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号
参数介绍:
1 group参数未使用,值始终为None
2 target表示调用对象,即子进程要执行的任务
3 args表示调用对象的位置参数元组,args=(1,2,'zhang',)
4 kwargs表示调用对象的字典,kwargs={'name':'zhang','age':18}
5 name为子进程的名称
1 p.start():启动进程,并调用该子进程中的p.run() 2 p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法 3 p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。 如果p还保存了一个锁那么也将不会被释放,进而导致死锁 4 p.is_alive():如果p仍然运行,返回True 5 p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是, p.join只能join住start开启的进程,而不能join住run开启的进程
1 p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自
己的新进程,必须在p.start()之前设置 2 p.name:进程的名称 3 p.pid:进程的pid 4 p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可) 5 p.authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性
,这类连接只有在具有相同的身份验证键时才能成功(了解即可)
在Windows操作系统中由于没有fork(linux操作系统中创建进程的机制),在创建子进程的时候会自动 import 启动它的这个文件,而在 import 的时
候又执行了整个文件。因此如果将process()直接写在文件中就会无限递归创建子进程报错。所以必须把创建子进程的部分使用if __name__ ==‘__main__’ 判断
保护起来,import 的时候 ,就不会递归运行了。
multiprocessing模块创建进程的方式1:
from multiprocessing import Process import time def test(name): print('你是叫%s是吧'%name) print("这是子进程") if __name__ == '__main__': p=Process(target=test,args=('xiaohong',)) #创建一个进程对象 p.start() #告诉操作系统帮你创建一个进程,至于什么时候创建,怎么创,由操作系统随机决定 #time.sleep(0.1) print('我是....') ''' 为何先运行start下面的print,再运行子进程? 因为在运行到start()时,会在内存中申请一块空间,然后运行.py文件,将代码丢到内存空间里面,这时子进程才创建好, 这时创建进程的时间远远大于执行start下面print代码的时间,顾先打印“我是子进程” 进程与进程之间数据是隔离的,无法直接交互,可以通过某些技术实现间接交互。 如果在start下方加上睡眠时间,则子进程先启动,0.1秒的时间足够操作系统创建子进程,让CPU读取子进程中动态运行的代码 ========= 我是.... 你是叫xiaohong是吧 这是子进程
multiprocessing模块创建进程的方式2:
'''
自定义的类体中必须要有run方法,才能创建出来一个子进程,其内部函数体代码才能运行,其他函数则运行不了
'''
import time from multiprocessing import Process class MyProcess(Process): def __init__(self,name): super().__init__() self.name=name def run(self): #必须是run方法,不然创建不了子进程,其他方法就只能是一个静态实体,并不能运行 print('%s is running'%self.name) time.sleep(3) print('%s is overing'%self.name) if __name__ == '__main__': p=MyProcess('zhenhua') p.start() print('一个py文件就是一个主进程') ===== 一个py文件就是一个主进程 zhenhua is running zhenhua is overing
进程的join方法:p.join()可以使主进程处于等待状态,待子进程运行完毕,再启动主进程。
进程中的join方法1:
在这里首先说明一下,Process在同时创建多个子进程的时候,同时各启动子进程,各子进程、主进程是各自隔离运行的,数据不共享,运行也互不干扰,至于操作系统先创建哪个子进程,由操作系统决定,所以不是按照我们书写代码的顺序去创建
from multiprocessing import Process import time def test(name): print('%s is running'%name) time.sleep(2) print('%s is overing'%name) if __name__ == '__main__': p=Process(target=test,args=('king',)) p1=Process(target=test,args=('queen',)) p2=Process(target=test,args=('hero',)) p.start() p1.start() p2.start() #CPU读取的速度肯快,操作系统相当于同时受到三个创建命令,三个子进程的创建顺序及创建时间是操作系统随机决定的, p.join() #join 可以让主进程暂停运行,等待子进程运行结束才继续运行 #p.join() print('啥时间运行我呢?') ====== queen is running king is running hero is running queen is overing king is overing hero is overing 啥时间运行我呢?
进程中的join方法2:
from multiprocessing import Process import time def test(name,i): print('%s is running'%name) time.sleep(2) print('%s is overing'%name) if __name__ == '__main__': for i in range(3): p=Process(target=test,args=('进程%s'%i,i)) p.start() p.join() #join 可以让主进程暂停运行,等待子进程运行结束才继续运行 print('啥时间运行我呢?') ======== 进程0 is running 进程0 is overing 啥时间运行我呢? 进程1 is running 进程1 is overing 啥时间运行我呢? 进程2 is running 进程2 is overing 啥时间运行我呢?
进程中的join方法3:
from multiprocessing import Process import time def test(name,i): print('%s is runing'%name) time.sleep(i) print('%s is overing'%name) if __name__ == '__main__': start = time.time() p_list=[] for i in range(1,4): p=Process(target=test,args=('子进程%s'%i,i )) p_list.append(p) p.start() for p in p_list: p.join() print('主', (time.time() - start)) ===== 子进程3 is runing 子进程1 is runing 子进程2 is runing 子进程1 is overing 子进程2 is overing 子进程3 is overing 主 3.1881821155548096
各进程之间启动是隔离的
from multiprocessing import Process ''' ''' money=100 def test(): global money money=888 if __name__ == '__main__': p=Process(target=test) p.start() p.join() print(money) ''' 通过添加join让子进程先运行结束,再继续运行父进程,发现money的值还 是100,global并没有修改父进程中的money,而是修改自己内存中的money ''' ===== 100
from multiprocessing import Process,current_process import time import os def func(i): print(f'子进程{i}的父进程进程号:{os.getppid()},子进程{i}的进程号是:{current_process().pid}') time.sleep(2) if __name__ == '__main__': for i in range(1,5): p = Process(target=func,args=(i,)) p.start() # p.join() # p.terminate() # 截断进程,其上不能再用join()方法,这样已经达到让子进程先运行的效果了,就无法用terminate阻断子进程了。 # print(p.is_alive()) print(f'主进程进程号是:{current_process().pid},主进程的父进程是{os.getppid()}') ''' 主进程进程号是:6964,主进程的父进程是2944 子进程2的父进程进程号:6964,子进程2的进程号是:5872 子进程3的父进程进程号:6964,子进程3的进程号是:6772 子进程4的父进程进程号:6964,子进程4的进程号是:1836 子进程1的父进程进程号:6964,子进程1的进程号是:6656 ''' 说明:进程的创建需要由操作系统来决定,创建进程需要需要重新开辟内存空间,把要运行的代码复制进去,
把运行过程中产生的名字放到名称空间,消耗资源;每开辟一个进程,就要开辟一块新的内存空间,开辟进
程的的所需时间远远大于主进程(一个.py文件中的代码)代码运行时间,所以,永远先运行的都是主进程
中的代码,除非使用join或者设置睡眠时间;创建的歌子进程之间以及主进程之间都是隔离的,互补交涉,
所以是并发运行的,运行时间2s多一点。
进程对象及其他方法:
current_process.pid()查看当前(子/主)进程号
os.getpid()查看当前(子/主)进程号
os.getppid()查看当前进程的上一级进程号
from multiprocessing import Process,current_process import time import os def func(i): print(f'子进程{i}的父进程进程号:{os.getppid()},子进程{i}的进程号是:{current_process().pid}') time.sleep(60) if __name__ == '__main__': for i in range(1,5): p = Process(target=func,args=(i,)) p.start() print(f'主进程进程号是:{current_process().pid},主进程的父进程是{os.getppid()}') ''' 主进程进程号是:5816,主进程的父进程是2944 子进程3的父进程进程号:5816,子进程3的进程号是:4020 子进程4的父进程进程号:5816,子进程4的进程号是:5204 子进程1的父进程进程号:5816,子进程1的进程号是:6148 子进程2的父进程进程号:5816,子进程2的进程号是:6316 ''' ''' 不管是主进程还是子进程,或是子进程的父进程的进程号都是运行Python解释器(进程),主进程(Python解释器)的父进程是pycharm
僵尸进程
子进程是由主进程创建的,主进程先死,子进程死了之后所占用的PID及其他资源没有被主进程回收,这个子进程就步入了僵尸进程;所有的进程最终都会步入到僵尸进程。
僵尸进程带来的缺点:操作系统所给的进程号是有限的,如果僵尸进程过多,将导致过多的PID被占用(没有回收),导致后期再启程序会受到阻碍。
父进程回收子进程资源的两种方式:
1)使用join方法,让子进程先死,这样主进程就可以回收子进程的进程号;听说调用一个叫wait的方法。
2)父进程正常死亡(父进程等子进程死亡自己也死了)
孤儿进程:子进程没死,父进程意外死亡;
针对Linux会有儿童福利院(init),如果父进程意外死亡,他们所创建的子进程都会被福利院收养。孤儿进程是无害的,因为他的进程号会被福利院回收。
from multiprocessing import Process,current_process import os import time def test(name): print('%s is running'%name,current_process().pid,'父进程PID:%s'%os.getppid()) #查看子进程号 time.sleep(3) print('%s is overing'%name) if __name__ == '__main__': p=Process(target=test,args=('zhang',)) #args括号内逗号必须要加上,不然会报错 p.start() ''' p.terminate() #杀死进程,告诉操作系统,至于操作系统什么时候杀由他决定, 但是代码执行的速度比操作系统反应快,所以很有可能,在进程还没杀死之前代码运行结束, is_live的返回值是True,我们可以通过在terminate之后加上time.sleep()稍微睡眠一下, ''' p.terminate() time.sleep(0.1) print(p.is_alive() ) #判断进程是否被杀死,返回的是bool值TRUE、False print('主进程号:%s'%current_process().pid,'主主进程PID:%s'%os.getppid()) #查看主进程号
========
False
主进程号:7332 主主进程PID:3924
守护进程:其本质就是一个子进程“”,该子进程的生命周期<=被守护进程的生命周期,只要主进程一旦结束,子进程无论有没有结束,都要跟着一起死。
#守护进程: 本质就是一个"子进程",该"子进程"的生命周期<=被守护进程的生命周期 from multiprocessing import Process import time def task(name): print('老太监%s活着....' %name) time.sleep(3) print('老太监%s正常死亡....' %name) if __name__ == '__main__': p=Process(target=task,args=('刘清政',)) p.daemon=True #守护进程要在start之前设置,告诉操作系统该进程是守护进程;在start之后设置就会报错 p.start() time.sleep(1) print('皇上:zhang正在死...') ======= 老太监曹活着.... 皇上:zhang正在死...
互斥锁:
当多个进程操作同一份数据的时候 会造成数据的错乱,这个时候必须加锁处理,这样将并发变成串行,虽然降低了效率但是提高了数据的安全,
注意:
1.锁不要轻易使用 容易造成死锁现象
2.只在处理数据的部分加锁 不要在全局加锁
3.锁必须在主进程中产生 交给子进程去使用
以下依抢票为例:
进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端,是没有问题的,
而共享带来的是竞争,竞争带来的结果就是错乱,如何控制,就是加锁处理
'''
0.000几秒for循环就已经已经结束了,此时操作系统或许连一个进程都还没有创建,当第一个进程创建好之后
运行search函数,在睡眠一秒的时候,所有的进程都起来了,也都在这里睡眠,第一个人查看到余票还有1张,别的其他人查看余票也是1张
之后都到了买票的环节,此时票数是1,大家都对字典的一进行修改,导致所有人都买票成功,但实际只有一张票
这里使用互斥锁,将这种并发问题变成串行来解决,在一个人在做操作的时候其他人都不能做操作,其他人做操作是基于前一个人做完操作之后再继续
互斥锁把并发(并发效率高于串行)变成串行,牺牲效率,但保证数据安全了
方法一:使用join,这种方法,一次只能启动一个进程,只有进程1启动了,进程1 抢票成功,这样数据安全了,但是永远只有进程1
抢票成功,也是不合理的。
方法二:导入lock
'''
import time ,json,random from multiprocessing import Process,Lock def search(name): with open(r'xxx.json','rt',encoding='utf-8')as f: dic=json.load(f) time.sleep(1) print('%s查询余票为%s'%(name,dic['count'])) def buy(name): with open(r'xxx.json','rt',encoding='utf_8') as f: dic=json.load(f) if dic['count']>0: dic['count']-=1 time.sleep(random.randint(1, 2)) with open(r'xxx.json', 'wt', encoding='utf-8')as f: json.dump(dic, f) print('%s购票成功' % name) else: print('余票已经没了!') def common(name,mutex): search(name)#这里应该变成并发,枷锁之后,好多人都阻塞到这里了 mutex.acquire() #获取锁,且同一时间只有一人获得锁 buy(name) #这里应该变成串行 mutex.release() #释放锁,接下来的人继续抢锁 if __name__ == '__main__': mutex=Lock() for i in range(10): p=Process(target=common,args=('路人%s'%i,mutex)) p.start() # p.join() ====== 路人3查询余票为5 路人1查询余票为5 路人0查询余票为5 路人2查询余票为5 路人7查询余票为5 路人4查询余票为5 路人9查询余票为5 路人5查询余票为5 路人6查询余票为5 路人8查询余票为5 路人3购票成功 路人1购票成功 路人0购票成功 路人2购票成功 路人7购票成功 余票已经没了! 余票已经没了! 余票已经没了! 余票已经没了! 余票已经没了!
#加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行的修改,没错,速度是慢了,但牺牲了速度却保证了数据安全。 虽然可以用文件共享数据实现进程间通信,但问题是: 1.效率低(共享数据基于文件,而文件是硬盘上的数据) 2.需要自己加锁处理 #因此我们最好找寻一种解决方案能够兼顾:1、效率高(多个进程共享一块内存的数据)2、帮我们处理好锁问题。这就是mutiprocessing模块为我们提供的基于消息的IPC通信机制:队列和管道。 1 队列和管道都是将数据存放于内存中 2 队列又是基于(管道+锁)实现的,可以让我们从复杂的锁问题中解脱出来, 我们应该尽量避免使用共享数据,尽可能使用消息传递和队列,避免处理复杂的同步和锁问题,而且在进程数目增多时,往往可以获得更好的可获展性。