核心概念
在讨论NSQ如何在实践中使用前,先理解NSQ队列的架构原理是非常值得的。它的设计很简单,可以通过几个核心概念来理解。
Topic ——一个topic就是程序发布消息的一个逻辑键,当程序第一次发布消息时就会创建topic。
Channels ——channel组与消费者相关,是消费者之间的负载均衡,channel在某种意义上来说是一个“队列”。每当一个发布者发送一条消息到一个topic,消息会被复制到所有消费者连接的channel上,消费者通过这个特殊的channel读取消息,实际上,在消费者第一次订阅时就会创建channel。
Channel会将消息进行排列,如果没有消费者读取消息,消息首先会在内存中排队,当量太大时就会被保存到磁盘中。
Message s——消息构成了我们数据流的中坚力量,消费者可以选择结束消息,表明它们正在被正常处理,或者重新将他们排队待到后面再进行处理。每个消息包含传递尝试的次数,当消息传递超过一定的阀值次数时,我们应该放弃这些消息,或者作为额外消息进行处理。
NSQ在操作期间同样运行着两个程序:
Nsqd ——nsqd守护进程是NSQ的核心部分,它是一个单独的监听某个端口进来的消息的二进制程序。每个nsqd节点都独立运行,不共享任何状态。当一个节点启动时,它向一组nsqlookupd节点进行注册操作,并将保存在此节点上的topic和channel进行广播。
客户端可以发布消息到nsqd守护进程上,或者从nsqd守护进程上读取消息。通常,消息发布者会向一个单一的local nsqd发布消息,消费者从连接了的一组nsqd节点的topic上远程读取消息。如果你不关心动态添加节点功能,你可以直接运行standalone模式。
Nsqlookupd ——nsqlookupd服务器像consul或etcd那样工作,只是它被设计得没有协调和强一致性能力。每个nsqlookupd都作为nsqd节点注册信息的短暂数据存储区。消费者连接这些节点去检测需要从哪个nsqd节点上读取消息。
消息的生命周期
让我们观察一个关于nsq如何在实际中工作的更为详细的例子。
NSQ推荐通过他们相应的nsqd实例使用协同定位发布者,这意味着即使面对网络分区,消息也会被保存在本地,直到它们被一个消费者读取。更重要的是,发布者不必去发现其他的nsqd节点,他们总是可以向本地实例发布消息。
首先,一个发布者向它的本地nsqd发送消息,要做到这点,首先要先打开一个连接,然后发送一个包含topic和消息主体的发布命令,在这种情况下,我们将消息发布到事件topic上以分散到我们不同的worker中。
事件topic会复制这些消息并且在每一个连接topic的channel上进行排队,在我们的案例中,有三个channel,它们其中之一作为档案channel。消费者会获取这些消息并且上传到S3。
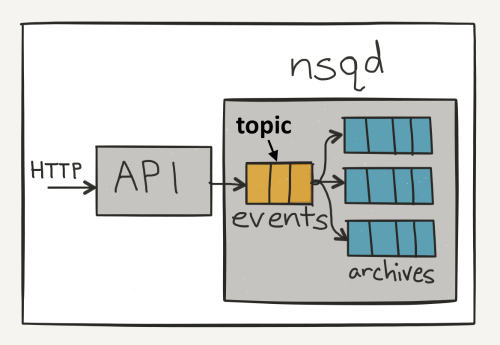
每个channel的消息都会进行排队,直到一个worker把他们消费,如果此队列超出了内存限制,消息将会被写入到磁盘中。
Nsqd节点首先会向nsqlookup广播他们的位置信息,一旦它们注册成功,worker将会从nsqlookup服务器节点上发现所有包含事件topic的nsqd节点。
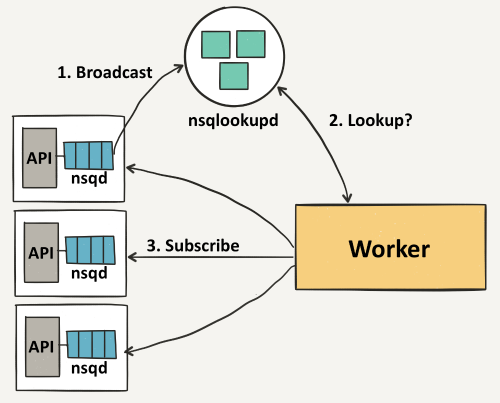
然后每个worker向每个nsqd主机进行订阅操作,用于表明worker已经准备好接受消息了。这里我们不需要一个完整的连通图,但我们必须要保证每个单独的nsqd实例拥有足够的消费者去消费它们的消息,否则channel会被队列堆着。
从客户端库代码中抽取一部分,这里是一个关于如何处理我们的消息的一段代码:
如果因为某些原因第三方发生故障了,我们可以处理这些故障,在这个代码片中,我们有三种处理逻辑:
1、如果超过了某个尝试次数阀值,我们就将消息丢弃。
2、如果消息已经被处理成功了,我们就结束消息。
3、如果发生了错误,我们将需要传递的消息重新进行排队。
正如你所看到的,NSQ队列的行为既简单又明确。
在我们的案例中,我们在丢弃消息之前将容忍MAX_DELIVERY_ATTEMPTS * BACKOFF_TIME分钟的故障。
在Segment系统中,我们统计消息尝试的次数、消息丢弃数、消息重新排队数等等,然后结束某些消息以保证我们有一个好的服务质量。如果消息丢弃数超过了我们设置的阀值,我们将在任何时候对服务发出警报。
在实践中
在生产环境中,我们几乎在我们所有的实例中运行nsqd守护程序,发布者之间协同定位。NSQ在实际生产中运行良好有几个原因:
简单的协议 ——如果你的队列已经有了一个很好的客户端库,这个不是一个很大的问题,但如果你现在的客户端库存在bug或者过时了,一个简单的协议就能体现出优势了。
NSQ有一个快速的二进制协议,通过短短的几天工作量就可以很简单地实现这些协议,我们还自己创建了我们的纯JS驱动(当时只存在coffeescript驱动),这个纯JS驱动运行的很稳定可靠。
运行简单 ——NSQ没有复杂的水印设置或JVM级别的配置,相反,你可以配置保存到内存中的消息的数量和消息最大值,如果队列被消息填满了,消息会被保存到磁盘上。
分布式 ——因为NSQ没有在守护程序之间共享信息,所以它从一开始就是为了分布式操作而生。个别的机器可以随便宕机随便启动而不会影响到系统的其余部分,消息发布者可以在本地发布,即使面对网络分区。
这种“分布式优先”的设计理念意味着NSQ基本上可以永远不断地扩展,需要更高的吞吐量?那就添加更多的nsqd吧。
唯一的共享状态就是保存在lookup节点上,甚至它们不需要全局视图,配置某些nsqd注册到某些lookup节点上这是很简单的配置,唯一关键的地方就是消费者可以通过lookup节点获取所有完整的节点集。
清晰的故障事件——NSQ在组件内建立了一套明确关于可能导致故障的的故障权衡机制,这对消息传递和恢复都有意义。
我是最少意外原则的坚定信仰者,尤其是当它涉及到分布式系统时。系统发生故障,我们接收它,但我们不可能会指望系统以意外的形式发生故障,你最终会忽略这些故障案例,因为你甚至都不打算考虑它们为什么会发生。
虽然它们可能不像Kafka系统那样提供严格的保证级别,但NSQ简单的操作使故障情况非常明显。
UNIX-y工具 ——NSQ是一个很好的通用型工具,所以NSQ附带了很多实用的程序,这些程序是多用途和可组合的。
除了TCP协议,NSQ提供一个简单的CURL的HTTP接口用于维护操作,它从CLI附带了二进制文件管道,用tail跟踪队列的尾部,从一个队列使用管道到另外一个队列,还有HTTP发布订阅。
甚至还有一个用于监控和暂停队列的管理面板,包括一个动态的计数器在上面。
丢失了什么?
正如我所提到的,简单并不是没有折衷:
没有复制 ——不像其他的队列组件,NSQ并没有提供任何形式的复制和集群,也正是这点让它能够如此简单地运行,但它确实对于一些高保证性高可靠性的消息发布没有足够的保证。
我们可以通过降低文件同步的时间来部分避免,只需通过一个标志配置,通过EBS支持我们的队列。但是这样仍然存在一个消息被发布后马上死亡,丢失了有效的写入的情况。
基本消息路由 ——在NSQ中,topic和channel几乎是你所有能获得到的东西,没有关于路由和基于key的亲和力的观念。我们很乐意为各种用例提供支持,无论是根据条件去筛选消息,还是根据条件路由到某些节点上。取而代之的是,我们最终建立了路由worker,它们处于队列之间,扮演一个聪明的直通滤波器。
没有严格的顺序 ——虽然Kafka由一个有序的日志构成,但NSQ不是。消息可以在任何时间以任何顺序进入队列。在我们使用的案例中,这通常没有关系,因为所有的数据都被加上了时间戳,但它并不适合需要严格顺序的情况。
无数据重复删除功能 ——Aphyr已经在他的文章中广泛探讨了基于超时系统的危险性。NSQ同样也调入了这个陷阱,它使用了心跳检测机制去测试消费者是否存活还是死亡。我们之前已经写过关于很多原因会导致我们的worker无法完成心跳检测,所以在worker中必须有一个单独的步骤确保幂等性。
简单的工作原理
正如你所看到的,后面看到的所有好处的基本核心就是简单性,NSQ是一个简单的队列,这意味着它很容易进行故障推理和很容易发现bug。消费者可以自行处理故障事件而不会影响系统剩下的其余部分。
事实上,简单性是我们决定使用NSQ的首要因素,这方便与我们的许多其他软件一起维护,通过引入队列使我们得到了堪称完美的表现,通过队列甚至让我们增加了几个数量级的吞吐量。
今天,我们面临一个更加复杂的未来,我们越来越多的worker需要一套严格可靠性和顺序性保障,这已经超过了NSQ提供的简单功能。
我们计划在其他基础设施中用Kafka替换NSQ,在生产上从JVM中运行可以获取更多的好处。关于Kafka我们有一个明确的权衡,我们自己必须肩负起更多负责的运营。另一方面,它拥有一个可复制的、有序的日志可以提供给我们更好的服务。
但对于其他适合NSQ的worker,它为我们服务的相当好,我们期待着继续巩固它的坚实的基础。